
最近特别火的contrastive learning是什么?
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020
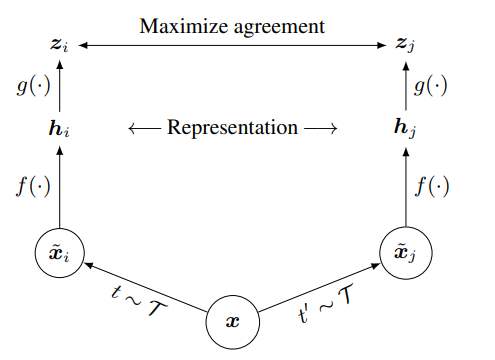
数据增广(data augmentation)$\tau$ (τ)。这个模块将数据进行变化,比如一张图片进行裁剪,颜色变化之类的操作,从而得到新的数据。这个部分是比较重要的,之后我们单独拿出来介绍。
数据编码(encoder)f(·)。这个部分就是模型,比如一个深度的神经网络。
投影首部(projection header)g(·)。这个部分是为了将两个编码的向量投影到共同的空间中进行对比学习。
对比损失函数(contrastive loss)。也就是图中的maximize agreement。
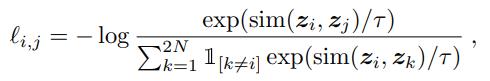

MoCo
Momentum Contrast for Unsupervised Visual Representation Learning, CVPR 2020


如果看一下文章中的伪代码,就会发现设计起来是这样子的思路:
首先初始化两个相同的模型;
拿出一组样本来生成数据增广样本;
计算损失函数;
将key分支的模型的update与query分支的模型分隔开,然后通过momentum的方式来更新key分支的模型;
将目前batch里的样本放到key 字典中 (enqueue/dequeue)
重复迭代。
CLEAR
CLEAR: Contrastive Learning for Sentence Representation, arxiv 2020
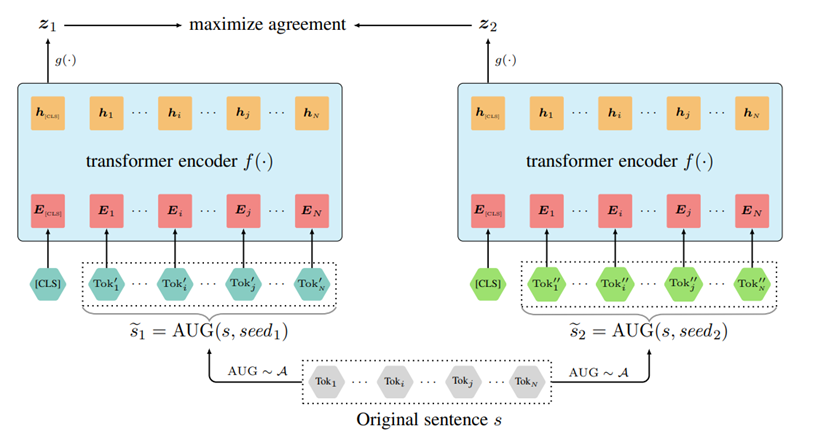
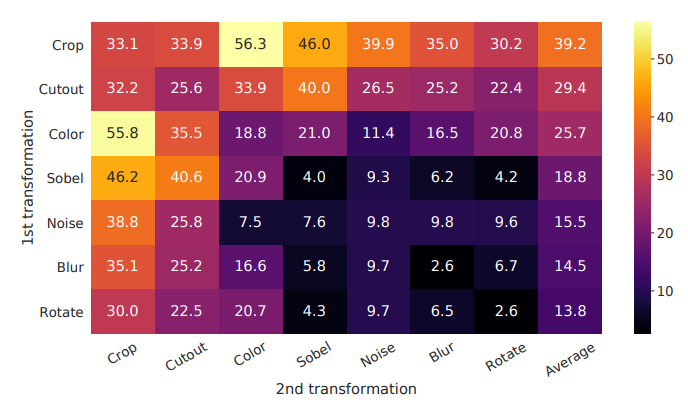
词语删除;
片段删除;
次序重排;
同义词替换。
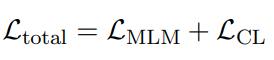
EDA
Wei, Jason, and Kai Zou. "EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks." EMNLP-IJCNLP. 2019.
同义词替换(Synonym Replacement)
随机插入
随机交换
随机删除
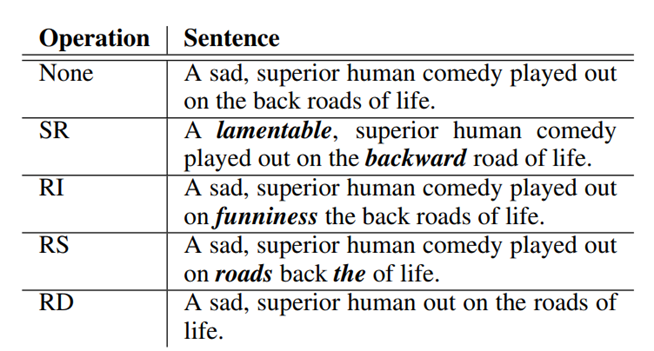

GraphCL
Graph Contrastive Learning with Augmentations (GraphCL), NIPS 2020
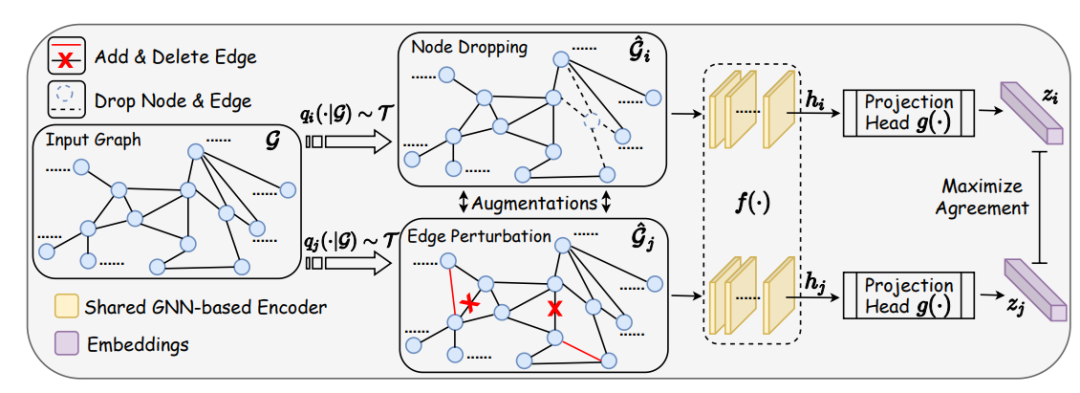
GCC
GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training, KDD 2020
Wu, Jiancan, et al. "Self-supervised Graph Learning for Recommendation." arXiv preprint arXiv:2010.10783 (2020).
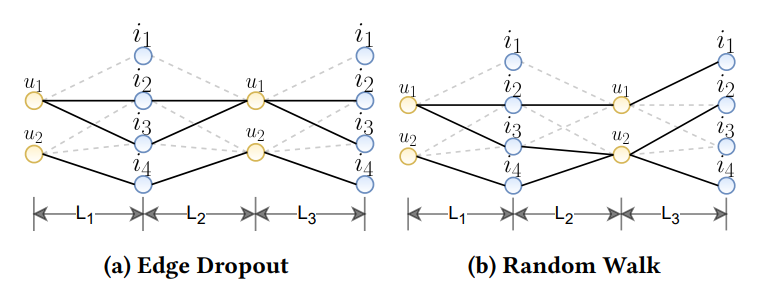
node drop
edge drop
random walk
Gao, Tianyu, Xingcheng Yao, and Danqi Chen. "SimCSE: Simple Contrastive Learning of Sentence Embeddings." arXiv preprint arXiv:2104.08821 (2021).
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论