
当自动驾驶遇上GPT-4V:L4要解决了?
本文转自知乎https://zhuanlan.zhihu.com/p/660940512,原作者保留版权
万众瞩目之下,今天GPT4终于推送了vision相关的功能。今天下午抓紧和小伙伴一起测试了一下GPT对于图像感知的能力,虽有预期,但是还是大大震惊了我们。TL;DR 就是我认为自动驾驶中和语义相关的问题应该大模型都已经解决得很好了,但是大模型的可信性和空间感知能力方面仍然不尽如人意。解决一些所谓和效率相关的corner case应该是绰绰有余,但是想完全依赖大模型去独立完成驾驶保证安全性仍然十分遥远。
Example1: 路上出现了一些未知障碍物

输入图片

GPT4的描述
准确的部分:检测到了3辆卡车,前车车牌号基本正确(有汉字就忽略吧),天气和环境正确,在没有提示的情况下准确识别到了前方的未知障碍物
不准确的部分:第三辆卡车的位置左右不分,第二辆卡车头顶的文字瞎猜了一个(因为分辨率不足?)
这还不够,我们继续给一点提示,去问这个物体是什么,是不是可以压过去。
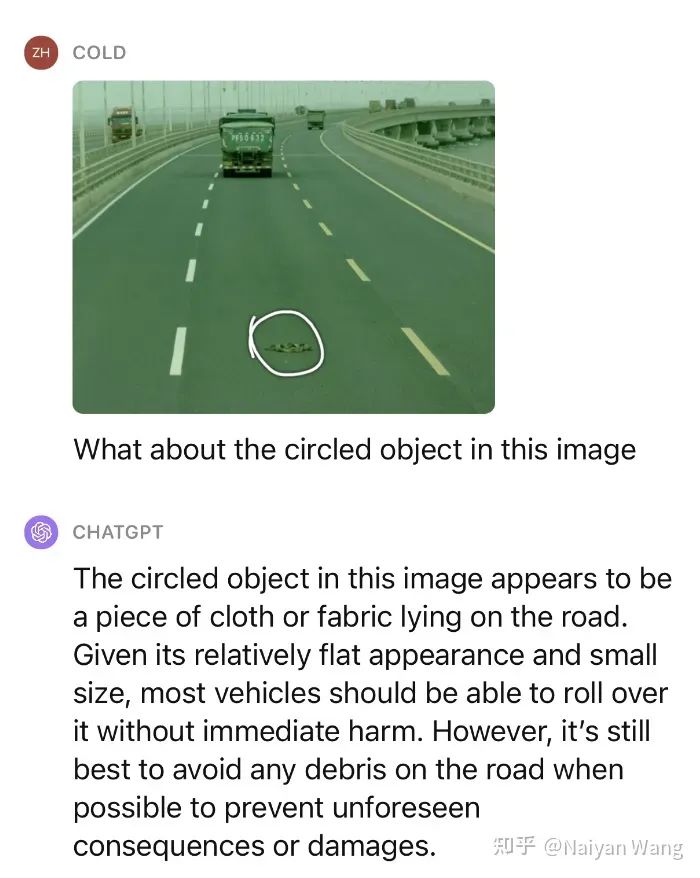
Impressive!类似的场景测试了多个,对于未知障碍物的表现可以说非常惊人了。
Example2: 路面积水的理解
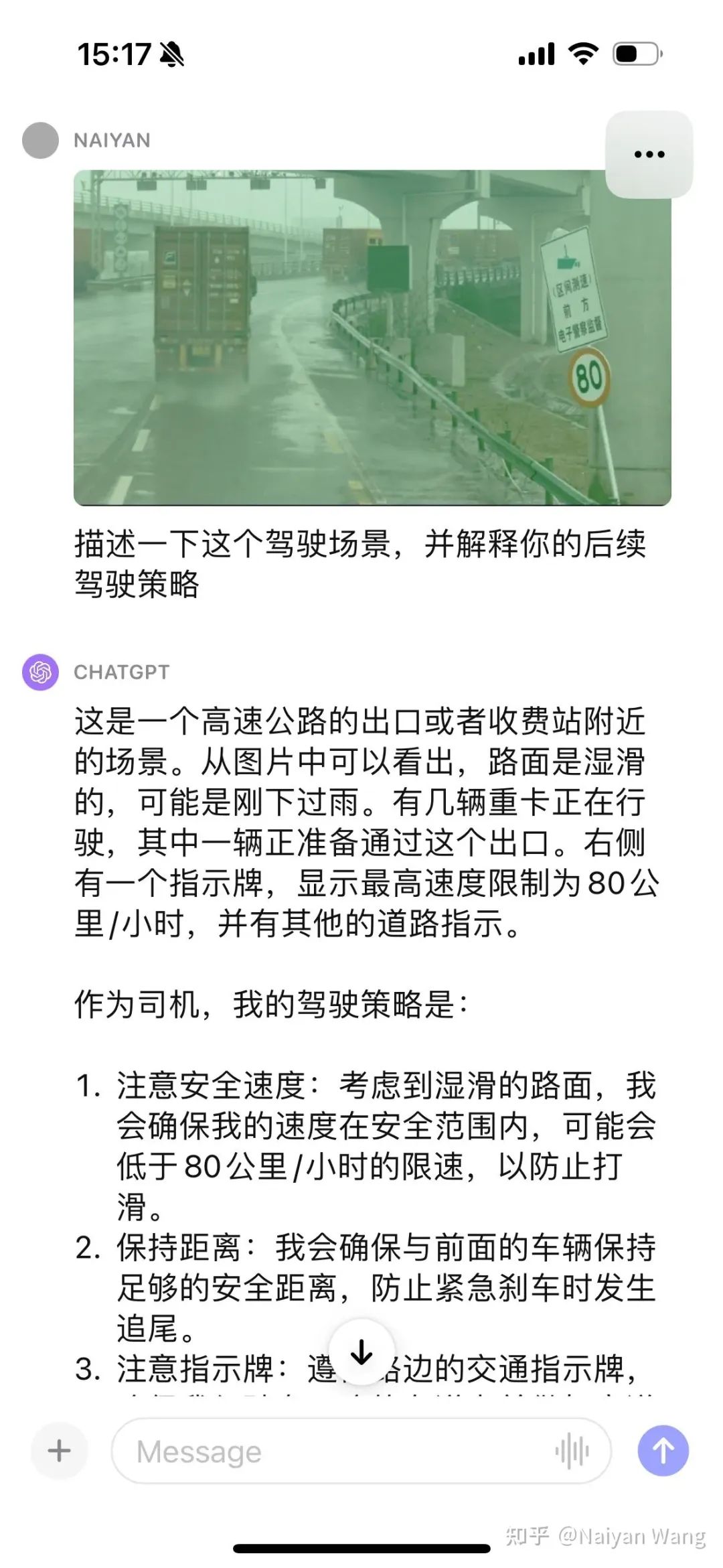
没有提示能自动识别到标牌这个应该是基操了,我们继续给一些hint

再次被震惊了。。。能自动讲出来卡车背后的雾气,也主动提到了水坑,但是再一次把方向说成了左侧。。。感觉这里可能需要一些prompt engineering能更好的让GPT输出位置和方向。
Example3:有车辆掉头时直接撞上了护栏

第一帧输入进去,因为没有时序信息,只是将右侧的卡车当做是停靠的了。于是再来一帧:

已经可以自动讲出,这两撞破了护栏,悬停在公路边缘,太棒了。。。但是反而看上去更容易的道路标志出现了错误。。。只能说,这很大模型了,它永远能震惊你也永远不知道什么时候能蠢哭你。。。再来一帧:

这次,直接讲到了路面上的碎片,再次赞叹。。。只不过有一次把路上的箭头说错了。。。总体而言,这个场景中需要特别关注的信息都有覆盖,道路标志这种问题,瑕不掩瑜吧
Example4: 来一个搞笑的

只能说非常到位了,相比之下之前看上去无比困难的“有个人冲着你挥了挥手”这样的case就像小儿科一样,语义上的corner case可解。
Example5 来一个名场面。。。配送车误入新修路
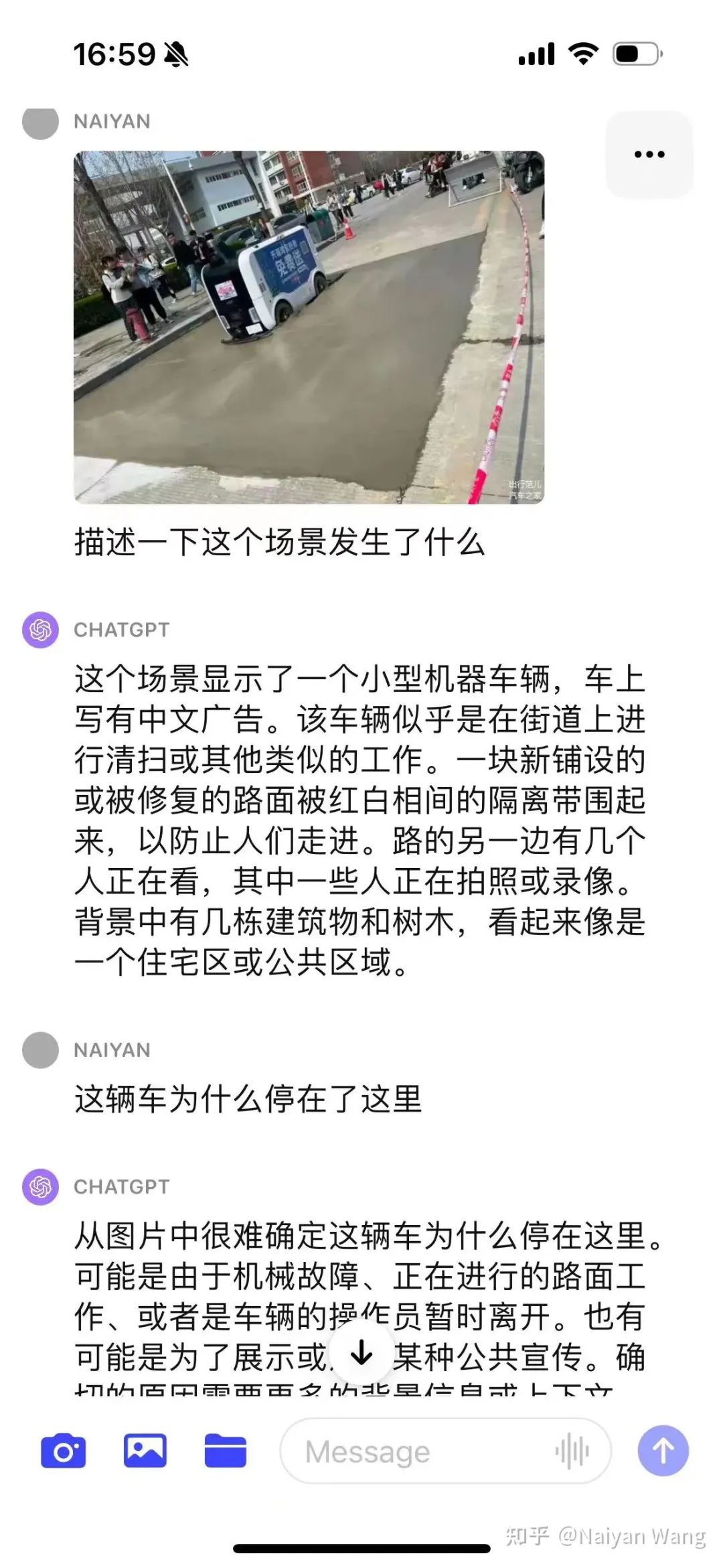



开始比较保守,并没有直接猜测原因,给了多种猜测,这个也倒是符合alignment的目标。使用CoT之后问题发现问题是在于并不了解这辆车是个自动驾驶车辆,故通过prompt给出这个信息能给出比较准确的信息。最后通过一堆prompt,能够输出新铺设沥青,不适合驾驶这样的结论。最终结果来说还是OK,但是过程比较曲折,需要比较多的prompt engineering,要好好设计。这个原因可能也是因为不是第一视角的图片,只能通过第三视角去推测。所以这个例子并不十分精确。
总结
快速的一些尝试已经完全证明了GPT4V的强大与泛化性能,适当的prompt应当可以完全发挥出GPT4V的实力。解决语义上的corner case应该非常可期,但幻觉的问题会仍然困扰着一些和安全相关场景中的应用。非常exciting,个人认为合理使用这样的大模型可以大大加快L4乃至L5自动驾驶的发展,然而是否LLM一定是要直接开车?尤其是端到端开车,仍然是一个值得商榷的问题。最近也有很多思考,找时间再来写个文章和大家聊聊~
往期精彩回顾
交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)