
【NLP】Contrastive Learning NLP Papers

来自 | 知乎
作者 | 光某人
地址 | https://zhuanlan.zhihu.com/p/363900943
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
具体知识请参阅我之前的文章:
https://zhuanlan.zhihu.com/p/346686467
这里的论文我会慢慢更新【最近组里活挺多的,慢慢来】
1.解决NMT的单词遗漏[acl2019]
论文标题:Reducing Word Omission Errors in Neural Machine Translation: A Contrastive Learning Approach
论文链接:aclweb.org/anthology/P1
1.0 问题
NMT系统容易省略基本单词,会减弱机器翻译的充分性。
由于神经网络缺乏可解释性,很难解释这些遗漏错误是如何发生的,也很难用逻辑规则的方式来消除它们。
所以本文采用对比学习的方法来显式地解决这个问题。
示例:
I love it so much that I cannot sleep well.  我太喜欢它 (了以至于 ) 我夜不能寐
我太喜欢它 (了以至于 ) 我夜不能寐
1.1 使用CL动机
适应性强:可以对所有NMT模型加入CL进行对比学习来微调缺省后句向量与原向量距离。
语言独立性强:方法是独立于语言的,可以应用于任何语言。
训练快:对比学习从一个预先训练的NMT模型开始,通常只有几百个步骤。
用对比学习的思想解决该问题,其基本思想仍然与对比学习的思想是一致的:
使NMT模型能够将更高的概率分配给真实(ground-truth)翻译,而将较低的概率分配给错误翻译。
根据真实翻译进行省略词数、改变词频和词性设计不同类型的负实例,进行数据增强。
1.2 如何使用CL
输入:并行训练集  ,包含已翻译好的句子对
,包含已翻译好的句子对
输出:无缺漏翻译的句子
用随机初始化获得D的最大似然估计

构建否定集

在
基础上用对比学习获得  上的
上的 
第一步,在平行语料库(1-2行)上使用最大似然估计(MLE)训练模型获得绝对空间向量。
在第二步中,通过省略ground-truth翻译中的单词来自动构建否定例(第3行)。
在第三步中,以估计最大似然值为起点,使用对比学习对模型进行微调。
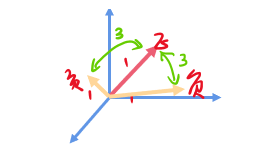
1.3 联合Loss
找到一组模型参数,使训练集进行正常翻译的对数似然最大化:

1.4 数据增强
基于并行语料库中的真实实例对构建负实例。

基于以下几种规则对数据构建负实例:
随意省略。
按单词频率省略。
按词性省略。
1.5 对比损失【Triplet Loss变形】
这里是N个不同负样本平均概率与1个正样本间的概率差要趋向于margin 。本文实验取N=1。

1.6 实验
文章定义了margin difference 来衡量margin的大小。

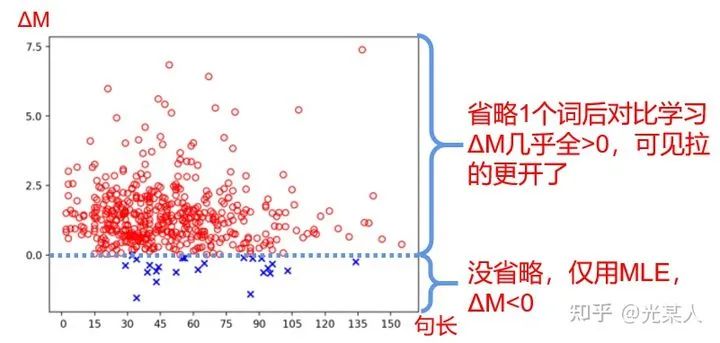
效果:
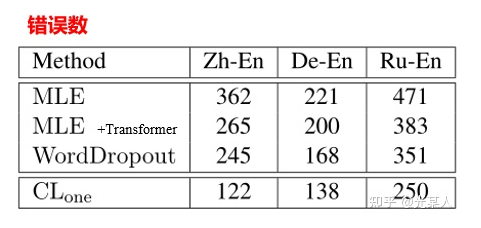
然后作者也对不同省略方法进行拆解比较其效果:
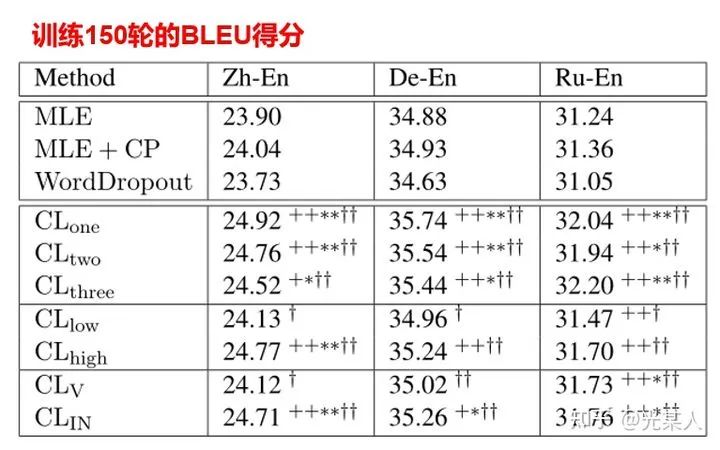
注:  指随机省略1,2,3个词进行对比学习。
指随机省略1,2,3个词进行对比学习。  指随机省略低频词,高频词。
指随机省略低频词,高频词。  指随机省略动词或介词。
指随机省略动词或介词。
首先,我们可以看到CL收敛还是很快的,而且,对于省略来说,随机省略一个词,省略高频词,省略介词,对比学习效果最好。
2. 常识推理的对比性自我监督学习
论文标题:Contrastive Self-Supervised Learning for Commonsense Reasoning
论文链接:aclweb.org/anthology/20
代码链接:github.com/SAP-samples/
2.0 问题
该文章提出了一种自监督的方法来解决指代消解(Pronoun Disambiguation)和 Winograd Schema Challenge 问题,减少目前监督方法对常识推理的限制 。
示例:
“它”指:
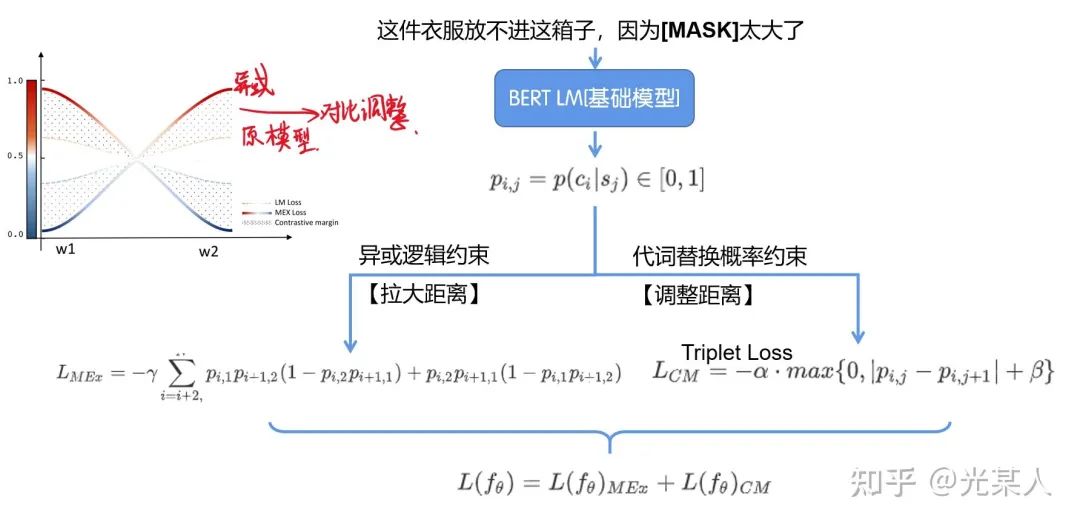
这件衣服放不进这箱子,因为它太大 了
A.衣服 B.箱子
这件衣服放不进这箱子,因为它太小 了
A.衣服 B.箱子
2.1 使用CL动机
训练快:对比学习能够较好的稳定优化和加快收敛速度。
自动化寻找差异:采用该方式进行正则化,用于寻求语言模型中个体候选概率的最大差异。
2.2 如何使用CL
2.2.1 互斥损失
该文章利用了与所谓的触发词相关的训练语料库的特征结构,它负责在代词消解中翻转答案,从而构造两两对比的辅助预测来实现这样的常识推理。
在上面的示例中,big,small充当触发词,这两个选项包含文中所有的实体,那么二者存在异或的关系,即要么A成立,要么B成立。考虑到触发词所建立的上下文,候选答案A在第一句中要么是对的,要么在第二句中是对的【另一句是错的】。
则有异或关系

所以对于  ,
,

从例子中可以看出,触发词产生了训练对的相互排斥关系。该方法的目标是将这种成对关系作为训练阶段的唯一监督信号。所以这里引入 互斥损失(Mutual Exclusive (MEx) loss),最大限度地提高这两个看似合理的候选项的相互排斥概率。
具体来说,给定一对训练句子,将要解决的代词从句子中屏蔽(mask)掉,并使用语言模型来预测这样的候选词中只有一个可以填充mask的位置,而填充互斥条件。
2.2.2 原始CL
因为假如原来是正确的指代,那么被交换的指代就是负例了,那么就采用Triplet Loss:

2.3 联合Loss
所以二者联合即可

2.4 整体结构
2.5 试验结果

往期精彩回顾
本站qq群851320808,加入微信群请扫码: