
搜索引擎技术之网络爬虫
日期 : 2021年09月13日
正文共 :3217字
阅读目录
1. 网络爬虫技术基本工作流程和基础架构 2. 网络爬虫的抓取策略 3. 网络爬虫更新策略 4. 分布式抓取系统结构 5. 参考内容

1. 网络爬虫技术基本工作流程和基础架构
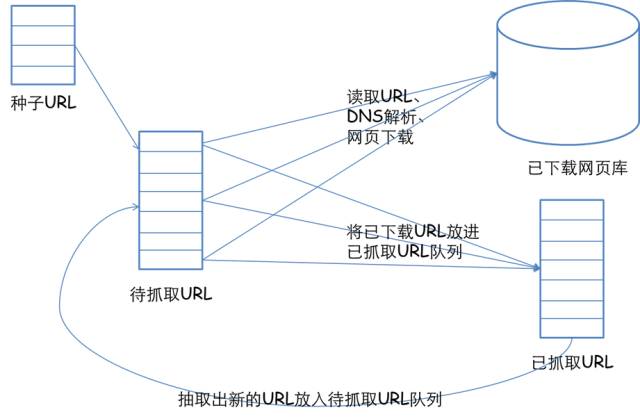
2. 网络爬虫的抓取策略
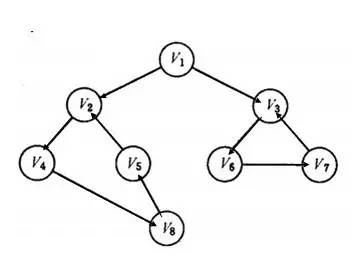
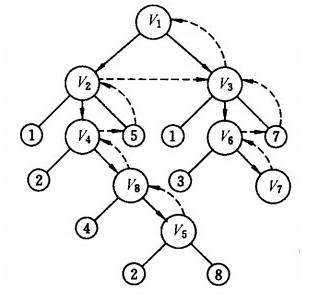

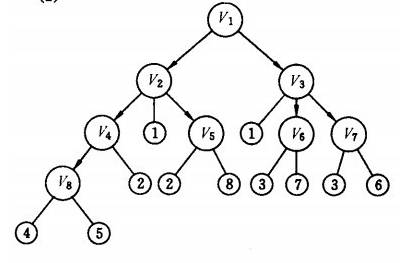
3. 网络爬虫更新策略
尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,抓取系统可以优先更新那些现实在查询结果前几页中的网页,而后再更新那些后面的网页。这种更新策略也是需要用到历史信息的。用户体验策略保留网页的多个历史版本,并且根据过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的依据。
3)聚类抽样策略
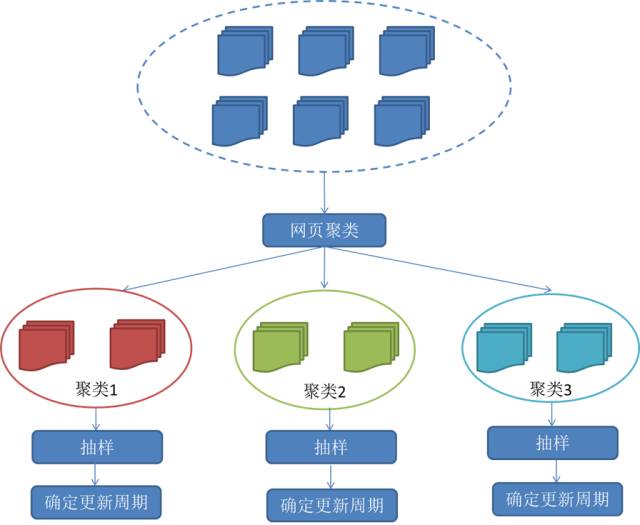
4. 分布式抓取系统结构
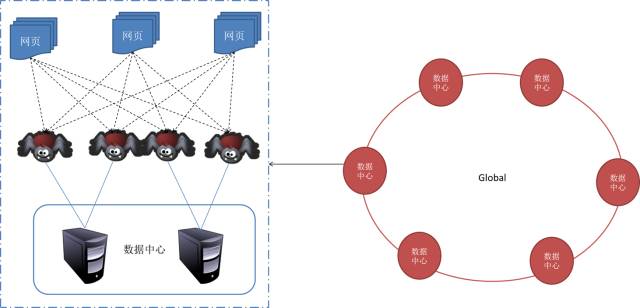
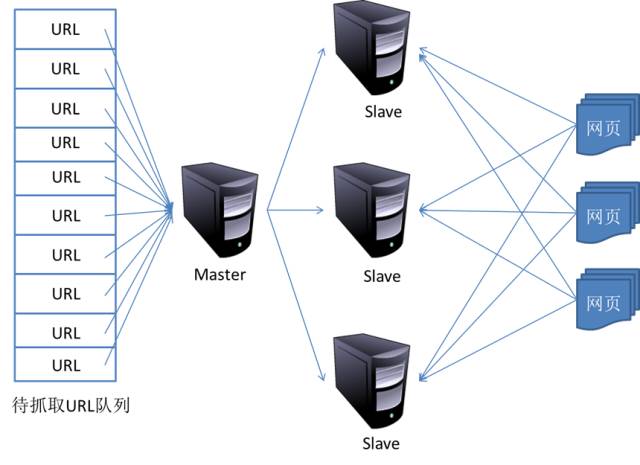
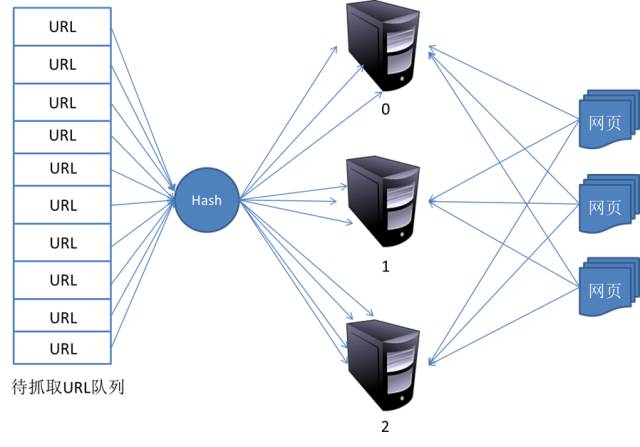
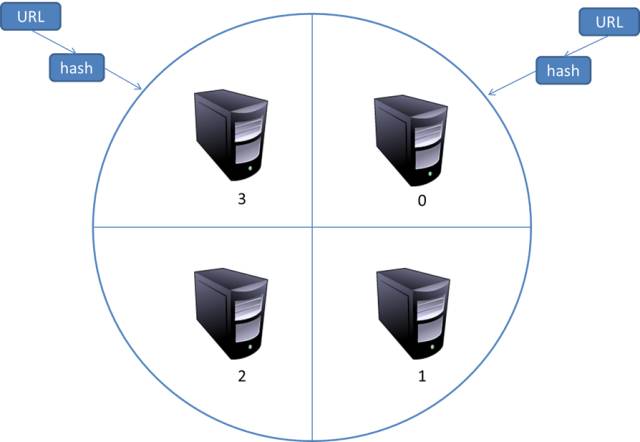
5. 参考内容
— THE END —

评论