
深度解析:Pulsar的消息存储机制和Bookie的GC机制原理


导读
Apache Pulsar是一个多租户、高性能的服务间消息传输解决方案,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。腾讯数据平台部MQ团队对Pulsar做了深入调研以及大量的性能和稳定性方面优化,目前已经在TDbank落地上线。本文是Pulsar技术系列中的一篇,主要简单梳理了Pulsar消息存储与BookKeeper存储文件的清理机制。其中,BookKeeper可以理解为一个NoSQL的存储系统,默认使用RockDB存储索引数据。
作者介绍
鲍明宇
腾讯TEG数据平台部高级工程师
Apache Pulsar Contributor
热衷于开源技术,在消息队列领域有丰富经验,目前致力于Pulsar的落地和推广

Pulsar消息存储
Pulsar的消息存储在BookKeeper中,BookKeeper是一个胖客户的系统,客户端部分称为BookKeeper,服务器端集群中的每个存储节点称为bookie。Pulsar系统的broker作为BookKeeper存储系统的客户端,通过BookKeeper提供的客户端SDK将Pulsar的消息存储到bookies集群中。
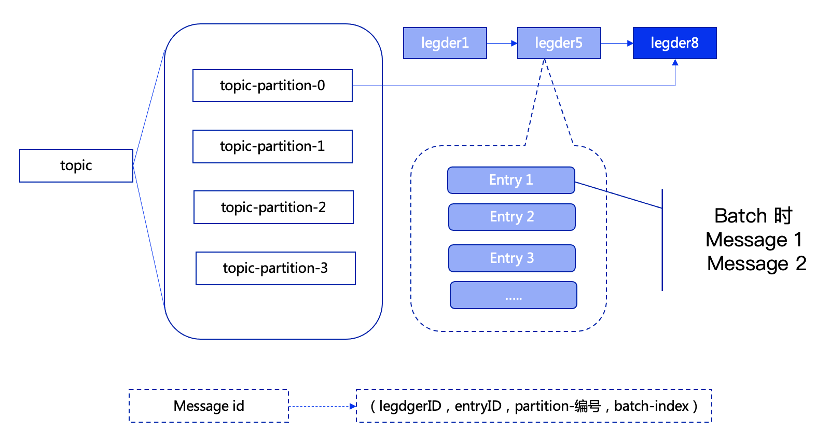
Pulsar中的每个topic的每个分区(非分区topic,可以按照分区0理解,分区topic的编号是从0开始的),会对应一系列的ledger,而每个ledger只会存储对应分区下的消息。对于每个分区同时只会有一个ledger处于open即可写状态。
Pulsar在生产消息,存储消息时,会先找到当前分区使用的ledger ,然后生成当前消息对应的entry ID,entry ID在同一个ledger内是递增的。非批量生产的情况(producer 端可以配置这个参数,默认是批量的),一个entry 中包含一条消息。批量方式下,一个entry可能包含多条消息。而bookie中只会按照entry维度进行写入、查找、获取。
因此,每个Pulsar下的消息的msgID 需要有四部分组成(老版本由三部分组成),分别为(ledgerID,entryID,partition-index,batch-index),其中,partition-index 在非分区topic的时候为-1,batch-index在非批量消息的时候为-1。
每个ledger,当存在的时长或保存的entry个数超过阈值后会进行切换,同一个partition下的,新的消息会存储到下一个ledger中。Ledger只是一个逻辑概念,是数据的一种逻辑组装维度,并没有对应的实体。
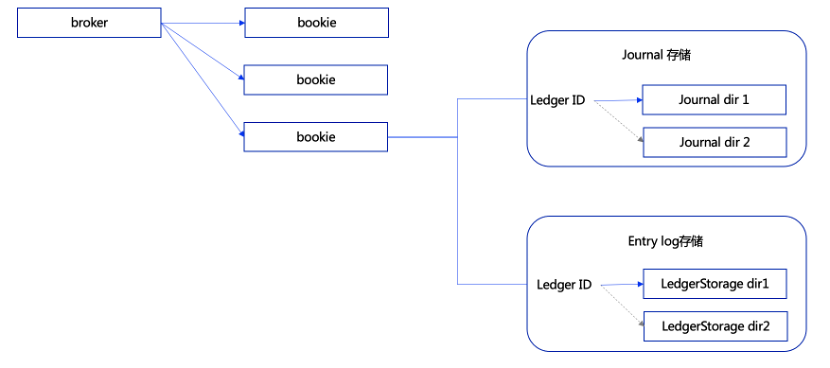
BookKeeper集群中的每个bookie 节点收到消息后,数据会分三部分进行存储处理,分别为:journal 文件、entryLog 文件、索引文件。
其中journal文件,entry数据是按照wal方式写入的到journal文件中,每个journal文件有大小限制,当超过单个文件大小限制的时候会切换到下一个文件继续写,因为journal文件是实时刷盘的,所以为了提高性能,避免相互之间的读写IO相互影响,建议存储目录与存储entrylog的目录区分开,并且给每个journal文件的存储目录单独挂载一块硬盘(建议使用ssd硬盘)。journal文件只会保存保存几个,超过配置个数的文件将会被删除。entry 存储到journal文件完全是随机的,先到先写入,journal文件是为了保证消息不丢失而设计的。
如下图所示,每个bookie收到增加entry的请求后,会根据ledger id映射到存储到那个journal目录和entry log目录,entry数据会存储在对应的目录下。目前bookie不支持在运行过程中变更存储目录(使用过程中,增加或减少目录会导致部分的数据查找不到)。
如下图所示,bookie收到entry写入请求后,写入journal文件的同时,也会保存到write cache中,write cache分为两部分,一部分是正在写入的write cache, 一部分是正在正在刷盘的部分,两部分交替使用。
write cache中有索引数据结构,可以通过索引查找到对应的entry,write cache中的索引是内存级别的,基于bookie自己定义的ConcurrentLongLongPairHashMap结构实现。
另外,每个entorylog的存储目录,会对应一个SingleDirectoryDbLedgerStorage类实例对象,而每个SingleDirectoryDbLedgerStorage对象里面会有一个基于RockDB实现的索引结构,通过这个索引可以快速的查到每个entry存储在哪个entrylog文件中。每个write cache在增加entry的时候会进行排序处理,在同一个write cache,同一个ledger下的数据是相邻有序的,这样在write cache中的数据flush到entrylog文件时,使得写入到entrylog文件中的数据是局部有序的,这样的设计能够极大的提高后续的读取效率。
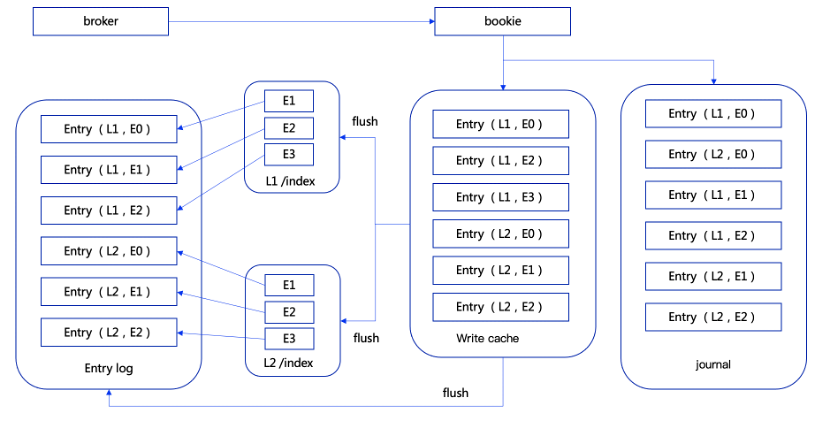
SingleDirectoryDbLedgerStorage中的索引数据也会随着entry的刷盘而刷盘到索引文件中。在bookie宕机重启时,可以通过journal文件和entry log文件还原数据,保证数据不丢失。
Pulsar consumer 在消费数据的时候,做了多层的缓存加速处理,如下图所示:
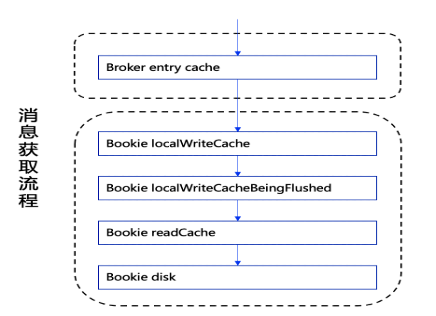
获取数据的顺序如下:
在broker端的entry cache中获取,如果没有在继续; 在bookie的write cache正在写的这部分中获取,如果没有则继续; 在bookie的write cache正在刷盘的这部分中获取,如果没有则继续; 从bookie的read cache中获取,如果没有则继续; 通过索引读取磁盘上的entry log文件。
上面每一步,如果能获取到数据,都会直接返回,跳过后面的步骤。如果是从磁盘文件中获取的数据,会在返回的时候将数据存储到read cache中,另外如果是读取磁盘的操作,会多读取一部分磁盘上的时候,因为存储的时候有局部有序的处理,获取相邻数据的概率非常大,这种处理的话会极大的提高后续获取数据的效率。
我们在使用的过程中,应尽量避免或减少出现消费过老数据即触发读取磁盘文件中的消息的场景,以免对整体系统的性能造成影响。
BookKeeper的GC机制
BookKeeper中的每个bookie都会周期的进行数据清理操作,默认15分钟检查处理一次,清理的主要流程如下
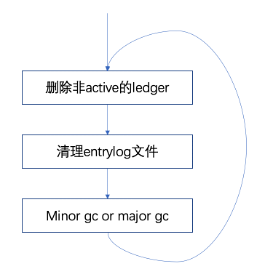
清理bookie存储的ledger id(bookie内存储的ledger id与zk上面存储的 ledger id做比较,如果zk上面没有则删除bookie中存储的ledger id); 统计每个entry log中存活的entry占比,当前entry log 存活的ledger个数为0时删除这个entry log; 根据entry log的元数据信息,清理entry log 文件(当entry log包含的所有ledger id全部失效时删除); 压缩entry log文件 ,分别在当前entry log文件下存活的entry比例在0.5-默认周期1天(major gc) 或比例0.2-默认周期1个小时(minor gc) 的时候,Compaction entry log文件,将老的文件中存活的entry转移新的文件中,然后将老的entry log文件删除,单次的GC如果处理的entry log文件比较大的时候可能耗时比较长。
通过上面的流程,我们可以了解bookie在清理entrylog文件时的大体流程。
需要特别说明的是,ledger是否是可以删除的,完全是客户端的触发的,在Pulsar中是broker触发的。
broker端有周期的处理线程(默认2分钟),清理已经消费过的消息所在的ledger机制,获取topic中包含的cursor最后确认的消息,将这个topic包含的ledger列表中,在这个id之前的(注意不包含当前的ledger id)全部删除(包括zk中的元数据,同时通知bookie删除对应的ledger)。
运营中遇到的问题分析
在运用的过程中我们多次遇到了bookie磁盘空间不足的场景,bookie中存储了大量的entry log文件。比较典型的原因主要有如下两个。
原因一:
生产消息过于分散,例如,举个极端的场景,1w个topic,每个topic生产一条,1w个topic顺序生产。这样每个topic 对应的ledger短时间内不会因为时长或者存储大小进行切换,active状态的ledger id分散在大量的entry log文件中。这些entry log文件是不能删除或者及时压缩的。
如果遇到这种场景,可以通过重启,强制ledger进行切换进行处理。当然如果这个时候消费进行没有跟上,消费的last ack位置所在的ledger也是处于active状态的,不能进行删除。
原因二:
GC时间过程,如果现存的enrylog文件比较多,且大量符合minor或major gc阈值,这样,单次的minor gc或者major gc时间过长,在这段时间内是不能清理过期的entry log文件。
这是由于单次清理流程的顺序执行导致的,只有上次一轮执行完,才会执行下一次。目前,这块也在提优化流程,避免子流程执行实现过长,对整体产生影响。
小结
本文首先,介绍了Pulsar消息的存储组织形式,存储流程和消息的获取过程。其次,对单个bookie的GC流程做了详尽的说明。在Pulsar的使用过程中,应该尽量避免消费过旧的历史数据即需要读取磁盘获取数据的场景。
在运维bookie的过程中,是不能在运行过程中调整存储目录的个数的,在部署时需要对容量进行充分的评估。如果需要在运营的过程中进行调整时,需要对单个的bookie节点进行扩缩容处理。
往期
推荐
《200 行代码告诉你 TDMQ 中 Pulsar 广播如何实现》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!
