
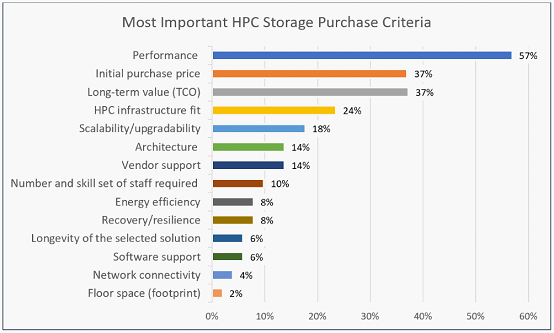
干货:该从哪些关键指标衡量HPC存储系统?


对高性能计算存储系统的购买者来说,总拥有成本(TCO)通常被认为是一个重要的考虑因素。由于HPC用户对TCO的定义不同,因此很难根据预定义的一组属性进行比较。

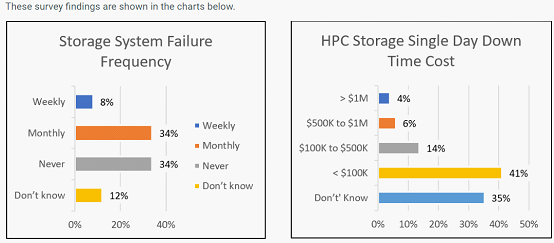
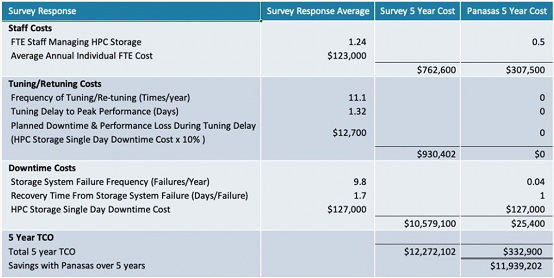
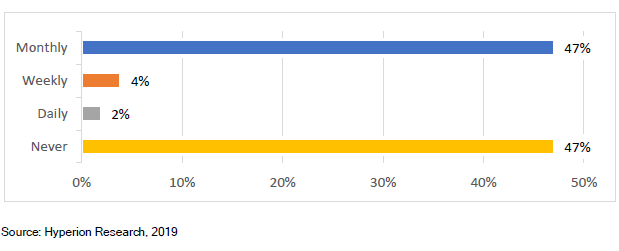
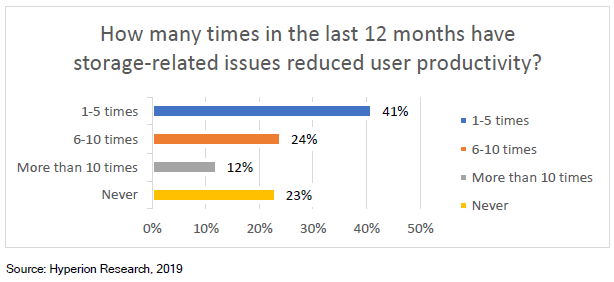
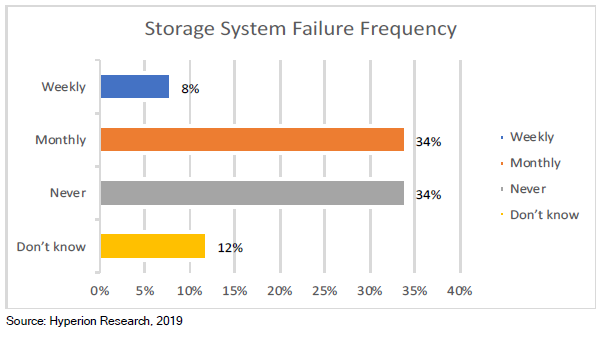
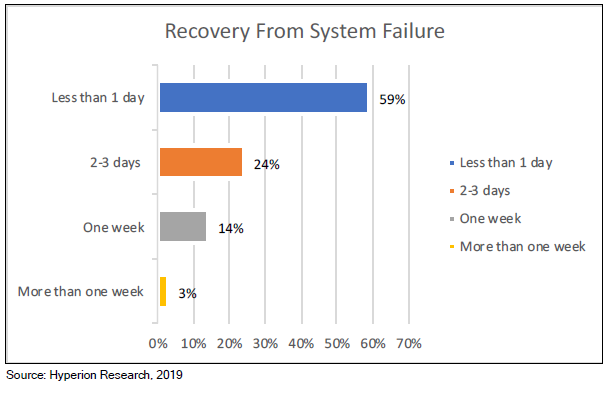
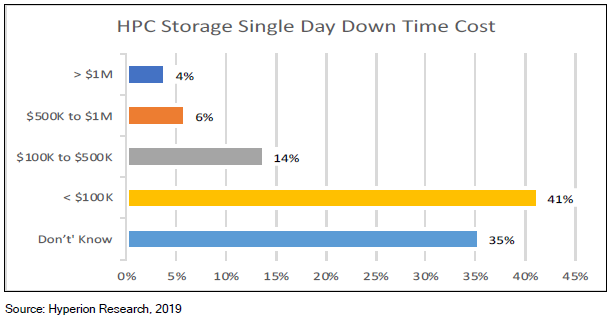
被调查的网站中,近50%的站点存储系统每月会出现一次故障,甚至更频繁。 停机时间从不到一天到一周以上,一天的停机成本从10万美元到100多万美元不等。
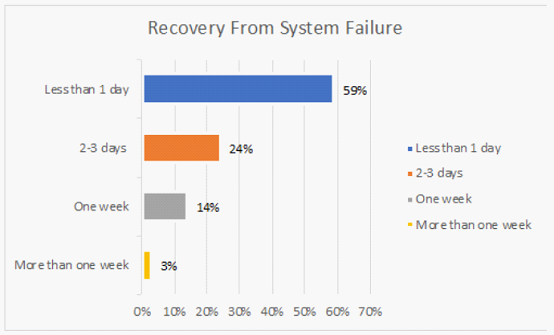
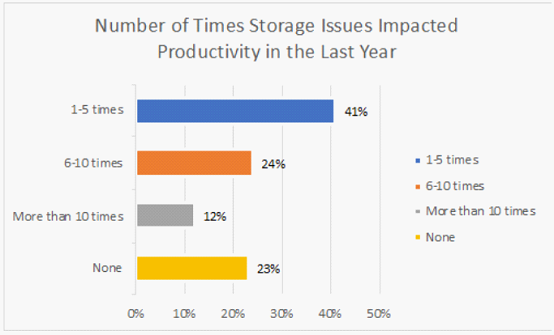
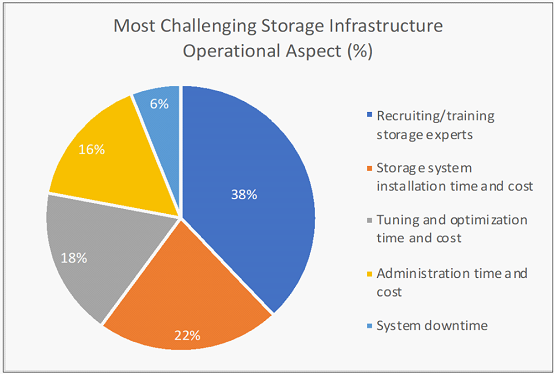
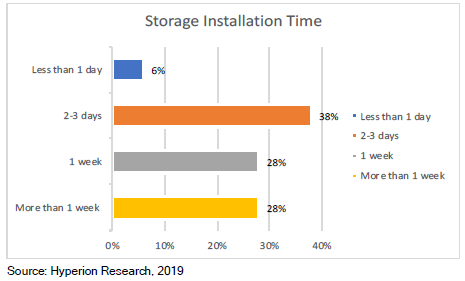
存储专家招聘/培训:Lustre、GPFS和BeeGFS文件系统需要专门的存储专业知识,而这些专业知识很难学习和积累。Panasas PanFS并行文件系统不需要任何深厚的技术技能即可进行日常管理。 存储系统安装时间和成本:根据调查,有56%的存储系统需要数周的时间安装,Panasas系统通常一天即可完成安装。 调优和优化时间和成本:Panasas PanFS几乎不需要人工和技术密集的调优即可保持最佳性能,因此保证存储系统的每个部分(CPU,NIC,DRAM和存储介质)处于均衡和优化状态,各种工作负载的性能可预测,无需手动调整或重新配置。 系统管理时间和成本:无论规模大小,60%的站点需要一位以上的专业人员来管理其存储系统,Panasas存储通常只需要一名兼职管理员来管理。 系统停机时间:42%的受访者表示每周或每月都有停机发生。Panasas现网部署案例已证明长达8年无计划外停机事件发生。
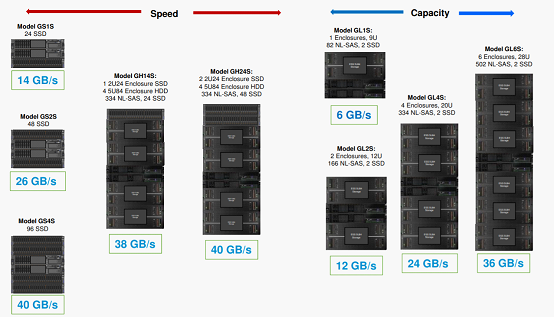
Panasas认为Panasas可以在性价比方面满足最苛刻的HPC存储要求。PanFS的系统的性能大约是Lustre,GPFS和BeeGFS类似配置系统的两倍。因此,HPC组织无需在性能和价格之间进行权衡。


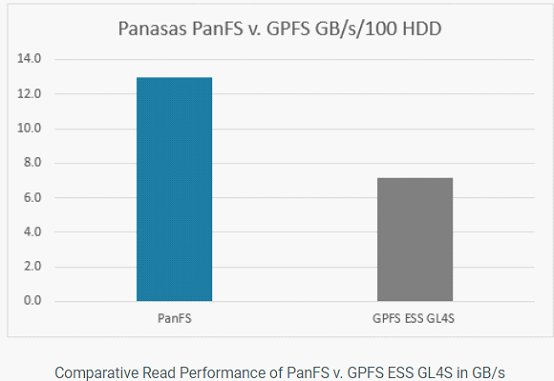
1)、IBM Spectrum Scale(GPFS)性能对比
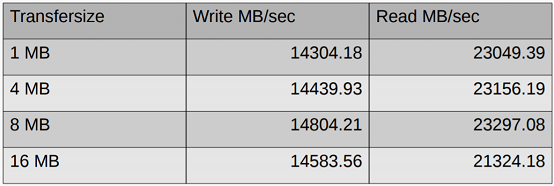
小文件存储在低延迟闪存SSD上 大文件存储在低成本,大容量,高带宽的HDD上 元数据存储在低延迟NVMe SSD上 数据和元数据操作以NVDIMM内部日志方式执行 未修改的数据和元数据存储在DRAM中
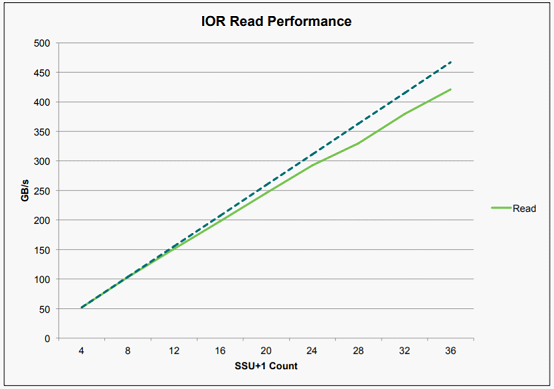
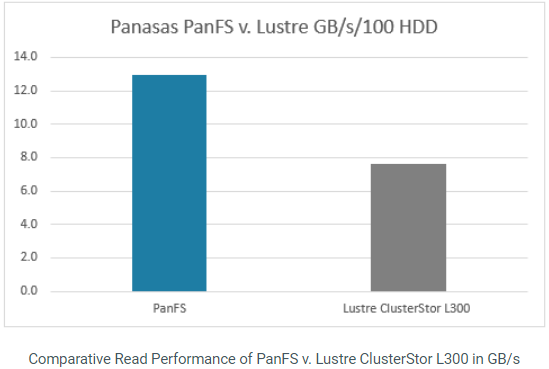
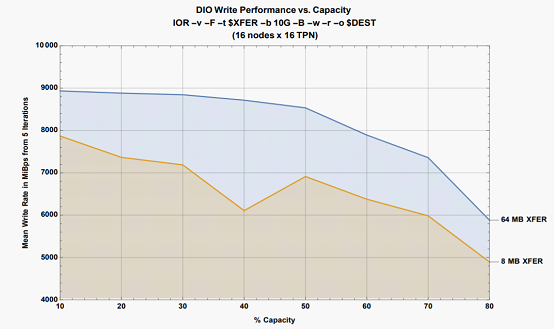

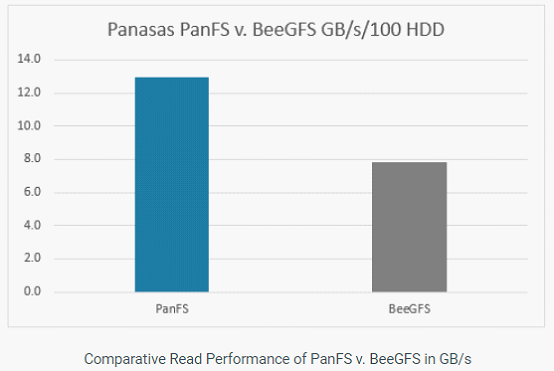
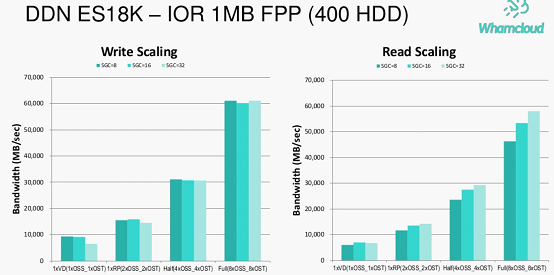

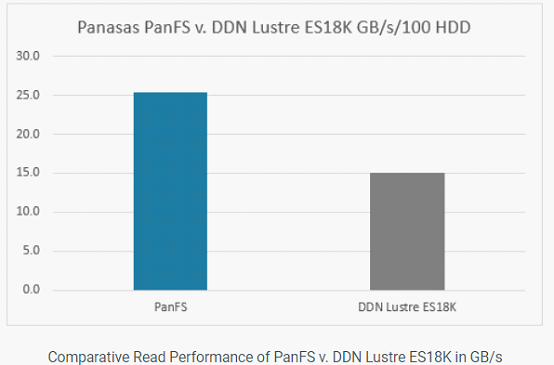
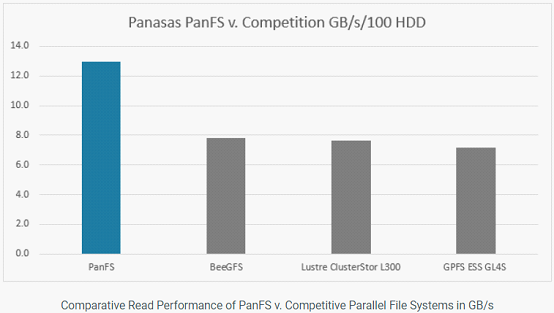
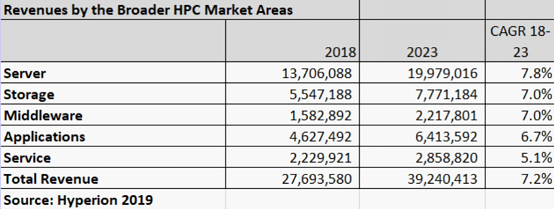
以下内容将对Hyperion Research原报告数据解读,对HPC存储、传统存储存在问题进行剖析,以及分析下构建AI和HPC存储系统6大要素。
1、没有性能限制(扩展性):HPC存储解决方案在扩展时应该没有性能限制,无论是Scale Out还是Scale Up架构。因此性能按需扩展可以快速解决不断变化的存储需求,通过灵活扩展系统,快速发挥每个节点全部性能价值。 2、始终如一的高性能(性能一致):无论数据,应用程序,用户和工作负载的复杂性如何,都提供始终如一的快速存储。 3、智能数据放置(数据多层布局):多层智能数据布局架构,为不同数据类型匹配正确的存储类型,元数据和数据的独立存放,数据路径并行,无瓶颈。充分发挥不同存储介质性能特征,以最低的成本提供最高的性能。 4、易于部署,管理和扩展(TCO):存储易于操作,即插即用,不需要深入的技术技能来管理。系统管理员应该能够在几秒钟内完成容量和性能配置和扩展,一个IT管理员可以处理任何规模的存储系统。 5、可靠(系统Down机率):HPC存储的可靠性随规模而加剧,存储应该自动从故障中恢复,并且没有单点故障。智能软件(AI或机器学习)可以自动协调恢复和修复过程。 6、系统自动调优(系统自调优):系统调优需深厚存储系统知识,熟悉存储系统工作方式。人工调优耗时、复杂且容易出错,存储系统需要具备自我调优能力,系统一旦经过调优,就可以优化绝大多数HPC应用的性能,而不需要随着工作负载的变化而重新进行调整。
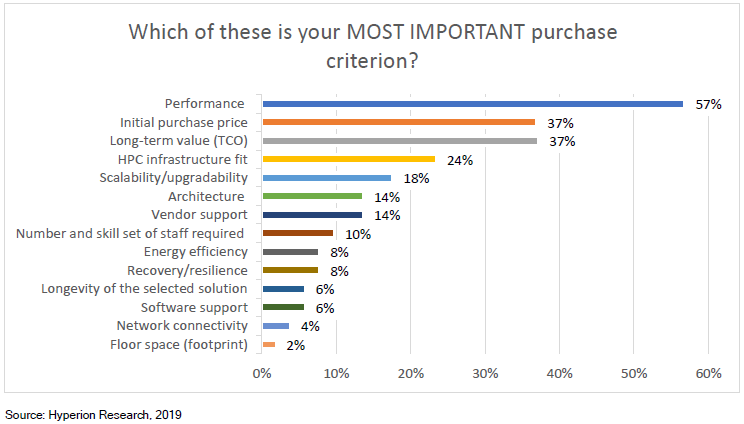
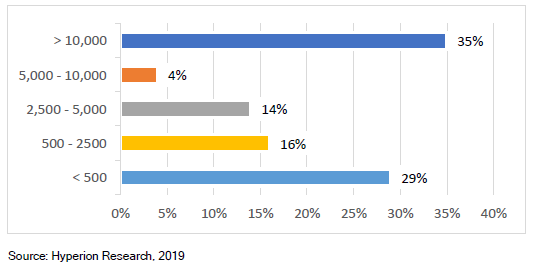
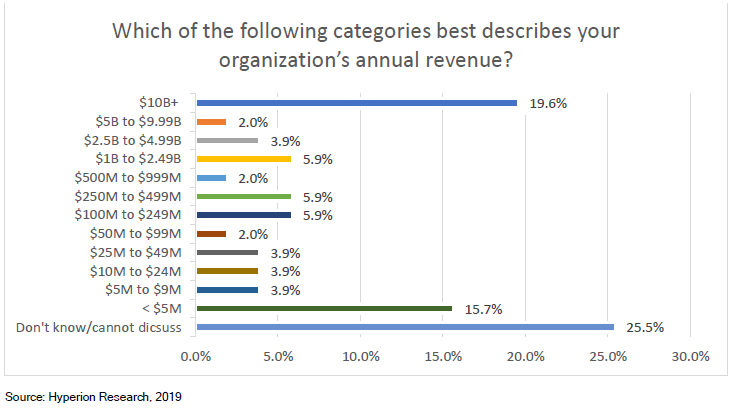
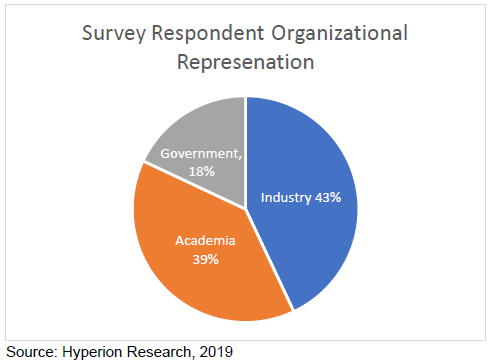
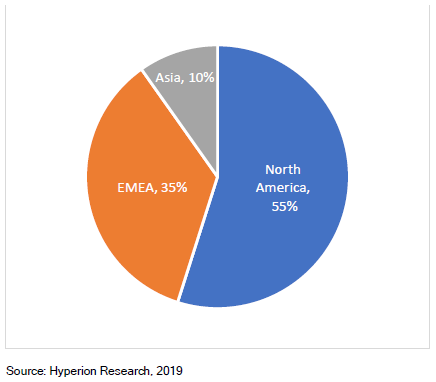
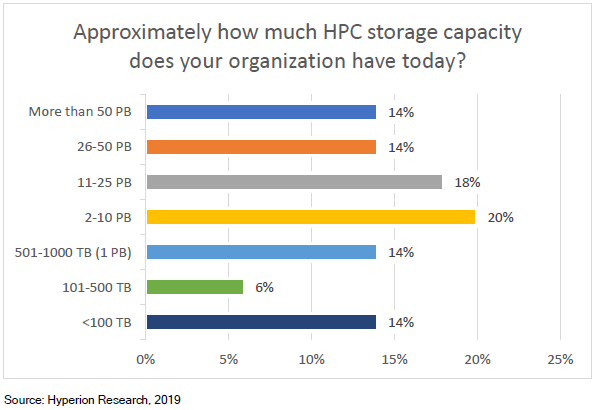
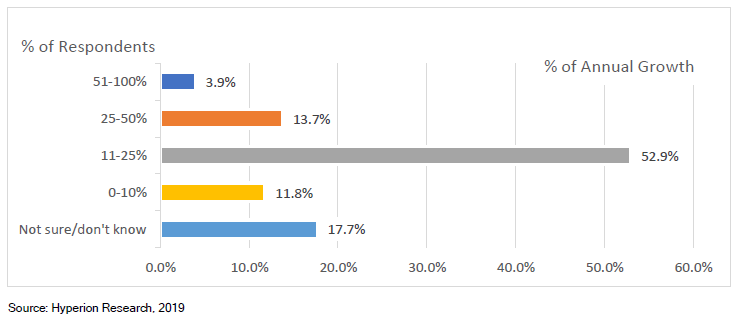
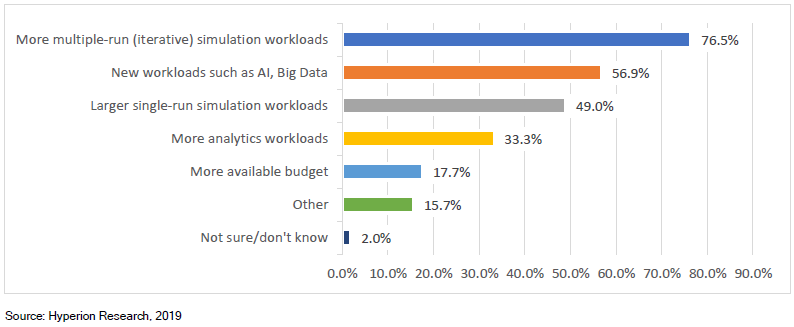
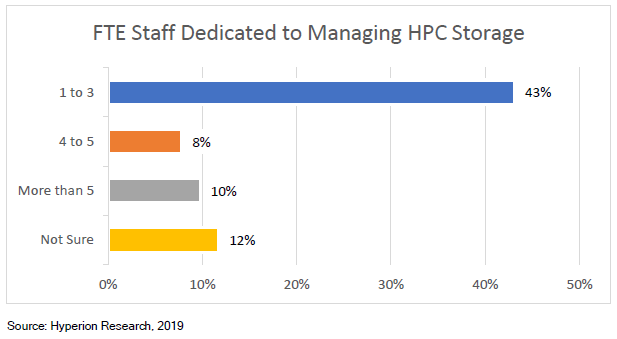
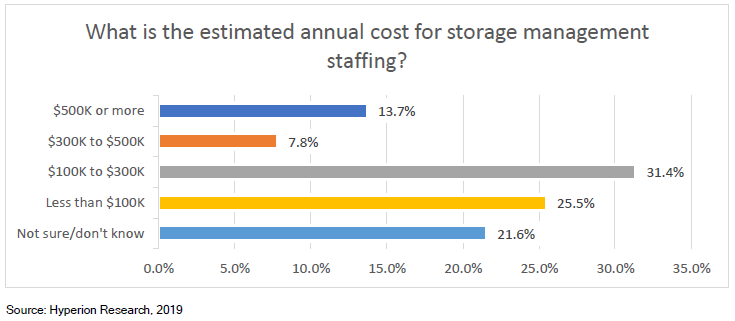
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,价格仅收188元(原总价290元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。

评论