
CLIP中文模型开源!中文版 DiscoDiffusion 文图生成算法即将到来?
大家好,我是阿潘 
前段时间和几个小伙伴参加一个多模态的比赛,拿了第三,了解了一些多模态相关的内容。但是针对中文视频语义理解的任务,相关开源工作感觉并不是很多。
今天发现两个中文 clip 的开源工作,必须的支持一波,这肯定费了不少电。。。
一个是 IDEA 研究院的分享,另一个来自清华大学开源的工作
IDEA:https://zhuanlan.zhihu.com/p/546245070
清华:https://github.com/strategist922/Chinese-CLIP
以下是详细介绍
CLIP中文模型开源
近期在做CLIP中文模型的训练,期间踩过不少坑,目前算是把模型训练得还可以了。作为封神榜IDEA-CCNL (Fengshenbang-LM)开源计划的一部分,将目前训好的中文模型开源出来,可以用Hugging Face的接口直接调用。
目前的模型都是基于wukong数据集训练的(大约1亿条图文对,我们实际只下载到0.9亿)。对于image encoder,直接加载openAI的权重(from scratch训练的指标不是那么好,吃力不讨好...),冻住不训练;对于text encoder, 则是加载中文robert预训练模型作为初始化权重进行训练。因此,我们放出来的开源模型只有text encoder,image encoder直接用openAI的权重即可。
目前模型有2个版本,欢迎使用~
CLIP-Roberta-large
这个版本基于 ViT-L-14和 Roberta-wwm-large训练,目前已在hugging face开源,详细介绍和使用方法见:
https://huggingface.co/IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese

CLIP-Roberta
这个版本基于 ViT-B-32和 Roberta-wwm训练,目前已在hugging face开源,详细介绍和使用方法见:
https://huggingface.co/IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese
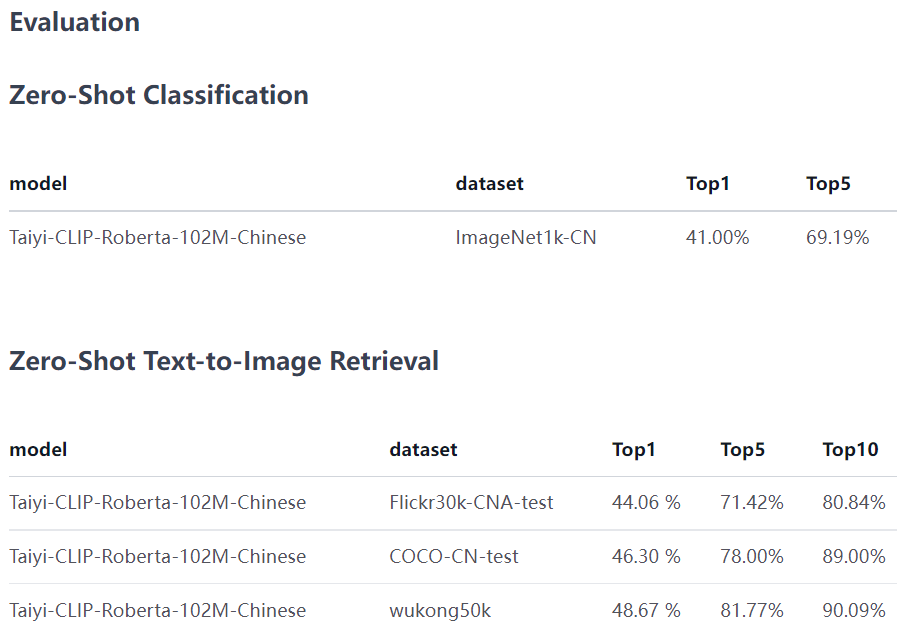
下游应用
图文检索
CLIP最显然的用途当然是用于中文的图文检索(分类任务也可以转换成检索任务),因此我在hugging face上放的示例代码就是图文检索用于zero-shot classification(用CLIP检索的方式做分类可以实现任意标签的分类,随你定义)
基于中文CLIP的图像生成(text2img)
由于我目前也在做图像生成方面的研究,所以基于训练好的中文CLIP和DiscoDiffusion去做text-to-image的图像生成。下面是一些cheery-pick的结果。(图片名字为输入的prompt)






