我们终于知道那些折磨人的乐谱是怎么来的了 —— 都是 AI 生成的。

知名偶像企划 LoveLive! 发 AI 论文了,是的没错。最近,预印版论文平台 arXiv 上的一篇论文引起了人们的注意,其作者来自游戏开发商 KLab 和九州大学。他们提出了一种给偶像歌曲自动写谱的模型,更重要的是,作者表示这种方法其实已经应用过很长一段时间了。通过深度学习技术,AI 算法在图像分类,语音识别等任务上有了优异的表现,但在理解复杂、非结构化数据方面,机器学习面临的挑战更大,比如理解音频,视频,文本内容,以及它们产生的机制。物理学家费曼曾说过:「凡是我不能亲自创造出来的,我就不是真正理解。」而随着技术的发展,深度生成模型已在学界和业界获得了广泛应用。在如今的游戏开发过程中,生成模型正在帮助我们构建各种内容,包括图形、声音、角色动作、对话、场景和关卡设计。KLab 等机构提交的论文介绍了自己的节奏动作游戏生成模型。KLab Inc 是一家智能手机游戏开发商。该公司在线运营的节奏动作游戏包括《Love Live!学院偶像季:群星闪耀》(简称 LLAS)已以 6 种语言在全球发行,获得了上千万用户。已经有一系列具有类似影响的类似游戏,这使得该工作与大量玩家密切相关。在 LLAS 中,开发者面临的挑战是为不同歌曲生成乐谱,提示玩家在不同时机点击或拉拽按键,这是节奏音乐游戏中所定义的挑战。在一局游戏中,飘过来的按钮被称为音符,它们形成类似于乐谱的空间图案,与后台播放的歌曲节奏对应。一首歌曲存在不同的难度模式,从初级、中级、高级和专家到挑战,复杂度顺序递增。
相对其他音游,LLAS 虽然不怎么考验反应速度,但机制相对复杂得多在全部按准的前提下还有 buff、debuff、三种属性分别对应体力、暴击和分数,想要高分还需要在打歌时不停切换队伍。由于 LoveLive!是一个有 12 年历史的企划,包含四个团体和数个小团体,个人还有角色歌,很多歌曲都会在游戏中出现,设计对应的乐谱变成了一件极具挑战的工作。
游戏开发者表示,他们的做法是通过 AI 辅助的半自动化方式:先由 AI 生成乐谱,再由 KLab 的艺术家进行微调,另一种方式是 AI 生成低难度乐谱,游戏设计师在这个基础上设计高难度。KLab 表示,他们使用的 GenéLive! 模型成功地降低了一半业务成本,该模型已部署在公司日常的业务运营中,并在可预见的未来时间里持续应用。降低乐谱生成的成本对于在线音游开发者来说是一个重要挑战,因为它是日常运营的瓶颈。KLab 提出的方法实现了只需要音频,就可以直接生成乐谱。在研究过程中,开发者们首先提出了 Dance Dance Convolution (DDC) ,生成了具有人类高水平的,较高难度游戏模式的乐谱,但低难度反而效果不好。随后研究者们通过改进数据集和多尺度 conv-stack 架构,成功捕捉了乐谱中四分音符之间的时间依赖性以及八分音符和提示节拍的位置,它们是音游中放置按键的较好时机。DDC 由两个子模型组成:onset(生成音符的时机)和 sym(决定音符类型,如轻按或滑动)目前正在使用的 AI 模型在所有难度的曲谱上都获得了很好的效果,研究人员还展望了该技术扩展到其他领域的可能性。
论文链接:https://arxiv.org/abs/2202.12823KLab 应用深度生成模型来合成乐谱,并改进乐谱的制作流程,将业务成本降低了一半。该研究阐明了如何通过专门用于节奏动作的多尺度新模型 GenéLive!,借助节拍等来克服挑战,并使用 KLab 的生产数据集和开放数据集进行了评估。此前,KLab 乐谱的生成工作流是在不考虑自动化的情况下形成的,几乎没有达成明确的规则或数学优化目标。因此,该研究选择使用监督机器学习。到 2019 年底,KLab 已经发布了数百首歌曲的音频序列和相应的人工生成乐谱。一方面,这个项目被要求快速交付并起到协助的作用;另一方面,项目的目标具有挑战性,旨在改进 SOTA 深度生成模型。通常,研究新型神经网络架构需要大量的反复试验,这个过程需要六个月或更长时间。为了解决时间上的问题,该研究组织了一个模型开发团队和一个模型服务团队,通过与艺术家团队保持联系获得反馈,将其反映到模型开发和服务中,并在第一时间提供更新的模型,从而使他们保持一致。GenéLive! 的基础模型由卷积神经网络 CNN 层和长短期记忆网络 LSTM 层组成。对于频域中的信号,作者利用 CNN 层来捕获频率特征,对于时域利用 LSTM 层来完成任务。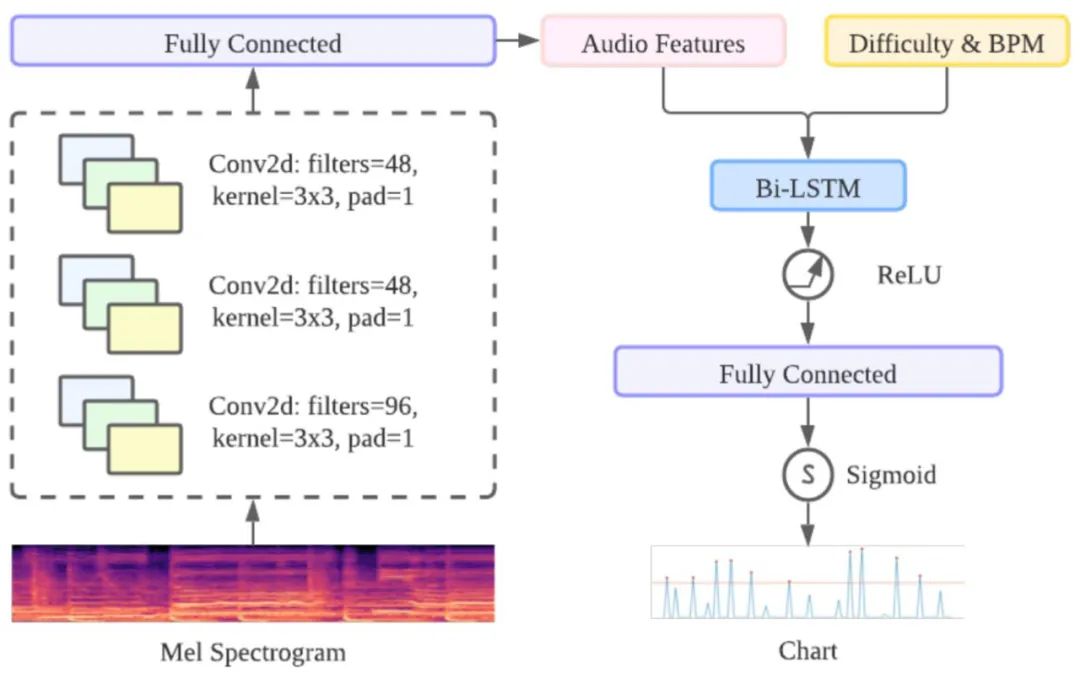
在这里,卷积堆栈(conv-stack)的主要任务是使用 CNN 层从 mel 频谱图中提取特征。conv-stack 包括一个具有批量标准化的标准 CNN 层、一个最大池化层和一个 dropout 层,激活函数是 ReLU。最后为了规范输出,这里使用了全连接层。时域方面采用了 BiLSTM,提供前一个 conv-stack 的输出作为输入。为了实现不同的难度模式,作者将难度编码为一个标量(初级是 10,中级是 20,以此类推)并将这个值作为新特征附加到 convstack 的输出中。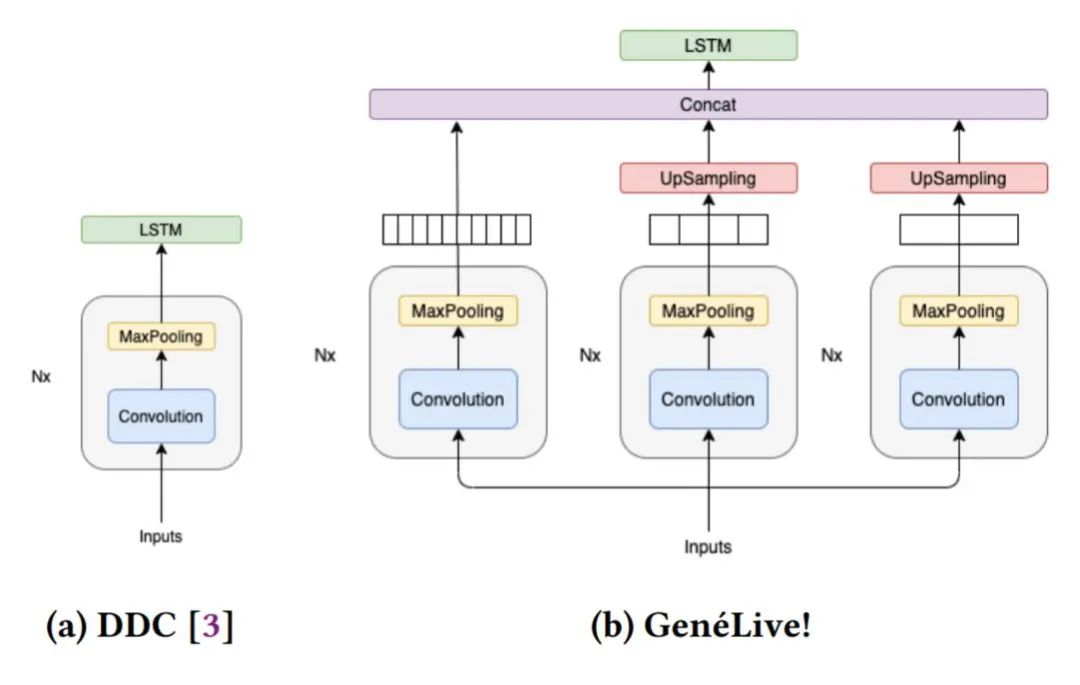
在训练数据方面,GenéLive! 使用了几百首早期的 LLAS 歌曲,《歌之王子殿下》的歌曲,以及音乐游戏引擎「Stepmania」中可公开访问的音乐和乐谱。该模型是由 KLab 和九州大学合作完成的。两个团队之间需要一个基于 Web 的协作平台来共享源代码、数据集、模型和实验等。具体来说,该研究用于模型开发的系统架构如下图所示。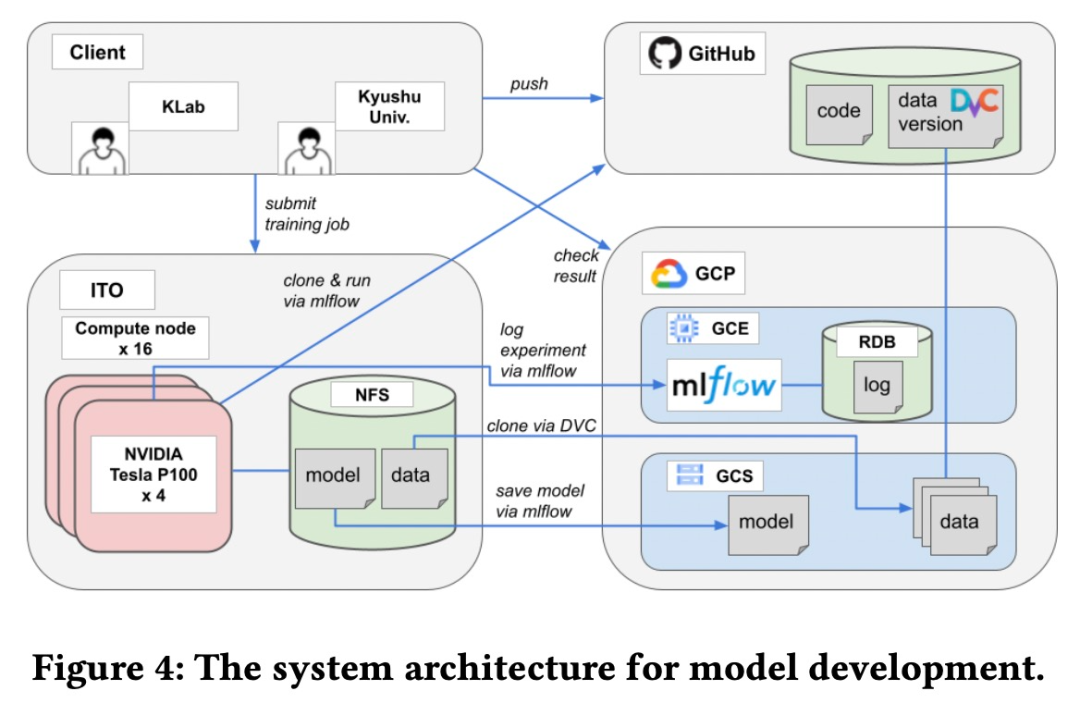
为了使乐谱生成程序可供艺术家按需使用,它应该方便艺术家自行使用而无需 AI 工程师的帮助。并且由于该程序需要高端 GPU,将其安装在艺术家的本地计算机上并不是一个合适的选择。该模型服务系统架构如下图所示。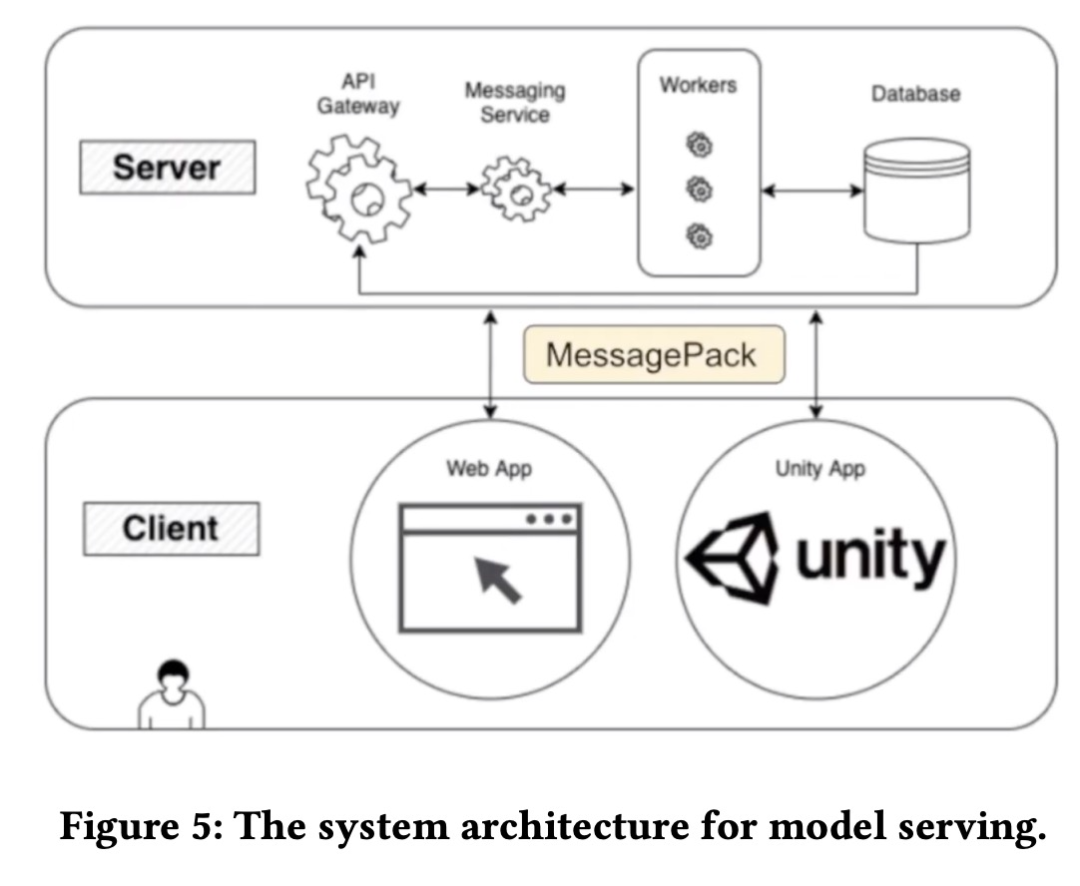
为了度量该方法中每个组件的性能,研究者在「Love Live! All Stars」数据集上进行了消融实验。下表 3 的结果表明 GenéLive! 模型优于此前的 SOTA 模型 DDC。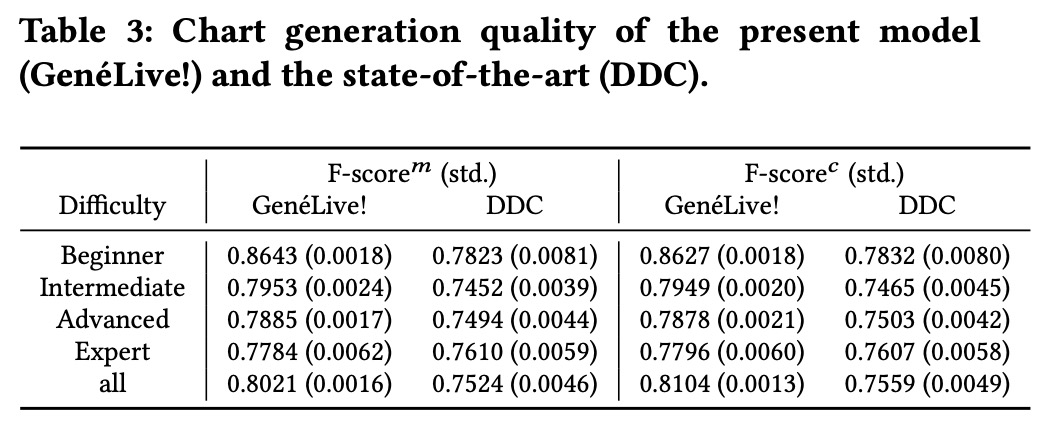
为了评估节拍指导的作用,消融实验的结果如下图 9 所示。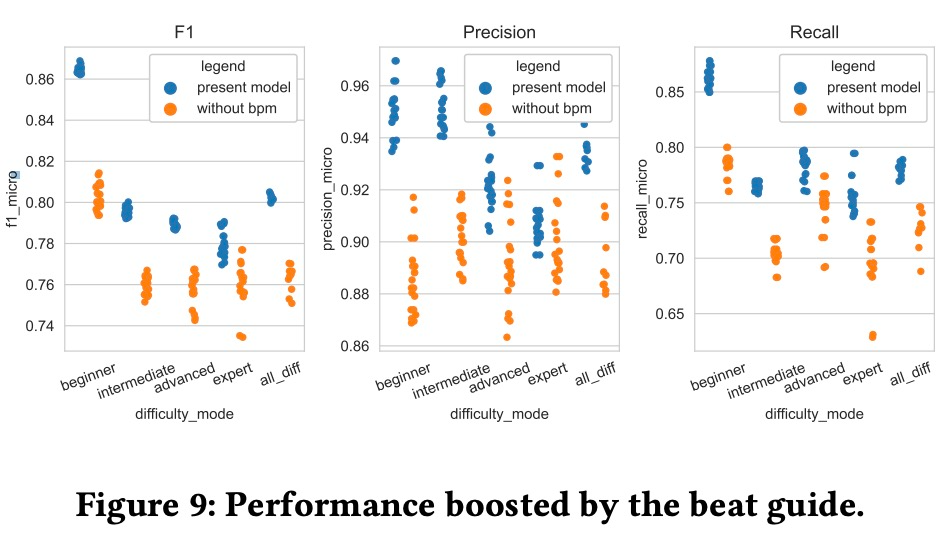
使用未修改版 conv-stack 训练模型和当前 GenéLive! 模型的结果差异如下图所示。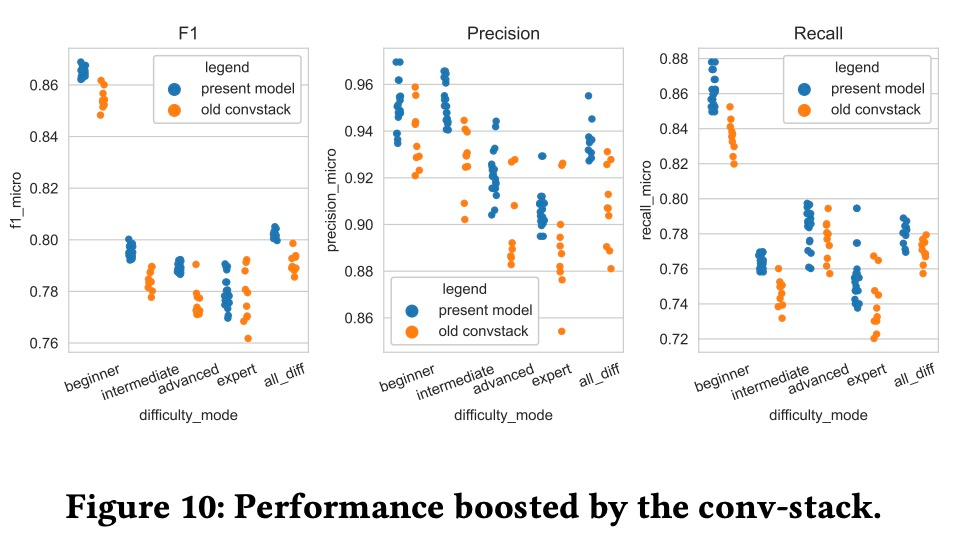
GenéLive! 模型一次性训练全部难度模式,为了查看这种训练方式的优势。该研究将其与每种难度模式单独训练的结果进行了比较,结果如下图所示。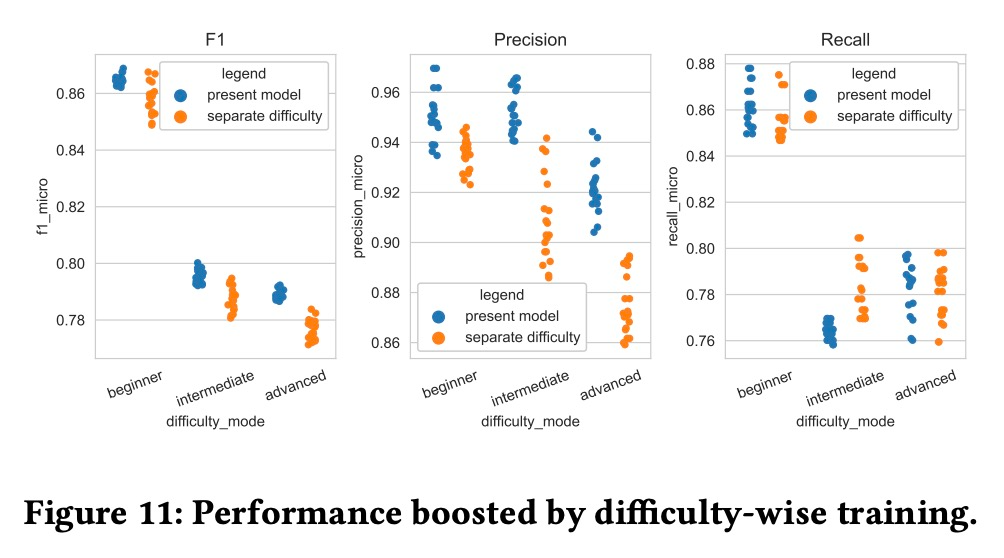
LoveLive! 企划的活动范围包括动漫、游戏和真人偶像团体。音乐游戏《Love Live! School Idol Festival》自 2013 年开始运营,截至 2019 年 9 月在日本拥有超过 2500 万用户。新一代的游戏《Love Live! School Idol Festival All Stars》目前在全球已有上千万用户。
GenéLive! 的研究,说不定也能让音游在 AI 领域里火起来。© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

 下载APP
下载APP