
当BERT遇上搜索引擎

前两天刷到一篇有意思的paper,文中将信息检索工具Anserini和BERT结合,实现了一个开放域的问答系统。
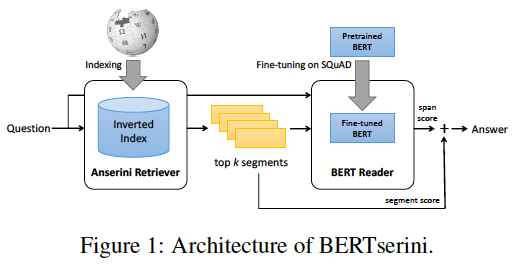
如图所示,论文的主要创新点是将BERT和Anserini整合,利用外部知识库(维基百科)辅助实现QA问答。原文发表在NLP顶会NAALC 2019上。
论文题目:
End-to-End Open-Domain Question Answering with BERTserini
论文链接:
https://arxiv.org/abs/1902.01718
01 背景
首先,作者收集了5.08M的维基百科文章,拆分成段落和句子。对文章、段落、句子分别构建index索引。
其次,将预训练好的BERT在阅读理解数据集SQuAD上微调,作为文本编码器。
对于一个新的问题,通过搜索引擎返回topK篇关联性最强的候选文档,然后文档和问题一起输入微调后的BERT计算得分。取分数最高的文本片段,作为最终答案。
整个问答系统的思路非常简单。通过引入维基百科等外部信息,自动挖掘开放域问题的答案。
值得注意的是,文本片段的最终得分如何计算?

文中方法是由搜索系统和BERT分数的线性组合决定。其中
就是这么简单粗暴!作者也在文末表示,直接加权输出不够全面。

02 实验
论文主要包含了两方面的实验。
检索粒度
在检索时,对哪一种粒度的文本进行筛选非常关键。因为文章、段落、句子包含的信息量明显不同。
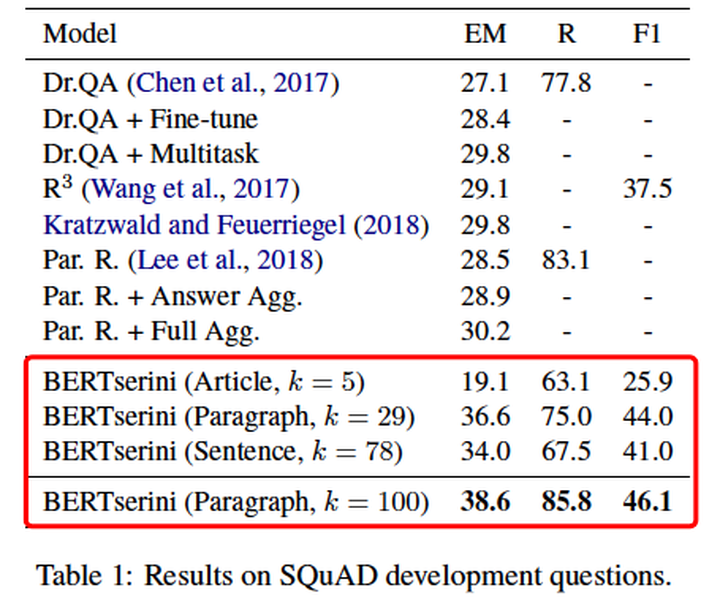
实验发现,将段落作为索引对象,效果是最好的。
这样的结果应该符合我们的认知。因为一篇文章包含的内容太宽泛,绝大多数与用户问题无关。而一个句子的信息量太少,缺乏上下文,BERT无法准确识别出答案片段。
作者统计发现一个段落平均包含2.7个句子,一篇文章平均包含5.8个段落,所以针对不同粒度文本设置了不同的K值。
K值选择
K值越大,传输给BERT的数据越多,直观上看文本中包含正确答案的可能性越高。
基于段落索引,作者测试了召回率、完全匹配率(EM)变化。
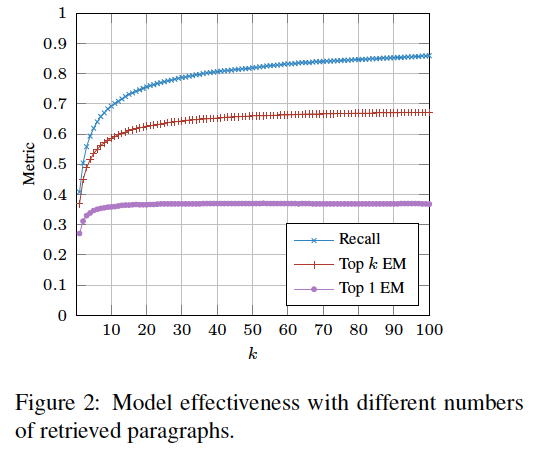
召回率,是检索的K个段落中包含正确答案的概率。显然K越大,召回率越高。
Topk完全匹配率,指BERT依次从K个段落中识别答案,最终包含正确答案的概率。
Top1完全匹配率,指BERT依次从K个段落中识别答案,分数最高的片段是正确答案的概率。
召回率代表了模型识别准确度的上界。召回率与Topk EM的间隔,表示BERT潜在的提升空间。Topk EM与Top1 EM的间隔,表示需要寻找更有效的得分计算方法。
03 演示
作者将BERTserini模型部署为一个聊天机器人。

第一个问题来自SQuAD验证集,其余3个是作者自定义的问题,以展示bot可以回答问题的范围。

BERTserini 先根据问题,从维基百科中检索最相关的K个段落(基于BM25),然后用微调的BERT定位答案span。最后,将答案所在的句子返回前端展示。
04 总结
本文用搜索引擎+预训练语言模型这种两阶段的方式,实现了一个问答系统。
搜索引擎结合外部知识库(维基百科、百度词条、谷歌搜索等),相比于垂直领域,信息来源更丰富了。因而模型可以回答一些开放域的问题。
整体思路还是比较灵活的。当然论文中的做法比较粗暴,无论是搜索引擎还是BERT,以及score的计算方式上,都还有提升空间。
推 荐 阅 读
原创不易,有收获的话请帮忙点击分享、点赞、在看吧🙏