
python 爬虫 打造【百度翻译】

环境
| python版本号 | 系统 | 游览器 |
|---|---|---|
| python 3.7.2 | win7 | google chrome |
关于本文
本文将会通过爬虫的方式实现简单的百度翻译。本文中的代码只供学习,不允许作为于商务作用。商务作用请前往api.fanyi.baidu.com购买付费的api。若有侵犯,立即删文!
实现思路
在网站文件中找到隐藏的免费api。传入api所需要的参数并对其发出请求。在返回的json结果里找到相应的翻译结果。
百度翻译的反爬机制
由js算法生成的sign
cookie检测
token暗号
在网站文件中找到隐藏的免费api
进入 百度翻译 ,随便输入一段需要翻译的文字。当翻译结果出来的时候,按下F12,选择到NETWORK,最后点进XHR文件。这个时候,网站文件都已经加载完了,所以要F5刷新一下。

刷新了之后,我们就能发现一个以v2transapi?开头的文件,没错,它就是我们要找的api接口。让我们验证一下,点进去文件-preview,我们就可以在json格式的数据里面找到翻译结果,验证成功。
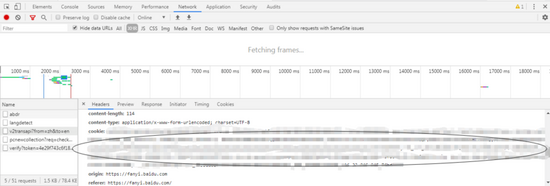
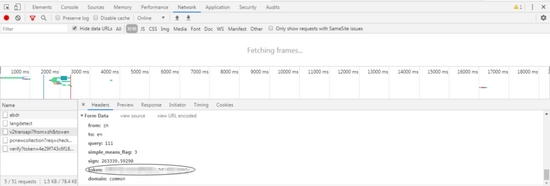
另外,我们还需要获取我们的cookie和token,在之后的反爬机制中我们需要用到它们,位置如以下。
cookie位置:
token位置:
api信息
接口:https://fanyi.baidu.com/v2tra...
请求方式:post
请求参数大全
| 参数 | 介绍 |
|---|---|
| from | 源语言 |
| to | 目标语言 |
| query | 翻译文本 |
| sign | 由js算法生成的签名(反爬) |
| token | 请求暗号 |
开始写代码
导入request和execjs库
requests
execjs
requests HTTP库,用于爬虫
execjs 用于调用js代码
反爬虫
由于百度翻译有cookie识别反爬机制,所以我们设置好我们刚刚获取到的cookie来进行掩护网络蜘蛛身份。
headers = {'cookie':'请在这里输入你的cookie'}另外,我们还要设置好token(暗号)。
token = '请在这里放置你的token'
最后只剩下sign反爬机制了,sign是由js算法给译文生成的一个签名。我在网上搜了一下,找到了相应的js算法,分享给大家。
i =
(r, o) {
( t = ; t < o.length - ; t += ) {
a = o.charAt(t + );
a = a >= ? a.charCodeAt() - : (a), a = === o.charAt(t + ) ? r >>> a : r << a, r = === o.charAt(t) ? r + a & : r ^ a
}
r
}
(r) {
o = r.match();
( === o) {
t = r.length;
t > && (r = + r.substr(, ) + r.substr(.floor(t / ) - , ) + r.substr(, ))
} {
( e = r.split(), C = , h = e.length, f = []; h > C; C++) !== e[C] && f.push.apply(f, a(e[C].split())), C !== h - && f.push(o[C]);
g = f.length;
g > && (r = f.slice(, ).join() + f.slice(.floor(g / ) - , .floor(g / ) + ).join() + f.slice().join())
}
u = , l = + .fromCharCode() + .fromCharCode() + .fromCharCode();
u = !== i ? i : (i = [l] || ) || ;
( d = u.split(), m = (d[]) || , s = (d[]) || , S = [], c = , v = ; v < r.length; v++) {
A = r.charCodeAt(v);
> A ? S[c++] = A : ( > A ? S[c++] = A >> | : ( === ( & A) && v + < r.length && === ( & r.charCodeAt(v + )) ? (A = + (( & A) << ) + ( & r.charCodeAt(++v)), S[c++] = A >> | , S[c++] = A >> & | ) : S[c++] = A >> | , S[c++] = A >> & | ), S[c++] = & A | )
}
( p = m, F = + .fromCharCode() + .fromCharCode() + .fromCharCode() + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()), D = + .fromCharCode() + .fromCharCode() + .fromCharCode() + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()) + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()), b = ; b < S.length; b++) p += S[b], p = n(p, F);
p = n(p, D), p ^= s, > p && (p = ( & p) + ), p %= , p.toString() + + (p ^ m)
}
等等,我们不是在用python进行爬虫吗?那我们又不会js代码,怎么调用啊?
还好python有着强大的第三方库,当然也少不了调用js代码的库。调用js代码的库很多,但是本人还是推荐大家使用execjs,简单功能又完整。
在调用js算法代码之前,我们还需要让用户输入一段译文。
q = input('翻译:')之后我们就能使用execjs的compile和call方法来获取sign了。
js =
n(r, o) {
(var t = ; t < o.length - ; t += ) {
var a = o.charAt(t + );
a = a >= ? a.charCodeAt() - : Number(a), a = === o.charAt(t + ) ? r >>> a : r << a, r = === o.charAt(t) ? r + a & : r ^ a
}
return r
}
e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
( === o) {
var t = r.length;
t > && (r = + r.substr(, ) + r.substr(Math.floor(t / ) - , ) + r.substr(, ))
} {
(var e = r.(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = , h = e.length, f = []; h > C; C++) !== e[C] && f.push.apply(f, a(e[C].())), C !== h - && f.push(o[C]);
var g = f.length;
g > && (r = f.slice(, ).() + f.slice(Math.floor(g / ) - , Math.floor(g / ) + ).() + f.slice().())
}
var u = void , l = + .fromCharCode() + .fromCharCode() + .fromCharCode();
u = !== i ? i : (i = window[l] || ) || ;
(var d = u.(), m = Number(d[]) || , s = Number(d[]) || , S = [], c = , v = ; v < r.length; v++) {
var A = r.charCodeAt(v);
> A ? S[c++] = A : ( > A ? S[c++] = A >> | : ( === ( & A) && v + < r.length && === ( & r.charCodeAt(v + )) ? (A = + (( & A) << ) + ( & r.charCodeAt(++v)), S[c++] = A >> | , S[c++] = A >> & | ) : S[c++] = A >> | , S[c++] = A >> & | ), S[c++] = & A | )
}
(var p = m, F = + .fromCharCode() + .fromCharCode() + .fromCharCode() + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()), D = + .fromCharCode() + .fromCharCode() + .fromCharCode() + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()) + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()), b = ; b < S.length; b++) p += S[b], p = n(p, F);
return p = n(p, D), p ^= s, > p && (p = ( & p) + ), p %= , p.toString() + + (p ^ m)
}
sign = execjs.compile(js).(,q)
(以上代码获取了sign)
经过一系列的反反爬虫准备,我们就可以设置好的“源语言”和“目标语言”最后的这两个参数了。
From =
To =
(以上代码代表着英译中,若要进行其它语言的翻译,请输入语言对应的英文缩写,英文缩写对应表将会放到本文最后)
接着,我们就能构建参数json了。
data = {,
,
,
,
}最后,我们就能请求数据并打印了。
= requests.post(url,headers=headers,=).json()
(text)
我们发现打印出来的结果是个json字典,翻译结果就在其中,我们只需要翻译结果,所以我们可以索引翻译结果的位置再打印。
text = requests.post(url,headers=headers,data=data).json()[][][][]
print(text)
运行结果:

完整代码:
import requests
import execjs
url = :
headers = {你的cookie'}
js = var i =
function n(r, o) {
(var t = ; t < o.length - ; t += ) {
var a = o.charAt(t + );
a = a >= ? a.charCodeAt() - : Number(a), a = === o.charAt(t + ) ? r >>> a : r << a, r = === o.charAt(t) ? r + a & : r ^ a
}
r
}
function e(r) {
var o = r.(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
(null === o) {
var t = r.length;
t > && (r = + r.substr(, ) + r.substr(Math.floor(t / ) - , ) + r.substr(-, ))
} {
(var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = , h = e.length, f = []; h > C; C++) !== e[C] && f.push.apply(f, a(e[C].split())), C !== h - && f.push(o[C]);
var g = f.length;
g > && (r = f.slice(, ).join() + f.slice(Math.floor(g / ) - , Math.floor(g / ) + ).join() + f.slice(-).join())
}
var u = void , l = + .fromCharCode() + .fromCharCode() + .fromCharCode();
u = null !== i ? i : (i = window[l] || ) || ;
(var d = u.split(), m = Number(d[]) || , s = Number(d[]) || , S = [], c = , v = ; v < r.length; v++) {
var A = r.charCodeAt(v);
> A ? S[c++] = A : ( > A ? S[c++] = A >> | : ( === ( & A) && v + < r.length && === ( & r.charCodeAt(v + )) ? (A = + (( & A) << ) + ( & r.charCodeAt(++v)), S[c++] = A >> | , S[c++] = A >> & | ) : S[c++] = A >> | , S[c++] = A >> & | ), S[c++] = & A | )
}
(var p = m, F = + .fromCharCode() + .fromCharCode() + .fromCharCode() + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()), D = + .fromCharCode() + .fromCharCode() + .fromCharCode() + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()) + ( + .fromCharCode() + .fromCharCode() + .fromCharCode()), b = ; b < S.length; b++) p += S[b], p = n(p, F);
p = n(p, D), p ^= s, > p && (p = ( & p) + ), p %= , p.toString() + + (p ^ m)
}
= '源语言'
To = '目标语言'
token = '你的token'
q = input('翻译:')
sign = execjs.compile(js).call(,q)
data = {':,
':To,
':q,
':sign,
':token}
text = requests.post(url,headers=headers,data=data).json()[']['][][']
print(text)
语言英文缩写对应表
{
: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: ,: }喜欢的话点在看支持一下呗~