
最近很火的 ClickHouse 是什么?
ClickHouse 是 Yandex(俄罗斯最大的搜索引擎)开源的一个用于实时数据分析的基于列存储的数据库,其处理数据的速度比传统方法快 100-1000 倍。
ClickHouse 的性能超过了目前市场上可比的面向列的 DBMS,每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。
# ClickHouse 是什么?
ClickHouse 是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
我们首先理清一些基础概念:
OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。
OLAP:是仓库型数据库,主要是读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果。
接着我们用图示,来理解一下列式数据库和行式数据库区别,在传统的行式数据库系统中(MySQL、Postgres 和 MS SQL Server),数据按如下顺序存储:
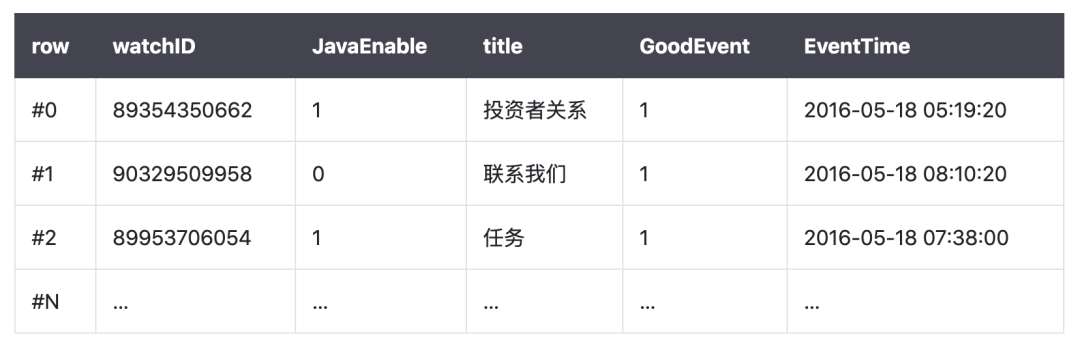
在列式数据库系统中(ClickHouse),数据按如下的顺序存储:
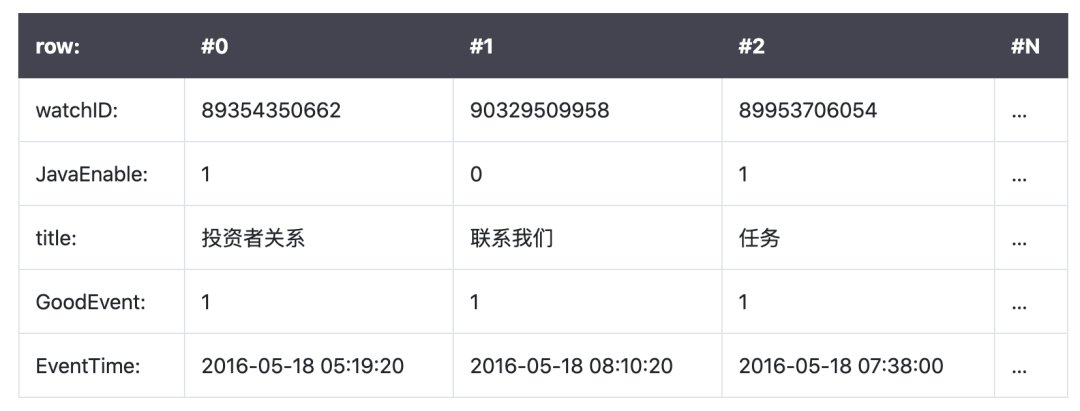
两者在存储方式上对比:

以上是 ClickHouse 基本介绍,更多可以查阅官方手册:
https://clickhouse.tech/docs/zh/# 业务问题
业务端现有存储在 MySQL 中,5000 万数据量的大表及两个辅表,单次联表查询开销在 3min+,执行效率极低。
经过索引优化、水平分表、逻辑优化,成效较低,因此决定借助 ClickHouse 来解决此问题。
最终通过优化,查询时间降低至 1s 内,查询效率提升 200 倍!希望通过本文,可以帮助大家快速掌握这一利器,并能在实践中少走弯路。
# ClickHouse 实践
①Mac 下的 Clickhouse 安装
我是通过 Docker 安装,也可以下载 CK 编译安装,相对麻烦一些。参考链接:
https://blog.csdn.net/qq_24993831/article/details/103715194②数据迁移:从 MySQL 到 ClickHouse
ClickHouse 支持 MySQL 大多数语法,迁移成本低,目前有五种迁移方案:
create table engin mysql,映射方案数据还是在 MySQL。
insert into select from,先建表,在导入。
create table as select from,建表同时导入。
csv 离线导入。
streamsets。
参考链接:
https://anjia0532.github.io/2019/07/17/mysql-to-clickhouse/CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = Mergetree AS SELECT * FROM mysql('host:port', 'db', 'database', 'user', 'password')③性能测试对比
性能测试对比如下图:

④数据同步方案
临时表如下:
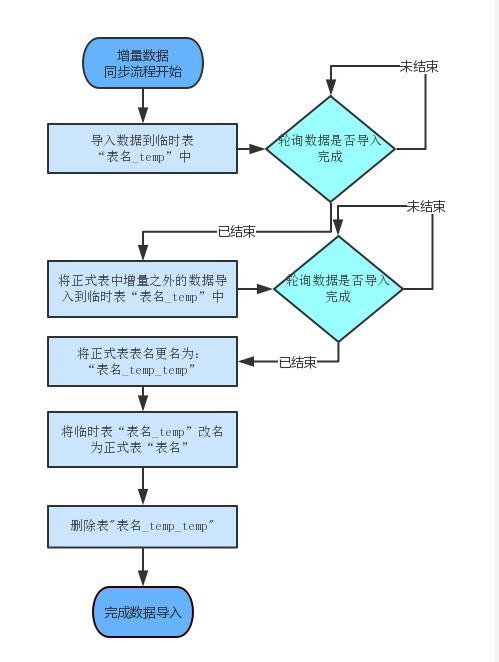
图片来源:携程
新建 Temp 中间表,将 MySQL 数据全量同步到 ClickHouse 内 Temp 表,再替换原 ClickHouse 中的表,适用数据量适度,增量和变量频繁的场景。
开源的同步软件推荐 Synch,如下图:
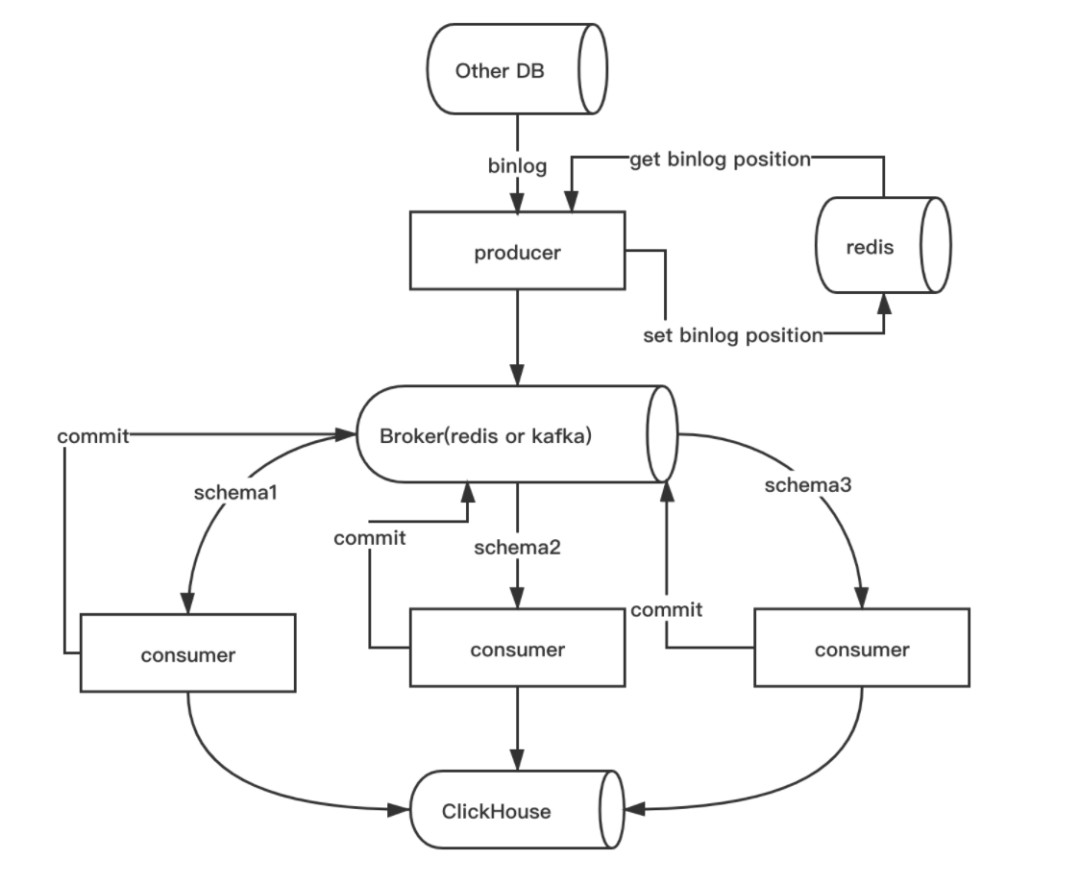
Synch 原理是通过 MySQL 的 Binlog 日志,获取 SQL 语句,再通过消息队列消费 Task。
⑤ClickHouse 为什么快?
有如下几点:
只需要读取要计算的列数据,而非行式的整行数据读取,降低 IO cost。
同列同类型,有十倍压缩提升,进一步降低 IO。
Clickhouse 根据不同存储场景,做个性化搜索算法。
# 遇到的坑
①ClickHouse 与 MySQL 数据类型差异性
用 MySQL 的语句查询,发现报错:

解决方案:LEFT JOIN B b ON toUInt32(h.id) = toUInt32(ec.post_id),中转一下,统一无符号类型关联
②删除或更新是异步执行,只保证最终一致性
查询 CK 手册发现,即便对数据一致性支持最好的 Mergetree,也只是保证最终一致性:

如果对数据一致性要求较高,推荐大家做全量同步来解决。
# 总结
通过 ClickHouse 实践,完美的解决了 MySQL 查询瓶颈,20 亿行以下数据量级查询,90% 都可以在 1s 内给到结果,随着数据量增加,ClickHouse 同样也支持集群,大家如果感兴趣,可以积极尝试!
作者:起个帅的名
来源:https://juejin.im/post/6863283398727860238