
新版《鹿鼎记》史上最低分?! 我们用数据分析来盘一盘韦小宝
数据:真达
大家好,欢迎来到Crossin的编程教室!
今天教大家用数据盘一盘《鹿鼎记》。公众号后台,回复关键字“鹿鼎记”获取完整数据。
最近,由张一山主演的新版《鹿鼎记》被骂上了热搜。本来由于在《余罪》里的出色表演,观众对张一山饰演韦小宝期待值并不低,然而开播没几天口碑却断崖式下跌,豆瓣2.6分,直接稳坐史上最差版《鹿鼎记》。
不仅被网友诟病演技浮夸,剧情跳脱。原著里聪明伶俐的韦小宝,愣是被张一山演成了“猴灵猴现”的猴戏,尴尬得让人如坐针毡、如芒刺背、如鲠在喉。


新版《鹿鼎记》真的有这么差劲吗?
各大版本的《鹿鼎记》,哪部最为经典?
七个老婆中,韦小宝最喜欢哪个老婆呢?
今天我们就用数据来好好盘一盘。
细数历代各版《鹿鼎记》
哪部最受好评?
作为金庸封笔前的最后一部作品,从84年到现在,《鹿鼎记》的各种版本层出不穷。细数历代各版的《鹿鼎记》,哪部最受好评呢?



在这里我们对比了大家较为熟悉的这七个版本,分别是:
84年 梁朝伟版 92年 周星驰版 98年 陈小春版 00年 张卫健版 08年 黄晓明版 14年 韩栋版 20年 张一山版
各版本《鹿鼎记》豆瓣评分对比
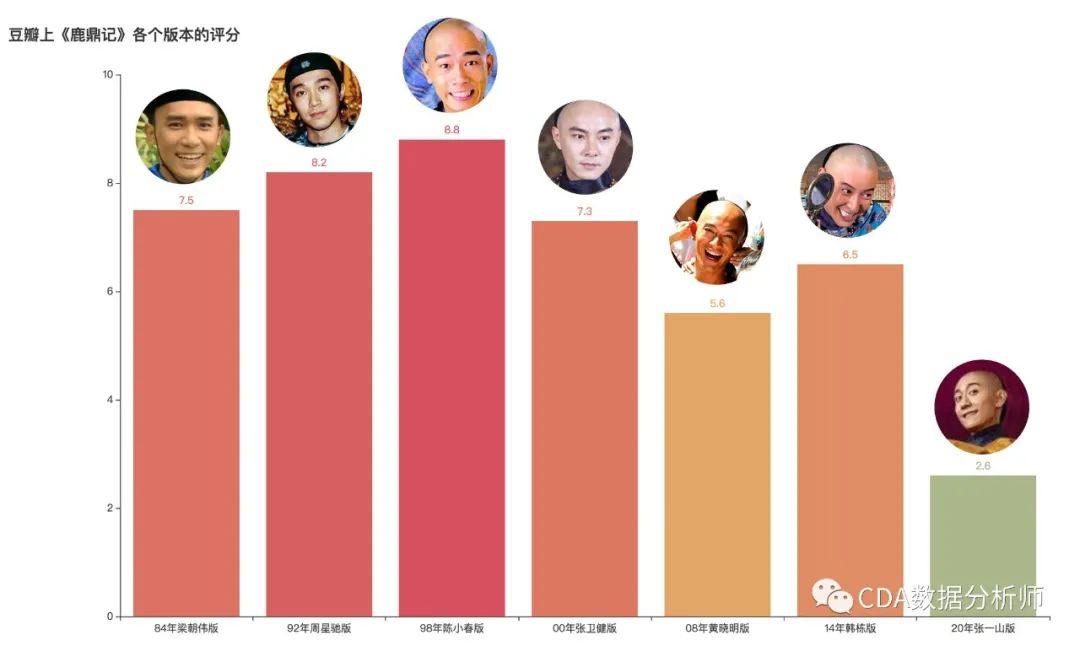
从豆瓣评分可以看到,2000年前的梁朝伟版、周星驰版、陈小春版和张卫健版都有不俗的口碑,评分也都在7分以上。特别是98年陈小春版更是收获最高分8.8分,成为无数观众心中的经典。之后的黄晓明、韩栋版都在5、6分左右徘徊。而张一山版最低,仅为2.6分。
各版本《鹿鼎记》评价分布
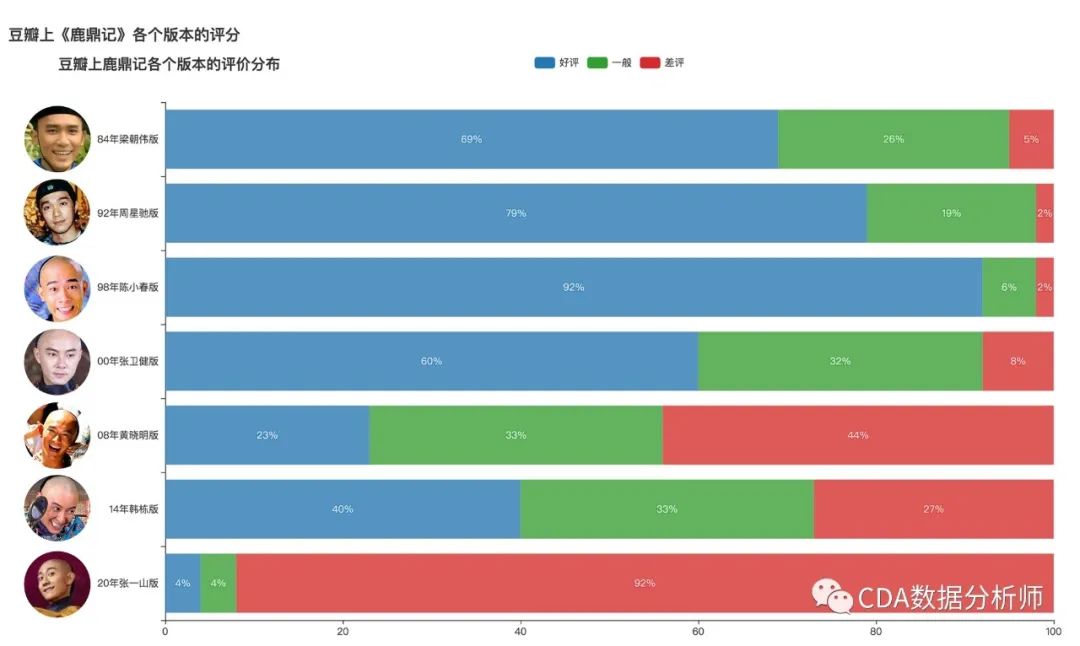
接着我们对各个版本的评价进行了分析,可以看到陈小春收获的好评最高,达到92%。而张一山版最为另一个极端,差评达到了92%。
史上最差《鹿鼎记》豆瓣2.6分
到底冤不冤?
那么最为史上最差《鹿鼎记》豆瓣2.6分 ,到底冤不冤?
张一山版《鹿鼎记》评价星级分布
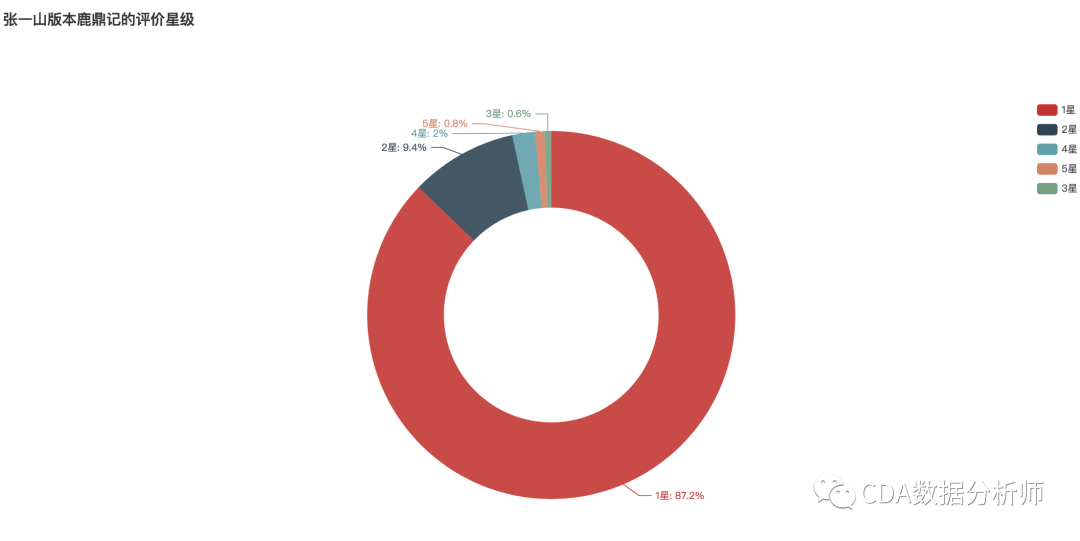
我们分析爬取了豆瓣500条评分数据,可以看到,其中给出1星的高达87.2%,压倒性的差评。
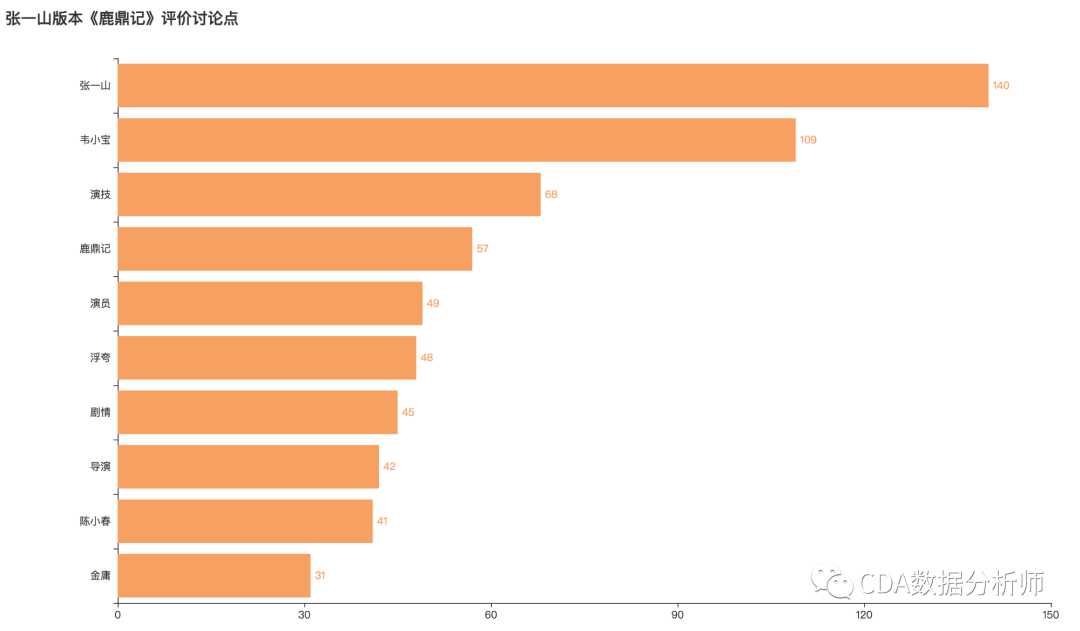
词云图对比:陈小春版VS张一山版
大家都在吐槽些什么呢?我们把《鹿鼎记》的最高分陈小春版和最低分张一山版进行评价词云对比,可以看到对陈小春版大家的评价集中在"经典" "好看"清一水儿的好评。
而张一山版的评价中,"浮夸" "看不下去" "用力" "难看" 等吐槽层出不穷。


评价的讨论点也主要集中在张一山的演技、浮夸、剧情等角度。
数据分析告诉你
韦小宝跟哪个老婆最亲?
《鹿鼎记》的其中一个亮点就是韦小宝七个貌美如花的老婆了。之前几个版本中,七个老婆都是美的各有特色,令人过目不忘。

陈小春版《鹿鼎记》韦小宝和七个老婆
而这次新版中的七个老婆却让网友们大呼眼盲,各个都傻傻分不清楚。

新版《鹿鼎记》韦小宝的七个老婆
那么韦小宝跟他七个老婆哪个最亲密?我们爬取了《鹿鼎记》整本小说的txt文档,用数据分析来告诉你。
首先我们这样定义亲密度的指标:在小说中有不同的段落,我们将韦小宝和七个老婆在同一个段落一起出现的次数,作为亲密度的指标。假设韦小宝和双儿在同一个段落中出现,则韦小宝和双儿的亲密度+1。
整体的实作流程如下:
小说文本的网络爬虫 数据清洗和整理 数据可视化探索 Apriori关联分析
小说文本网络爬虫
我们选择金庸作品集网站来进行数据抓取,网址为:http://jinyong.zuopinj.com/
爬虫思路:
首先请求小说首页的url获取每个章节的详情页url;
再请求详情页url并解析提取文本数据;
将抓取的数据分章节保存在本地的txt文档中。
实现代码:
# 导入库
import requests
import parsel
import os
from multiprocessing.dummy import Pool
class JinyongSpider(object):
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 保存子页面的url
self.titles = []
self.chapter_links = []
# 创建一个文件夹
if not os.path.exists('../鹿鼎记'):
os.mkdir('../鹿鼎记')
def parse_home_page(self, url='http://jinyong.zuopinj.com/3/'):
# 发起请求
response = requests.get(url, headers=self.headers)
# 修改编码
response.encoding = response.apparent_encoding
# 解析数据
selector = parsel.Selector(response.text)
# 获取数据
title = selector.xpath('//div[@class="book_list"]/ul/li/a/@title').extract()
chapter_link = selector.xpath('//div[@class="book_list"]/ul/li/a/@href').extract()
# 追加数据
self.titles.extend(title)
self.chapter_links.extend(chapter_link)
def parse_detail_page(self, zip_list):
print(f'正在爬取{zip_list[0]}章节的小说!')
# 发起请求
response = requests.get(url=zip_list[1])
# 修改编码
response.encoding = response.apparent_encoding
# 解析数据
selector = parsel.Selector(response.text)
# 获取数据
noval_text = selector.xpath('//div[@id="htmlContent"]//text()').extract()
noval_text = '\n'.join(noval_text)
# 写出数据
with open(f'../鹿鼎记/{zip_list[0]}.txt', 'w', encoding='utf-8') as fp:
print(f'正在写入{zip_list[0]}章')
fp.write(noval_text)
fp.close()
print('写入完毕,关闭文件!')
def multiprocees_function(self):
# 实例化线程,一个进程开启多个线程
pool = Pool(10)
zip_list = list(zip(self.titles, self.chapter_links))
# map操作(将zip_list中的每一个列表元素map到get_video_data的函数中,parse_detail_page这个函数接收的是列表元素)
pool.map(self.parse_detail_page, zip_list)
# 关闭线程池
pool.close()
# 主线程等待子线程结束之后再结束
pool.join()
if __name__ == '__main__':
# 实例化对象
jinyongspider = JinyongSpider()
# 先获取章节页面链接
jinyongspider.parse_home_page(url='http://jinyong.zuopinj.com/3/')
# 通过线程池运行爬虫
jinyongspider.multiprocees_function()
爬取到的数据保存在本地,格式如下所示:
数据清洗和整理
使用pandas对数据进行预处理,具体的处理思路如下:
首先将爬取的小说文本按照段落进行分割保存在列表中;
对列表进行循环,去匹配每个名字在每个段落是否有出现,出现标记为T,否则为F 。
处理之后的格式如下:
数据可视化
将处理之后的数据导入SPSS Modeler,进行后续的数据挖掘分析。以下为分析部分结果:
韦小宝在文章段落中的出现次数
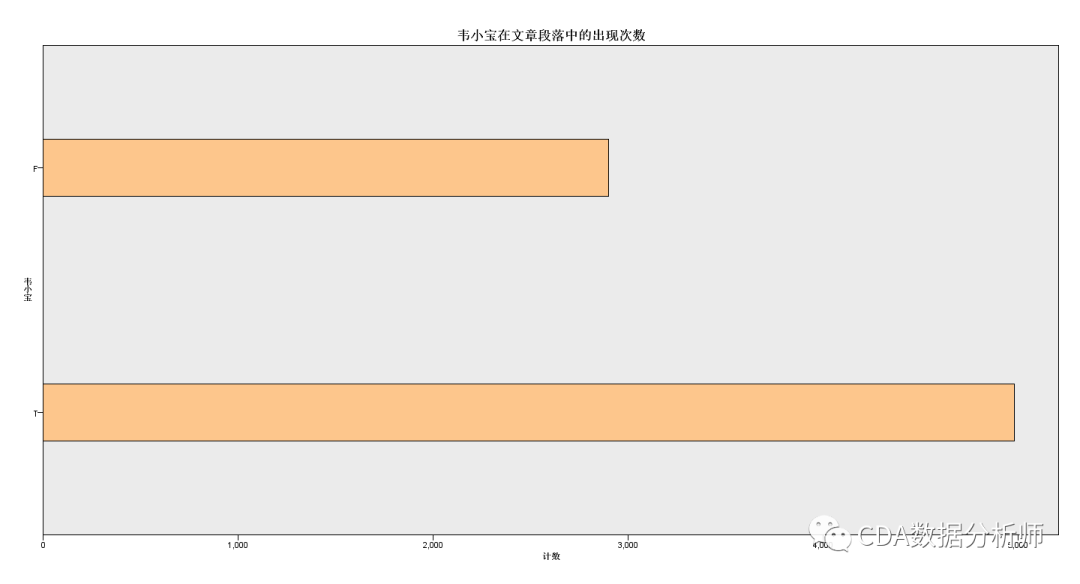
经过预处理之后的文章段落一共有7880条记录,其中关键字"韦小宝"出现的次数为4981次,占比63.21%。
韦小宝和七个老婆的亲密关系
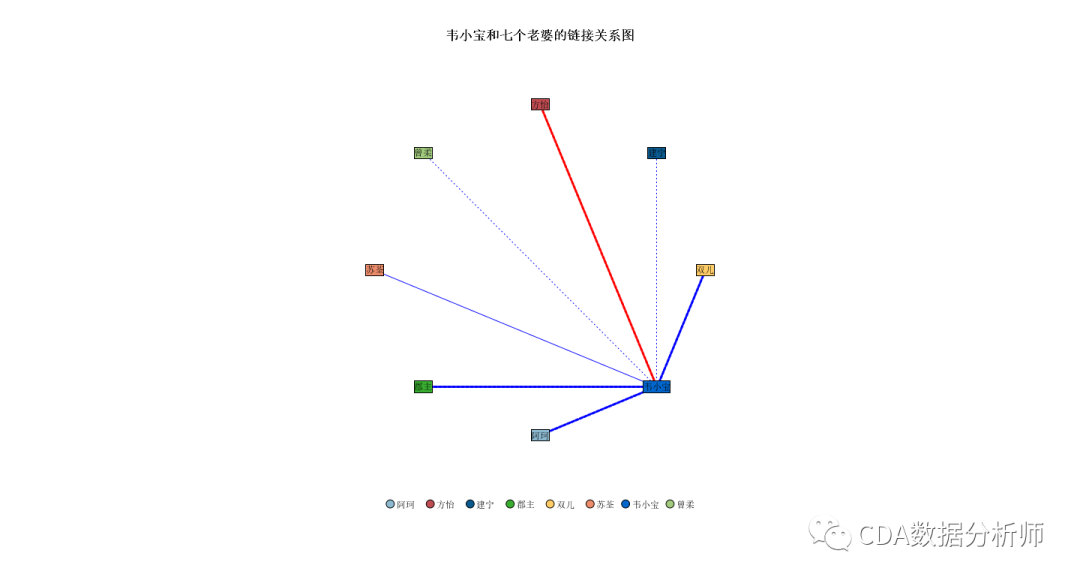
从链接关系图可以看出,是双儿获得了最高的亲密度得分,和韦小宝在同一个段落中出现284次。
其中:
强链接的有双儿、郡主、阿珂和方怡;
中等链接的是苏荃;
弱链接的是建宁公主和曾柔。
人物之间的链接关系图
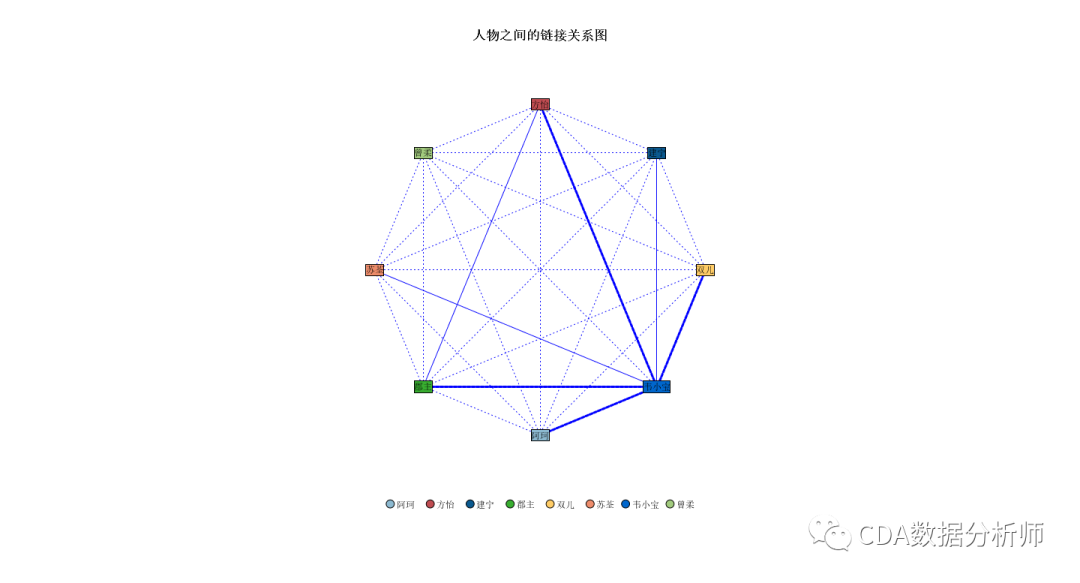
我们还可以绘制人物两两之间的链接关系图。
Apriori关联分析
Apriori算法是常用于挖掘出数据关联规则的算法,可以用来找出数据值中频繁出现的数据集合。
在Apriori算法中,支持度代表几个关联的数据在数据集中出现的次数占总数据集的比重,置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
以下是定义为最低条件支持度为3%,最低置信度为30%的参数下运行的结果:

从分析结果可以看出,在双儿出现的情况下,有79.77%的概率韦小宝会出现。这种情况在数据集中的占比为4.5%。
结语
以上就是全部的内容了。最后想说的是,对于翻拍剧来说,这么多珠玉在前,难免会被拿来比较。正因为如此,才更应该思考如何拍出不同于前作的亮点。而不是一味劣质地模仿。
经典之所以成为经典,就是因为很难被超越。还是希望以后能看到更好的国产翻拍剧吧。

公众号后台,回复关键字“鹿鼎记”获取完整代码及数据。
_往期文章推荐_