矿区无人机影像地物提取(语义分割)

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
1. 实验数据介绍
无人机拍摄的高分辨率矿区影像图
实验室进行标注的对应label
v0219版本:进行裁剪后的640 x 640的图像与label数据
v0225&v0301版本及之后:进行裁剪后的320 x 320的图像与label数据,并更换测试集
2. 实验环境介绍
GPU等服务器资源不加介绍
Python3.6、Pytorch、OpenCV、torchvision、numpy等必备环境
图像切割工具包GDAL:仅在win系统下可运行
3. 实验流程介绍
原图数据和标注好的label数据,label是灰度的图像,且每个像素属于该类(0-3)共四类
切割原图和相应的label数据为640 x 640的图像,后期改为320大小进行实验
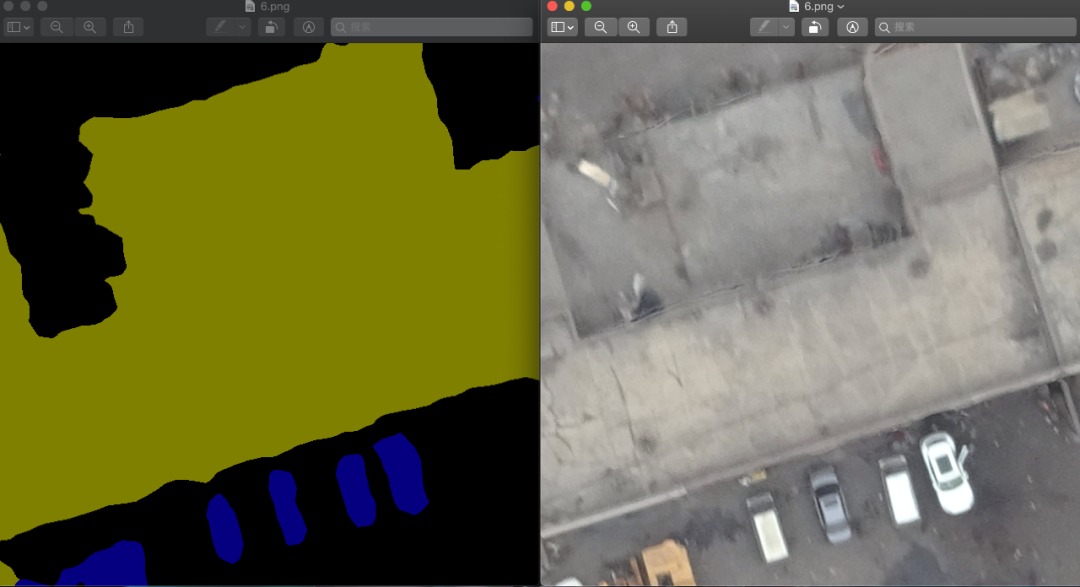
将切割好的原图和label对应好,使用代码进行可视化(因为标注的label是灰度,直观上看是黑色一片)
对数据进行数据增强,切割完成才有对应的几百张数据,增强至几千张
增强后的数据也要一对一对应好,建议一开始就取两者相同的图像名,使用可视化进行测试
数据划分,分为训练集、验证集、测试集;按照6:2:2的比例
搭建网络代码,使用Pytorch搭建网络,后期加入多种trick进行测试
编写train.py训练代码,写好训练流程、保存模型、保存loss等信息
训练完成之后,使用保存的模型进行预测,对预测出的图片进行涂色,使之可视化
根据预测结果进行kappa系数、mIoU指标的计算
4. 实验部分代码简介
数据简介:以一张大图和对应的label为例,可视化label以便查看原始数据
数据切割:介绍有关tif文件的切割,以及转换tif格式为png格式
灰度label可视化:由于label是1通道的图像,直观上是黑色图像,写代码使得同类别像素一个颜色进行可视化
数据增强_Data_Augmentation.py:离线数据增强,对图像进行随机旋转、颜色抖动、高斯噪声处理;
数据载入及数据划分:v0304版本之前的数据载入方式,使用简单留出法划分训练集、验证集
基于k折交叉验证方式的数据载入及数据划分:基于k折交叉验证,避免了因偶然因素引起的验证集的不同(验证集随机划分,每次实验结果都会有影响)
deeplabv3.py:基于pytorch的deeplab_v3网络搭建代码
deeplabv3论文笔记:论文Rethinking Atrous Convolution for Semantic Image Segmentation的阅读笔记
train.py:v0304版本之前训练程序的代码,基于简单留出验证
train_kfold.py:基于交叉验证方式的训练程序的代码
predictv0217.py:使用生成的训练模型来预测,并给预测图片进行涂色显示
MIoU指标计算:使用PyTorch基于混淆矩阵计算MIoU、Acc、类别Acc等指标
Kappa系数计算:使用PyTorch基于混淆矩阵计算Kappa系数评价指标
5. 实验版本数据记录
本实验有多个版本,具体实验详情如下:
使用图像增强进行训练集的生成,640大小的图像:训练集1944张、验证集648张、测试集162张
v0225版本&v0301版本,320大小的图像:训练集9072张、验证集2268张、测试集378张
v0607版本之后:第三次调整数据;使用dataset3
v0923版本之后:加入dsm高程数据;使用dataset4
v1012版本之后:加入了新数据;使用dataset5
图像的预处理:无标准化、只进行了归一化
损失函数:CrossEntropyLoss
优化器:SGD、lr=1e-3、动量=0.9;v0219版本测试Adam优化器、lr=1e-3
v0225版本&v0301版本:Adam优化器、lr=1e-3
v0225版本:deeplabv3-resnet152
v0301版本:deeplabv3-resnet50
v0304版本:deeplabv3-resnet152,将简单留出验证改为5折交叉验证
V3p-101:deeplabv3+-resnet101 + 5折交叉验证
V3p-152:deeplabv3+-resnet152 + 5折交叉验证
DANet_res:danet-resnet152 + 5折交叉验证
Deeplabv3_dan:deeplabv3-dan-resnet152 + 5折交叉验证
CCNet0403:ccnet-resnet152 + 5折交叉验证
CCNet0509:deeplabv3-ccnet-resnet152 + 5折交叉验证
ResNeSt0518:deeplabv3-resnest152 + 5折交叉验证(此代码修改自resnest分类网络代码)
ResNeSt0525:deeplabv3-resnest101 + 5折交叉验证(此代码修改自resnest用于分割的代码)
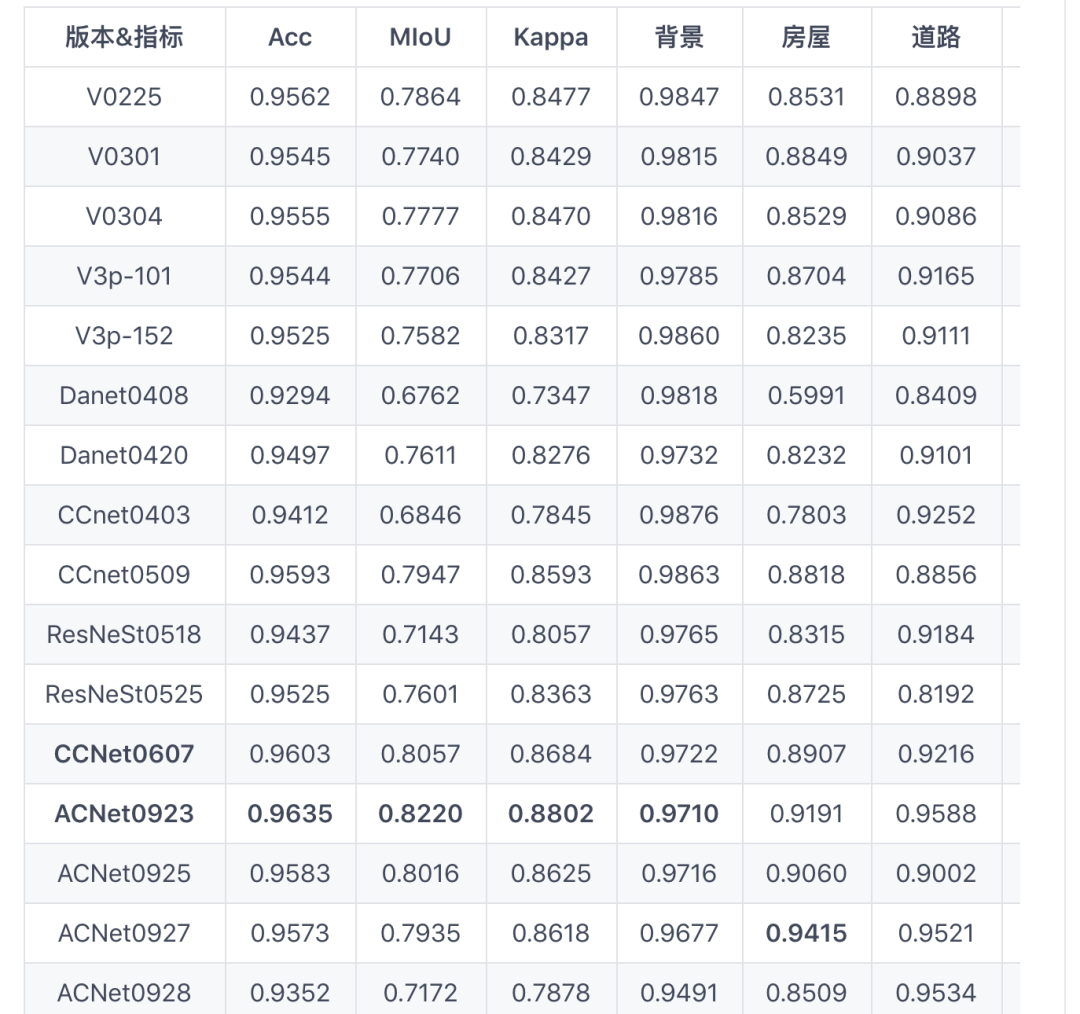
CCNet0607: deeplabv3-ccnet-resnet152 + 5折交叉验证 + 第三次调整数据 + 使用weight减轻样本不均衡
ACNet0923: ACNet-resnet50 + 5折交叉验证 + 加入dsm高程信息 + 使用weight减轻样本不均衡 + 40
ACNet0925: ACNet-resnet101 + 5折交叉验证 + 加入dsm高程信息 + 使用weight减轻样本不均衡 + 40
ACNet0927: ACNet-resnet50 + CCNet替换decode的agant层 + 5折交叉验证 + 加入dsm高程信息 + 使用weight减轻样本不均衡 + 45
ACNet0928: ACNet-resnet50 + CCNet替换原通道注意力模块 + 5折交叉验证 + 加入dsm高程信息 + 使用weight减轻样本不均衡 + 45
ACNet0930: ACNet-resnet50 + CBAM替换原通道注意力模块 + 5折交叉验证 + 加入dsm高程信息 + 使用weight减轻样本不均衡 + 45
ACNet1002: ACNet-resnet50 + 5折交叉验证 + 加入dsm高程信息 + 使用weight减轻样本不均衡 + 40 + ACNet0923对照实验测试Focalloss效果
ACNet1004: ACNet_del_M_model-resnet50 + 5折交叉验证 + 加入dsm高程信息 + 使用weight减轻样本不均衡 + 40
ACNet1005: ACNet1004对照实验 + torch.cat代替
+融合方式;比较两者融合的效果好坏ACNet1006: ACNet1004对照实验 + CC_Moudle代替上采样过程中的4个agant层
ACNet1008: ACNet1004对照实验 + CC_Moudle代替上采样过程中的第1个agant层
ACNet1009: ACNet1004对照实验 + m0-m4融合的特征加入到RGB分支
ACNet1010: ACNet1004对照实验 + sk-resnet50网络替换se-resnet50
ACNet1012: ACNet0923网络结构 + 新的dataset5数据集
ACNet1014: ACNet1004网络结构 + 新的dataset5数据集
ACNet1016: ACNet1014对照实验 + 编码器的最后融合前添加ASPP模块
ACNet1021: ACNet1014对照实验 + 将高程数据的分支的通道注意力改为空间注意力
ACNet1023: ACNet1014对照实验 + 将RGB数据的分支的通道注意力改为通道与空间注意力串行
ACNet1025: ACNet1014对照实验 + 替换注意力机制中的一个卷积为两个卷积层
ACNet1029: ACNet1014对照实验 + 将RGB数据的分支的通道注意力改为通道与空间注意力并行
ACNet1101: ACNet1014对照实验 + 删除了第一个卷积层之后的注意力机制与融合 + 删除对下采样的指导
ACNet1103: ACNet1014对照实验 + 将之前的agant层替换为金字塔池化模块ppm + sizes==(1,2,5,10)
ACNet1106: ACNet1014对照实验 + 将之前的agant层替换为金字塔池化模块ppm + sizes==(1,2,5)
ACNet1110: ACNet1014对照实验 + 将RGB分支和高程分支的通道注意力改为通道与空间注意力并行
ACNet1113: ACNet1014对照实验 + 将RGB分支的通道注意力改为通道与空间注意力并行,高程分支为串行
5.1 实验版本记录 & 一些想法
数据增强加入随机裁剪操作,并双线性插值pad至320大小(不能pad,标签pad就不是真实值),投入训练
随机裁剪数据至192大小,没有pad,和320大小的数据一起当做训练集,出现错误提示:一个batch的数据,[B,C,H,W]必须一致,由于320和192大小的数据掺杂,所以报错。因为实验使用离线的数据增强
因数据集中样本数量不平衡,测试weighted Cross Entropy-Loss以及Focal-Loss
使用CCNet单独训练
v0403版本:只使用了ccnet注意力模块的输出上采样,结果为不收敛,但是使用epoch-8.pth测试有点效果
后期测试:将x与x_dsn特征融合,进行测试,测试结果如下,可以看出较danet单独训练结果稍好,车辆acc例外
CCNet与deeplabv3共同使用,将注意力模块加入deeplabv3
测试到epoch12,由于服务器原因程序中断,查看log,在训练集、验证集上的loss都较之前增大
修改权重,根据训练数据集,算出真正的像素比例值,调整权重,重新训练
此次效果很好,其中明显在预测图中【道路】的识别率增大,且指标上涨明显
v0509版本:将ccnet模块与aspp模块并行,cat两个结果,最后进行分割。整体Acc、MIoU、Kappa都达到了最高
v0509版本:只有道路和车辆的准确率低于以往的实验
v0607版本:测试Cross Entropy-Loss加入权重[0.1, 0.8, 1.0, 1.0]
DAN网络单独训练
danet_drn_v0408版本:output包括feat_sum、pam_out、cam_out,采用辅助loss训练,结果一塌糊涂
danet_v0408版本:更换backbone网络为resnet-152,替换deeplabv3的aspp模块,不使用辅助loss,使用feat_sum进行结果的分割,结果详见下表Danet0408
DAN模块并行加入deeplabv3网络中,实验数据如下所示
将deeplabv3的backbone网络Resnet换为ResNeSt,目前测试版本:resnest-v0518
此版本:根据代码修改,去除aspp后的层,模仿deeplabv3-resnet进行修改,效果一般,仅仅提升了道路的识别
根据@张航作者的代码进行更改得出,deeplabv3-resnest101,已测试
目前的实验目标:提高车辙的识别率(道路的标注中,有一部分是车轮轧过的车辙),最怀疑是数据量不够
思路1:加大数据量,如下进行的新的数据增强;
思路2:调整损失函数,加入weight权重,减轻样本数目不平衡问题;
实验结果有较大的提升,见下结果
关于数据的调整:重新审视了代码,测试了增强的结果;其中,颜色抖动、随机旋转有效;高斯噪声处理像素值改变小;
更新:删除了反转的图像中全黑的label,即全是背景的label;(减轻一下样本不均衡)
在原训练数据上新添加如下:左右翻转图像;上下翻转图像;其中各1890张,共3780张;
有关第三次数据调整,详见issue-数据调整汇总
5.2 基于RGB与高程数据的语义分割实验
数据处理部分
Depth原始数据(高程数据)是32位的tiff格式图像,需转换为8位的tiff格式图,使用python的代码直接转换会线性压缩图像的对比性,所以要先找到图像像素的极值,将其像素之间的差做出来,再使用代码转换为uint8文件。转换代码地址:32to8.py
png切割代码:png_crop.py
在dataset3中有筛选出的特征较均衡的图像,使用代码筛选切割好的dsm高程数据;代码:file_find.py
基于dataset3加入dsm高程数据:dataset4的调整记录
代码 获取方式:
分享本文到朋友圈
关注微信公众号 datayx 然后回复 分割 即可获取。
AI项目体验地址 https://loveai.tech
5.3 test测试数据集-各版本结果对比
6. 实验分割结果展示