
Python爬虫实现突破百度文库限制

爬取目标
工具使用
开发环境:python3.7, Windows10
使用工具包:requests,re
重点学习内容
获取网址数据
正则提取数据
保存文本数据
项目思路解析
这篇文章主要介绍的如何处理复制限制的问题
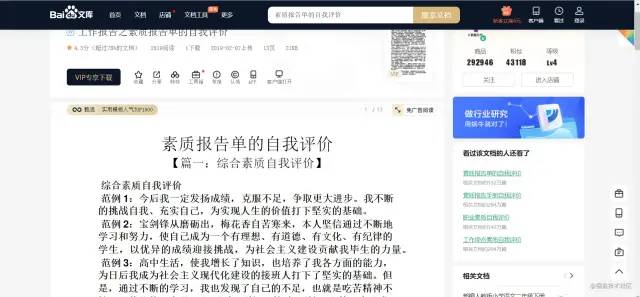
当前网页数据为加载得到的数据
需要通过抓包的方式提取对应数据
打卡抓包工具进行数据找寻
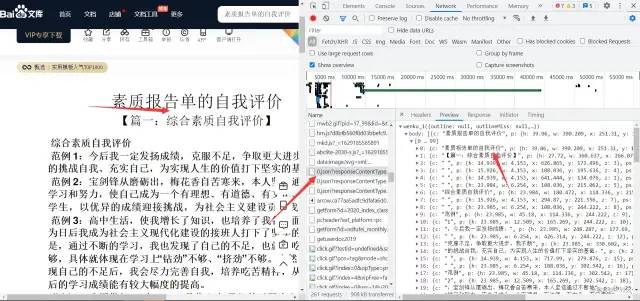
找到目标数据之后在找寻数据资源地址的加载方式
要知道数据是从哪里加载过来的
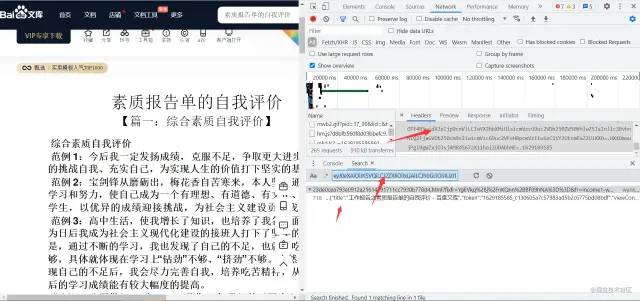
通过搜索到数据其实是前端页面自带的
加载之后的数据
需要从文章页面提取出所有的数据下载地址
通过正则的方式提取出所有的数据下载地址
def get_url(self):url = "https://wenku.baidu.com/view/d19a6bf4876fb84ae45c3b3567ec102de3bddf82.html"headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0','Connection': 'keep-alive','Host': 'wenku.baidu.com','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}response = self.session.get(url=url,headers=headers)json_data = re.findall('"json":(.*?}])', response.text)[0]json_data = json.loads(json_data)# print(json_data)for index, page_load_urls in enumerate(json_data):# print(page_load_urls)page_load_url = page_load_urls['pageLoadUrl']# print(index)self.get_data(index, page_load_url)
再次对文章片段数据发送请求
获取到对应json数据
通过正则的方式先将wenku_1里的json数据全部取出来
在取出body下面所以的列表
在取出所以的C键对应的值
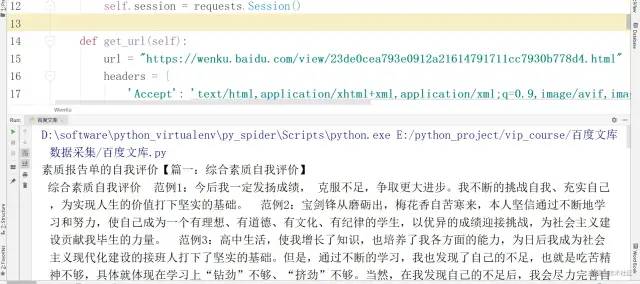
最后将数据进行保存
简易源码分享
import requestsimport reimport jsonclass WenKu():def __init__(self):self.session = requests.Session()def get_url(self):url = "https://wenku.baidu.com/view/23de0cea793e0912a21614791711cc7930b778d4.html"headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0','Connection': 'keep-alive','Host': 'wenku.baidu.com','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-origin','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}response = self.session.get(url=url,headers=headers)json_data = re.findall('"json":(.*?}])', response.text)[0]json_data = json.loads(json_data)# print(json_data)for index, page_load_urls in enumerate(json_data):# print(page_load_urls)page_load_url = page_load_urls['pageLoadUrl']# print(index)self.get_data(index, page_load_url)def get_data(self, index, url):headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0','Connection': 'keep-alive','Host': 'wkbjcloudbos.bdimg.com','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'none','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}response = self.session.get(url=url,headers=headers)# print(response.content.decode('unicode_escape'))data = response.content.decode('unicode_escape')comand = 'wenku_' + str(index+1)json_data = re.findall(comand + "\((.*?}})\)", data)[0]# print(json_data)json_data = json.loads(json_data)result = []for i in json_data['body']:data = i["c"]# print(data)result.append(data)print(''.join(result).replace(' ', '\n'))with open('疫情防控.txt', 'a', encoding='utf-8')as f:f.write(''.join(result).replace(" ", '\n'))if __name__ == '__main__':wk = WenKu()wk.get_url()
搜索下方加老师微信
老师微信号:XTUOL1988【切记备注:学习Python】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
评论