
看数据模型界两大长老的神仙打架
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

如果有人问起,“L,对于编程,你最后悔的一件事情是什么?”我只能回答:“数据结构”。
故事,要从我最初学编程的动机,开始说起。
踏入编程这个行当,我是从Visual FoxPro 开始的。
上大学那会,本科学农,农学是养花养草的专业,和计算机一点儿关系没有。但学校是有规定,大一大二要通过计算机二级。被教育了12年,别的本事没有,要说证书这事,那是相当热衷。所以早早就把 VFP 学好了,自然考试也轻松通过。
通过也就通过了,也没留下特别的情感。转机出现在大二,那年学统计,其中有各种公式,各种参数,纷繁复杂,作业题不难,但很多推演特别麻烦。那天做完统计学作业,正在图书馆发呆,过了2,4,6级,发现人生有些空虚,接下来还有2年半的时间要挥霍,不禁要焦虑,接下来该做什么,才能证明自己?
人生的苦恼,逃不过三大问题,我是谁,我从哪里来,要到哪里去
眼瞅着瞅着,就瞄到了作业题上去。这些可恶的参数,每次都要手写,一写就是一个长本,跟写舞台剧台词一样。那有没有好一点的方法来求解最终的答案呢?
就跟棒球突然击中村上春树文艺细胞一般,慵懒的午觉,加上一口激爽的冰咖,瞬间蛰醒了已充分回血的大脑。忽然就想到了VFP中的表单,想到了类里面的变量,这些变量不就是参数嘛,表单不就是每次作业题的草稿嘛。至于公式,那就是方法嘛。我把公式,参数,建成类,最终结果就让计算机程序去算。为什么我要用笔去推算呢?
慢慢的思路磨就出来,于是,说干就干,到机房,插上1.44MB的磁盘,一个下午,把指数平滑公式给写好了。接下来的作业,只要输入表单对应参数值,按下计算按钮,结果就出来了。
从此,作业变成了分析需求,编程成了我真正的作业。
你们看,我开始编程时,就在解决一些实际问题,将作业计算中的定量模型,抽象出K-V的数据模型,而计算公式则抽象出函数。
现在回首,我依然对广义的数据结构和算法抱着极高的敬畏。同时,我也庆幸,我掌握了解决信息领域的数据结构与算法,即关系型数据库的数据模型。
如果说,广义的数据结构,比如链表,平衡树和图等,是一切编程的基础,那么理解RDBMS的“数据结构”,比如范式,星型,雪花型,大宽表等,就是叱咤信息领域的基础。无论你如何努力,都不会精通,却可以解决无数实用的问题,带来极大的心理成就感和满足。
为方便大家直观地感受数据模型,在这儿出道题,比如对比双11,双12等前后价格波动,引起的销量变化。分享下,你会如何涉及表结构,来满足分析的需求。
要做好这类数据分析的建模工作,离不开讨论 Kimball 与 Inmon 的数据模型。两种截然不同的模型,带给项目的便利与挑战,也是大不同。
当然还有诸如 Data Vault 与 Anchor 模型等等
首先从架构说起
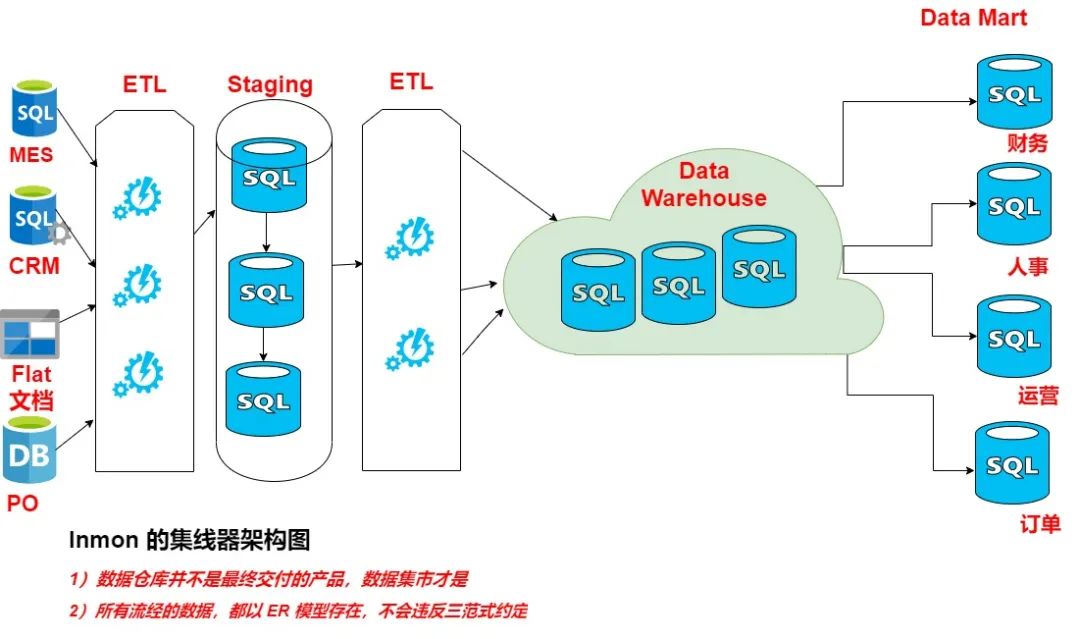
上图,是 Inmon 的集线器架构图。数据仓库,并不是 Inmon 理论的交付产品,它只是一个集企业所有关键实体、业务流程数据于一体的存储。面对各个部门自己的分析需求,数据仓库最终还会继续分流出各个业务需要的数据集市,所有单独的业务都从分配到的数据集市中抽取数据。
从这个架构图,很容易看出,数据仓库只是负责收集数据,类似集线器,最终还是要把数据分流出去。
Kimball 的架构就不一样了。如下图所示,他也有一个大的数据仓库,但少了数据集市的概念。

在Kimball的理论模型中,数据集市从来不是正规的交付物,而是ETL过程中自然产生的副产品。即ETL将业务数据集中抽到 Staging 时,会将数据按照实体,业务流程打包成一个ODS层(Operational Data Store),任何单个业务部门,完全可以从ODS中查询数据。功能上类似于 Inmon 的数据集市。
最终数据汇总到数据仓库时,天然就带有企业全局属性。只见树木不见森林的尴尬,就被化解了。好比,面临企业利润的下滑,我们就能从成本,订单量,单价上来做多维度分析,而不再是仅仅盯着订单量一个维度去看。
所以,Kimball 的理论,更多是数据从局部流向整体的策略,最终交付物,数据仓库就像是企业数据流总线,谁要谁取,不必切换多个数据库。
再对比数据模型的落地
曾经有位同事问我,为什么我们的表,设计了很多冗余字段,而不是严格按照三范式设计呢?其实答案就是 Kimball 的维度模型使然。在 Kimball 总线架构图中,我特意用星型模型标注了数据仓库的 schema.
很好看懂,中间一颗星,周围直联其他星星,有且只有一级联系。这就是 Kimball 数据模型的精髓所在。与 Inmon 最大的区别,也就在这里。Inmon 的数据模型都是ER模型,范式用到了极致。
我们来看 Kimball 的星型模型维度建模:

很直观,围绕着SalesOrder(销售订单)业务,假设有三个维度(即影响订单的三个因素,实际上远不止3个,300个都有,互联网甚至还有3000个)Employee, Time, Components,即人,货,时。
人的维度,还包括了人所在的部门,地址和职级;时间维度,算简单的一个,实际应用中,会有多个记账周期,时间略有复杂;货的维度,就是商品,有厂家,地址,厂长和商品本身的属性,大小,颜色等等。
这就是很多入门的同学迷糊的地方,为什么在一个表里,会有很多看似冗余的数据,为什么不按照三范式拆出来呢?这里有个特别重要的原理,那就是空间换时间。
当所有的属性都拿来做维度分析时,为了节省Join的时间,通常把这些维度属性预先计算好。即时查询分析,用GroupBy去随机分组统计数据,假如没有合适的索引,会非常慢。为了提高效率,我们只能把这些组合的统计与聚合,预先计算好,存起来。大部分的 OLAP 引擎,都是基础这个原理,比如SQL Server Cube, Kylin等。
Kimball 给这种数据模型,起了个名字,“星型模型”。作为最终的交付产品,是数据仓库的灵魂。
Kimball 理论也没有放弃数据集市,只不过他将数据集市放在ETL阶段实现了,用的是另外一种模型,叫做“雪花模型”。功能与 Inmon 的数据集市类似,实际上,数据模型也一致,就是标准的ER模型,即三范式结构。

人的维度上,只保留人本身的属性,比如性别,身高,年龄等,其他附属属性,比如地址,部门,职级,都分别存在不同的子表里面。其他两个维度也一样,自留属性与附加属性都分别存储。这样一个坏处,就是Join比较多,而且容易造成性能缓慢。
那么现实中,我们该用哪种理论来设计数据仓库的架构呢,用哪种数据模型来建模呢
现实世界没有银弹,一切取决于所在业务的复杂度。Kimball 理论显然更适合BI套件,但留下冗余数据处理的复杂;Inmon 解决了数据一致性问题,但性能又是老大难的问题。
顺便说下,阿里巴巴的大数据实践,在第三阶段,也采用了 Kimball 数据模型方法论。可见,即便是在互联网应用,数仓的众多模型也是通用的。具体参考这本书《大数据之路-阿里巴巴大数据实践》
往期精彩: