
独家 | 图片主题建模?为什么不呢?!

作者:Maarten Grootendorst 翻译:陈超
校对:赵茹萱
本文约3200字,建议阅读5分钟
本文介绍了使用图片主题进行建模。
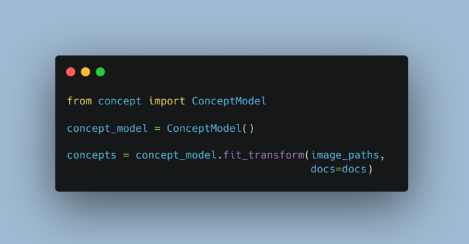


pip install conceptimport os | |
import glob | |
import zipfile | |
from tqdm import tqdm | |
from sentence_transformers import util | |
# Download 25k images from Unsplash | |
img_folder = 'photos/' | |
if not os.path.exists(img_folder) or len(os.listdir(img_folder)) == 0: | |
os.makedirs(img_folder, exist_ok=True) | |
photo_filename = 'unsplash-25k-photos.zip' | |
if not os.path.exists(photo_filename): #Download dataset if does not exist | |
util.http_get('http://sbert.net/datasets/'+photo_filename, photo_filename) | |
#Extract all images | |
with zipfile.ZipFile(photo_filename, 'r') as zf: | |
for member in tqdm(zf.infolist(), desc='Extracting'): | |
zf.extract(member, img_folder) | |
# Load image paths | |
img_names = list(glob.glob('photos/*.jpg')) |
import random |
import nltk |
nltk.download("wordnet") |
from nltk.corpus import wordnet as wn |
all_nouns = [word for synset in wn.all_synsets('n') for word in synset.lemma_names() |
if "_" not in word] |
selected_nouns = random.sample(all_nouns, 50_000) |
from concept import ConceptModel |
concept_model = ConceptModel() |
concepts = concept_model.fit_transform(img_names, docs=selected_nouns) |
import pickle | |
from sentence_transformers import util | |
# Load pre-trained image embeddings | |
emb_filename = 'unsplash-25k-photos-embeddings.pkl' | |
if not os.path.exists(emb_filename): #Download dataset if does not exist | |
util.http_get('http://sbert.net/datasets/'+emb_filename, emb_filename) | |
with open(emb_filename, 'rb') as fIn: | |
img_names, image_embeddings = pickle.load(fIn) | |
img_names = [f"photos/{path}" for path in img_names] |
view rawpretrained_embeddings.py hosted with ❤ by GitHub
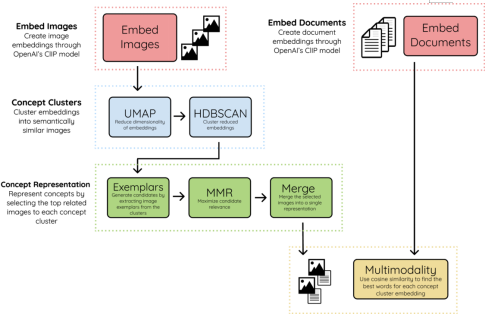
之后,我们将预训练的嵌入添加到模型中并训练它:
from concept import ConceptModel
| |
# Train Concept using the pre-trained image embeddings | |
concept_model = ConceptModel() | |
concepts = concept_model.fit_transform(img_names, | |
image_embeddings=image_embeddings, | |
docs=selected_nouns) |
fig = concept_model.visualize_concepts() |
view rawvisualize.py hosted with ❤ by GitHub
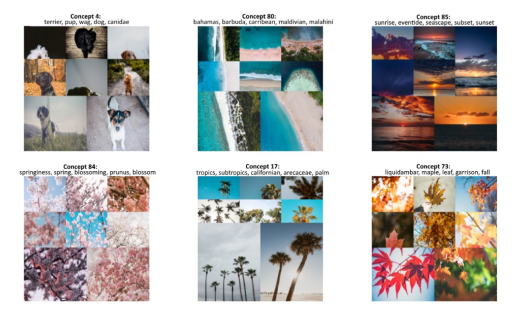

>>> search_results =concept_model.find_concepts("beach") | |
>>> search_results | |
[(100, 0.277577825349102), | |
(53, 0.27431058773894657), | |
(95, 0.25973751319723837), | |
(77, 0.2560122597417548), | |
(97, 0.25361988261846297)] |
view rawsearch.py hosted with ❤ by GitHub
|
view rawvisualize_search.py hosted with ❤ by GitHub

译者简介

陈超,北京大学应用心理硕士在读。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。越来越发现数据分析和编程已然成为了两门必修的生存技能,因此在日常生活中尽一切努力更好地去接触和了解相关知识,但前路漫漫,我仍在路上。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织