
本文约2000字,建议阅读8分钟
本文将介绍特征归因和反事实解释的基本方法。
基于高级机器学习的产品已经成为我们日常生活的一部分并且也存在于医疗保健等高级领域。理解基于ml的模型背后的如何决策是让用户获得对模型的信任、调试模型、发现偏差等等的关键。解释人工智能黑盒模型是一个巨大的挑战。在这篇文章中,我将介绍特征归因和反事实解释的基本方法。稍后,您将了解两者之间的关系。本文基于Microsoft[1]在2020年发表的一篇论文。基本的解释方法
基于归因的解释是提供对特征的评分或排名的方法,将每个特征的重要性传达给模型的输出。例如:LIME:Local Interpretable Model-agnostic Explanations的缩写。通过名字便可以看出,该模型是一个局部可解释模型,并且是一个与模型自身的无关的可解释方法。使用训练的局部代理模型来对单个样本进行解释。假设对于需要解释的黑盒模型,取关注的实例样本,在其附近进行扰动生成新的样本点,并得到黑盒模型的预测值,使用新的数据集训练可解释的模型(如线性回归、决策树),得到对黑盒模型良好的局部近似。模型的权重用作解释,其中较大的系数意味着较高的重要性。SHAP:基于 Shapley 值,这些值是使用该特征在所有特征的不同集合中的平均边际贡献计算得出的。可以在我之前的文章中找到更多关于它的信息。
基于反事实的解释是生成反事实示例 (CF) 的方法,这些示例在输入特征发生最小变化的情况下产生不同的模型输出。例如: WachterCF:寻找一个尽可能接近原始输入 x 的示例 c*,以获得与原始输出 f(x) 不同的期望输出 y。𝒄 * = arg c min (y_loss(𝑓 (𝒄), 𝑦) + 𝜆1 𝑑𝑖𝑠𝑡(𝒄, 𝒙)) 为了找到多个 c*s(又名反事实或 CF),我们只需初始化种子。每个特征的重要性分数是具有修改特征值的 CF 示例的分数。.为了获得全局解释,此归因分数在许多测试输入上取平均值。DiCE:与 WachterCF 非常相似,但为了生成不同的反事实,他们为损失添加了一个新术语,要求 CF 之间具有最大的多样性。如何判断是否是好的解释?
根据论文,一个好的解释是必要和充分的。这就是我们如何衡量两者的方法:这里假设𝑦 ∗ = 𝑓(𝒙 𝑗 = 𝑎,𝒙−𝑗 = 𝑏)是输入𝒙的分类器𝑓 的输出。必要性:衡量必要性的一种简单方法是使用一种生成反事实解释的方法,但将其限制为只有 𝒙 𝑗 可以改变。改变 𝒙 𝑗 导致有效反事实示例的次数的分数表明 𝒙 𝑗 = 𝑎 对于当前模型输出 𝑦 ∗ 的必要程度。充分性:我们没有改变 𝒙 𝑗 ,而是将其固定为原始值,并让所有其他特征改变其值,如果没有生成唯一有效的反事实示例,则意味着 𝒙 𝑗 = 𝑎 足以导致模型输出 𝑦 ∗ .一般来说,我们可以说基于归因的解释优化了充分性,而反事实解释优化了必要性。
重要的特征是必要的吗?
为了测试这一点,他们使用 SHAP 和 LIME 对前 3 个特征进行了排名,并基于两种反事实方法测试了它们的必要性:WachterCF 和 DiCE 在基准数据集上:Adult-Income(8 个特征)、LendingClub(8 个特征)和German-Credit(20个特征)。基于这些数据集的答案是肯定的:必要性通常与 LIME 和 SHAP 的特征排名一致:特征重要性得分越高必要性越大。他们确实看到,随着数据集中特征数量的增加,这种假设变得越来越弱。他们随后研究了一个真实世界中的住院预测问题,有大量的特征(222):分诊特征包括13个变量,表明患者到达急诊室时疾病的严重程度,9个人口特征,包括种族、性别和宗教,以及200个二元特征,表明存在各种主诉(病史中的主体部分)。在这里,他们看到LIME没有按照必要性的升序排列前3个函数,而SHAP仍然是这样做的。综上所述,基于这两个实验,SHAP的答案通常是“是”,但通常情况下这两个实验都没有优化其必要性。重要的特征是充分的吗?
他们重复了同样的实验来查看充分性。基于 SHAP 和 LIME 两个数据集的答案通常是否定的,前 3 个特征并不是充分的。在基准数据集中,我们还看到两种反事实方法之间的充分性指标发生了显着变化。我们在实验中看到,对于模型的预测重要性排名高的特征往往既不是必要的、也不是充分的并且随着数据集中特征数量的增加,高排名特征的必要性和充分性变得更弱。这些方法是否相互关联呢?
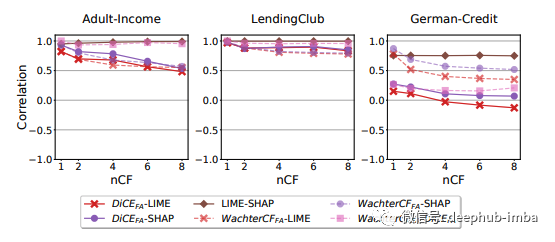
首先,我们需要理解每种方法会产生不同的值分布,在特征重要性方面只需要看特征的相对值。在基准数据集上,LIME和SHAP比DiCE和WachterCF更接近。在German-Credit中随着nCF的增长,与DiCE的相关性可能变成负的。该图显示了基准数据集上不同方法的特征重要性得分的皮尔逊相关系数。
但是,在“真实世界”的数据集中,我们看到LIME和SHAP之间几乎没有关联。这张图显示了“真实世界”数据集上不同方法的特征重要性得分的皮尔逊相关系数。
总结
这篇论文表明,解释方法是互补的,并且没有一种最好的方法来解释模型。因此,在工作中,可以根据我们的目标例如检查必要性、充分性或其他一些指标来选择相关的方法来衡量它。最后,在这篇文章中有一个假设就是特征都是独立的,但在我看来在“真实世界”中这个假设可能不会成立,所以可能会严重影响结果,例如我们最后的“真实世界”的数据集的表现就与基准数据集不太一样,这个可能就是产生不同的一个原因。[1] *“Towards Unifying Feature Attribution and Counterfactual Explanations: Different Means to the Same End”* https://arxiv.org/pdf/2011.04917.pdf



 下载APP
下载APP