
爬虫系列 | 基于百度爬虫的非百度搜索引擎
点击上方 月小水长 并 设为星标,第一时间接收干货推送
这是本项目的开篇,在这个小项目中,将要基于爬虫和GUI编程写一个写个小工具,目的是不用打开浏览器,也能搜到一些关键信息,并将这些信息持久化保存下来,读者可以对这些数据进行分析,比如舆情分析,或作为 NLP 的语料输入。
众所周知,搜索引擎的一个核心技术就是爬虫技术,各大搜索引擎的爬虫将个网站的快照索引起来 ,用户搜索时,输入关键词并回车后,基于搜索引擎的浏览器就将相关信息按照一定排序规则展现给用户,今天分享的这个爬虫,是爬取百度爬虫爬取的内容,听起来,有点像俄罗斯套娃。
话不多说,先用一张图,说明要爬取的内容
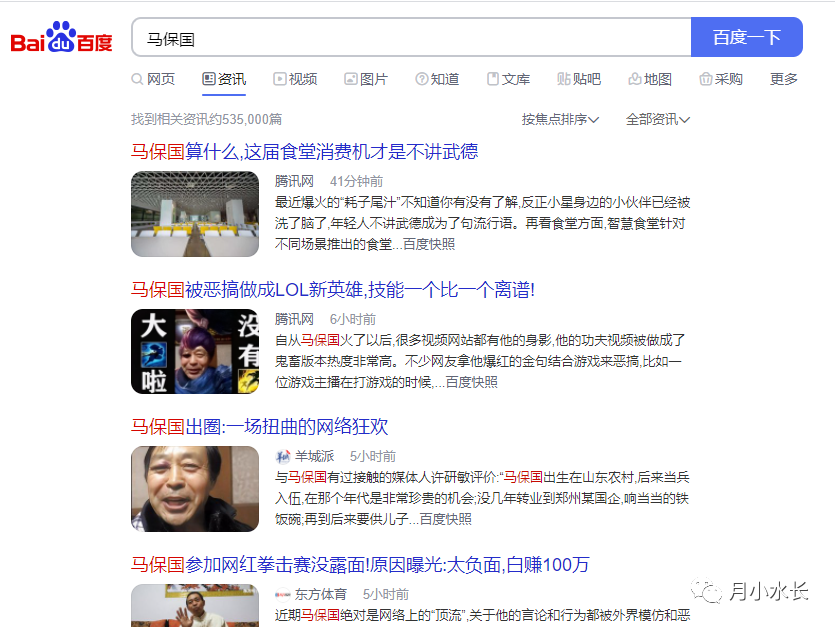
如图,爬取的目标是百度咨询下的每一条内容,包括标题、来源、时间和内容,并且翻页爬取、爬完能够自动停止,而且能够按照焦点/时间排序。
经过调试分析,发现排序规则和参数 rtt 相关,rtt = 1 是按照焦点排序,rtt = 4 是按照时间排序,这样就很容易解决排序抓取的问题。
翻页只需要控制 pn 参数即可,其值等于当前页码 * 10;爬完自动停止,首先要知道什么时候爬完,从上面图中可以发现,网页上有“找到相关资讯约535,000篇”,好家伙,除以每页 10 篇,总页数就知道了,就知道什么时候停止了。
下面就是写代码逐渐实现的过程了。
首先备好爬虫的原料
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Referer': 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=%B0%D9%B6%C8%D0%C2%CE%C5&fr=zhidao'
}
url = 'https://www.baidu.com/s'
params = {
'ie': 'utf-8',
'medium': 0,
# rtt=4 按时间排序 rtt=1 按焦点排序
'rtt': 1,
'bsst': 1,
'rsv_dl': 'news_t_sk',
'cl': 2,
'tn': 'news',
'rsv_bp': 1,
'oq': '',
'rsv_btype': 't',
'f': 8,
}
然后稍微小炒一下,拿到总篇数,但是不能浪费这次请求,毕竟这个页面上也有 10 篇文章需要解析,所以第一次请求的目的是拿到停止条件同时解析前 10 篇,注意它和后面的请求处理过程多了拿到总篇数这个过程,所以不放在后面的循环里。
response = requests.get(url=url, params=params, headers=headers)
html = etree.HTML(response.text)
dealHtml(html)
total = html.xpath('//div[@id="header_top_bar"]/span/text()')[0]
total = total.replace(',', '')
total = int(total[7:-1])
pageNum = total // 10
但是它的每条新闻解析过程,和后面都是一样的,都在 dealHtml 中,注意函数中 parseTime
def dealHtml(html):
results = html.xpath('//div[@class="result-op c-container xpath-log new-pmd"]')
saveData = []
for result in results:
title = result.xpath('.//h3/a')[0]
title = title.xpath('string(.)').strip()
summary = result.xpath('.//span[@class="c-font-normal c-color-text"]')[0]
summary = summary.xpath('string(.)').strip()
# ./ 是直接下级,.// 是直接/间接下级
infos = result.xpath('.//div[@class="news-source"]')[0]
source, dateTime = infos.xpath(".//span[last()-1]/text()")[0], \
infos.xpath(".//span[last()]/text()")[0]
dateTime = parseTime(dateTime)
print('标题', title)
print('来源', source)
print('时间', dateTime)
print('概要', summary)
print('\n')
saveData.append({
'title': title,
'source': source,
'time': dateTime,
'summary': summary
})
for page in range(1,pageNum):
print('第 {} 页\n\n'.format(page))
headers['Referer'] = response.url
params['pn'] = page*10
response = requests.get(url=url,headers=headers,params=params)
html = etree.HTML(response.text)
dealHtml(html)
sleep(randint(2,4))
很快啊,最后就是出锅了,这道菜的名称叫做,耗子尾汁,请君享用
with open(fileName, 'a+', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
for row in saveData:
writer.writerow([row['title'], row['source'], row['time'], row['summary']])
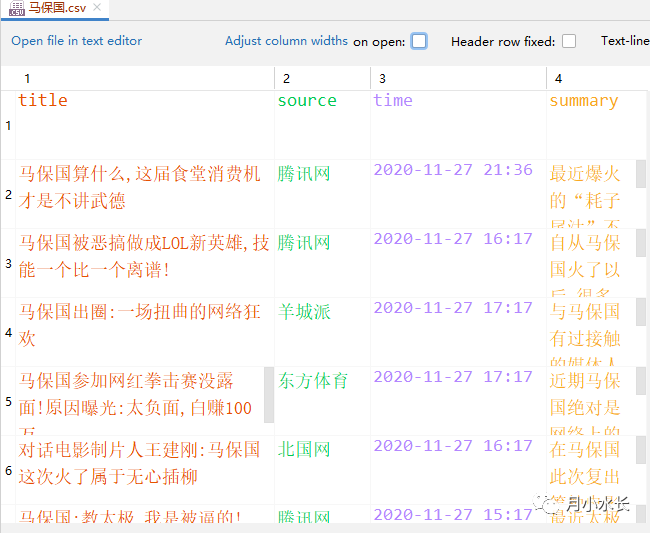
言归正传,本次项目的第一部分:百度爬虫的爬虫,就算完成了,爬虫所有代码的 github 地址如下:
https://github.com/Python3Spiders/BaiduSpider
(点击文末 阅读原文 可直达)
本项目的下一部分,等我找好朝天椒,再爆炒上桌,莫急莫急。
往期精选