
什么是归一化,它与标准化的区别是什么?| 深度学习

文 | 七月在线
编 | 小七
解析:
本文主要讲述的是标准化与归一化的区别,相同点和联系,重点讲述各自的使用场景,归一化主要是应用于没有距离计算的地方上,标准化则是使用在不关乎权重的地方上,因为各自丢失了距离信息和权重信息,最后还讲述了下归一化的使用场景,主要是针对数据分布差异比较大–标准化和奇异数据(单个数据对结果有影响的话)–归一化的情况下的使用
请输入标题
1
不同点
2
相同点及其联系
3
归一化(广义)的场景
3.1特征/数据需要归一化的场景
3.2不需要归一化的场景
4
归一化(狭义)注意事项:
4.1归一化的方法
4.1.1小数定标标准化
4.1.2softmax对数归一化
4.1.3L2归一化
4.2指标衡量与权重保留
4.3归一化的使用前提
5
标准化的过程
6
参考文献
一、不同点
标准差与权重:某个指标数据对应的数据集标准差过大,说明其不确定性增加,所提供的信息量也会增加,因此在进行综合指标评价的时候,权重也会对应的增大.—-类似熵权法 二、相同点及其联系
1、联系:归一化广义上是包含标准化的,Z-Score方法也是归一化的方法之一,在这里主要是从狭义上,区分两者; 2、本质:上都是进行特征提取,方便最终的数据比较认识.都通过先平移(分子相减)后缩放(分母)进行进行提取; 3、 方便:都是为了缩小范围.便于后续的数据处理; 4 、作用:(重点) i) 加快梯度下降,损失函数收敛;—速度上
ii) 提升模型精度–也就是分类准确率.(消除不同量纲,便于综合指标评价,提高分类准确率)—质量上
iii) 防止梯度爆炸(消除因为数据输入差距(1和2000)过大,而带来的输出差距过大(0.8,999),进而在 反向传播的过程当中,导致梯度过大(因为反向传播的过程当中进行梯度计算,会使用的之前对应层的输入x),从而形成梯度爆炸)—稳定性上
说明:特征缩放其实并不需要太精确,其目的只是为了让梯度下降能够运行得更快一点,让梯度下降收敛所需的循环次数更少一些而已。 三、归一化(广义)的场景
A、除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据支配 B、数据分布差异比较大–标准化和奇异数据(单个有影响的也要)–归一化
3.1 特征/数据需要归一化的场景① logistic regression模型:逻辑回归,虽然迭代若几次没有影响,但实际当中远不止若干次,这样就会导致逻辑回归模型的目标函数过于扁化,导致梯度很难下降,不容易得到较好的模型参数. ② SVM模型:因为涉及到向量/数据的距离(向量之间差异过大/过小,就会导致最佳分离超平面可能会由最大/远或者最小/近的几个向量支配,导致鲁棒性较差,因此需要进行标准化—可以保留向量间的模型) ③ NeuralNetwork模型:初始输入值过大,反向传播时容易梯度爆炸(上面有解释) ④ SGD:加快梯度下降.
3.2 不需要归一化的场景① 0/1取值的特征通常不需要归一化,归一化会破坏它的稀疏性 ② 决策树,原因详见:https://www.julyedu.com/question/big/kp_id/23/ques_id/923
③ 基于平方损失的最小二乘法OLS不需要归一化(因为本质上是一个抛物线,强凸函数,下降速度快.)四、归一化(狭义)注意事项
4.1 归一化的方法小数定标标准化这种方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于属性A的取值中的最大绝对值。将属性A的原始值x使用decimal scaling标准化到x’的计算方法是: ① x'=x/(10^j),其中,j是满足条件的最小整数。例如 假定A的值由-986到917,A的最大绝对值为986,为使用小数定标标准化,我们用1000(即,j=3)除以每个值,这样,-986被规范化为-0.986。
注意,标准化会对原始数据做出改变,因此需要保存所使用的标准化方法的参数,以便对后续的数据进行统一的标准化。
② softmax对数归一化
③ L2归一化
上图所示,L2归一化过程:其实就是x本身/2范数 4.2 指标衡量与权重保留 在归一化中,指标之间其实一般都存在单位的标准问题,例如:我们评价一个人的健康程度,有如下指标,假设一个人身高 180cm,体重 70kg,白细胞计数7.50×10^{9}/L,各个量纲都不一样,因此归一化就是消除各个量纲,然后将各个指标结合起来,共同参与到评价健康程度当中,这个就是归一化需要做的事情–消除量纲,便于数据(结合了各个指标的健康程度)/综合评价的比较。 因此我们在进行归一化的时候,我们就需要对各个指标的权重进行保留,方便评价. 4.3 归一化的使用前提 在存在奇异样本数据的情况下,进行训练之前最好进行归一化,如果不存在奇异样本数据,则可以不用归一化 五、标准化的过程
即零-均值标准化
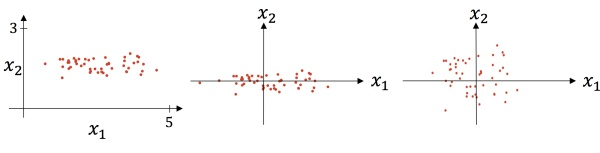
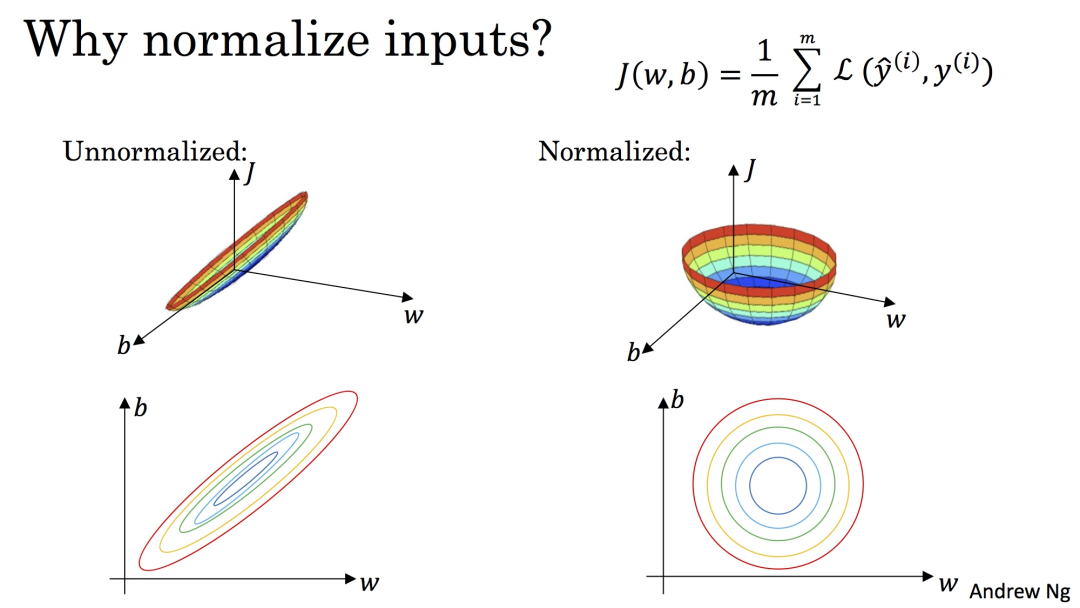
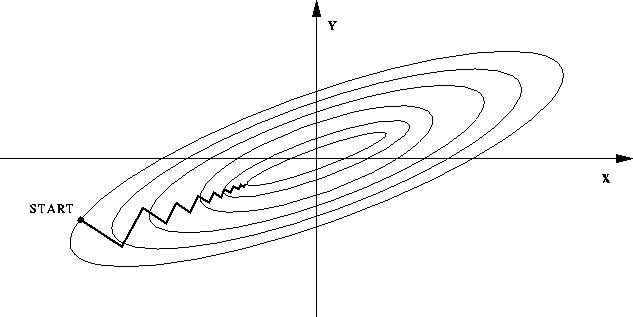
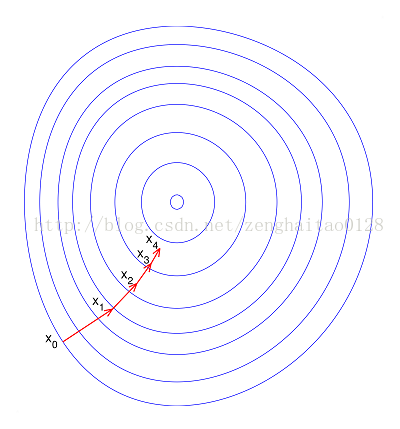
其中 u是样本数据的均值(mean),是样本数据的标准差(std)。上图则是一个散点序列的标准化过程:原图->减去均值(均值为0–>数据以原点为中心)->除以标准差对应到三维图像(以损失函数为例) 机器学习的目标无非就是不断优化损失函数,使其值最小。在上图中,J(w,b)就是我们要优化的目标函数,在上图中,我们可以看到,损失函数,未处理之前:梯度的方向就会偏离最小值的方向,走很多弯路,经过标准化处理之后,我们损失函数的曲线也变得比较圆,有利于加快梯度下降,加快找到最佳模型参数.具体如下图: 标准化前
标准化后六、参考文献归一化与标准化
归一化与标准化
归一化、标准化区别的通俗说法
此外,这里还有一个免费公开课:《深度学习中的归一化》链接:http://www.julyedu.com/video/play/69/686


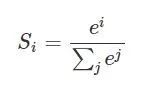
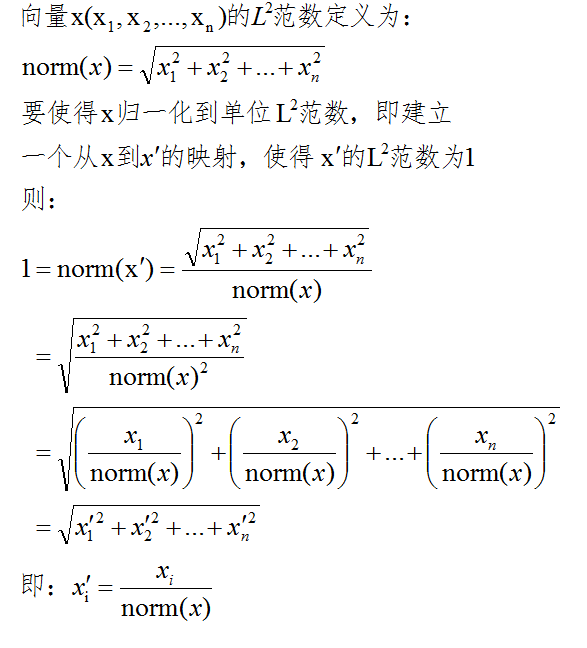
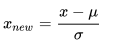
精品课程好课
【深度学习 特训课】三大专家级讲师联合授课,从基础的神经网络入手,逐步往各大热门应用领域深入,理论和实践完美结合,带你迅速、高效的入门深度学习。
不论你是在校生,还是已经工作的算法工程师,或者是打算转行深度学习相关岗位的人,这门课都是深度学习路上的必修课程。
