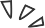在CVPR 2021中,旷视研究院共入选论文22篇,其中Oral论文2篇,研究领域涵盖激活函数、神经网络、神经网络架构搜索、光流估计、无监督学习、人体姿态估计、目标检测等。本篇推文中,我们为大家带来了11篇入选论文的精彩摘要,两篇oral论文也在其中,分享给大家。oral论文
Fully Convolutional Networks for Panoptic Segmentation
本文旨在使用全卷积形式统一地表达和预测物体和周边环境,从而实现准确高效的全景分割。具体来说,本文提出卷积核生成器将每个物体和每类环境的语义信息编码至不同的卷结核中,并同高分辨率的特征图卷积直接输出每个前景和背景的分割结果。通过这种方法,物体和环境的个体差异和语义一致性可以被分别保留下来。该方法在多个全景分割数据集上均取得速度和精度的当前最佳结果。arxiv: https://arxiv.org/abs/2012.00720github: https://github.com/yanwei-li/PanopticFCNoral论文
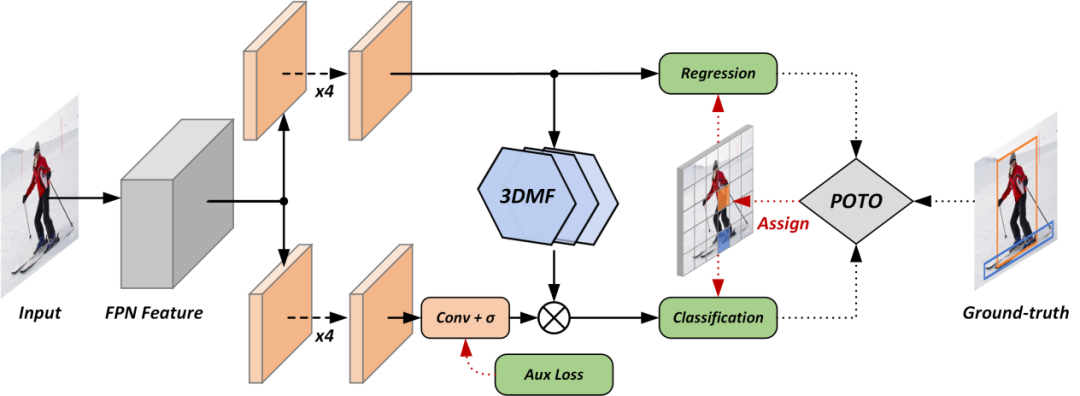
FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation
FFB6D提出一种网络全流双向融合的RGBD表征学习框架并应用于6D位姿估计问题。我们发现现有的表征学习方法都没能很好地利用RGB中的外观信息和深度图(点云)中的几何信息这两种互补的数据源。对此,我们设计了一种双向稠密融合模块并应用到CNN和点云网络的每个编码和解码层。这种全流双向融合机制能让两个网络充分利用彼此提取的局部和全局互补信息,从而获得更好的表征用于下游预测任务。此外,在输出表征选择上,我们结合物品的纹理和几何信息设计了一种SIFT-FPS关键点选择算法,简化了网络定位关键点的难度并提升了位姿精度。我们的方法在多个基准上都获得显著的提升。并且这种RGBD表征学习骨干网络能通过级联不同的预测网络,应用在更多以RGBD为输入的视觉任务上。👉关键词:RGBD表征学习,3D视觉,6D位姿估计PDF: https://arxiv.org/abs/2103.02242code: https://github.com/ethnhe/FFB6DRepVGG: Making VGG-style ConvNets Great Again
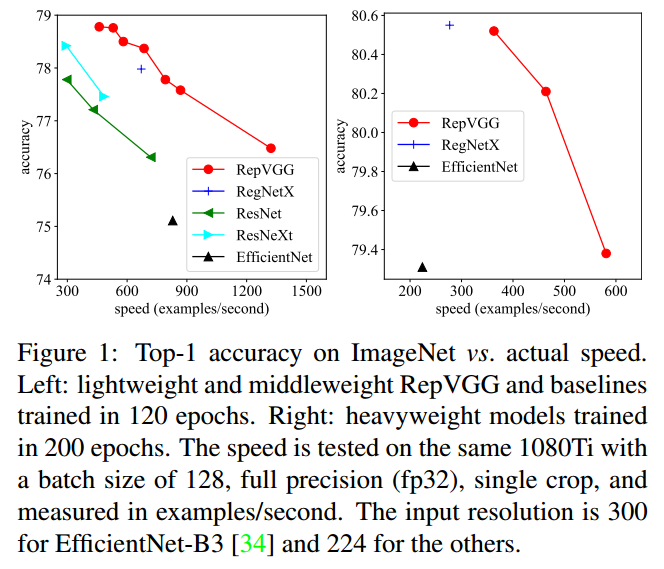
科学技术总是螺旋式地上升。我们“复兴”了VGG式单路极简卷积神经网络架构,一路3x3卷到底,在速度和性能上达到SOTA水平,在ImageNet上超过80%正确率。为了克服VGG式架构训练困难的问题,我们使用结构重参数化(structural re-parameterization)在训练时的模型中构造恒等映射和1x1卷积分支,然后在训练结束后将其等效融合进3x3卷积中去,因而推理时模型仅包含3x3卷积。这一架构没有任何分支结构,因此其并行度很高,速度很快。且由于主体部分仅有“3x3-ReLU”这一种算子,特别适合用于定制硬件。https://arxiv.org/abs/2101.03697
Dynamic Region-Aware Convolution
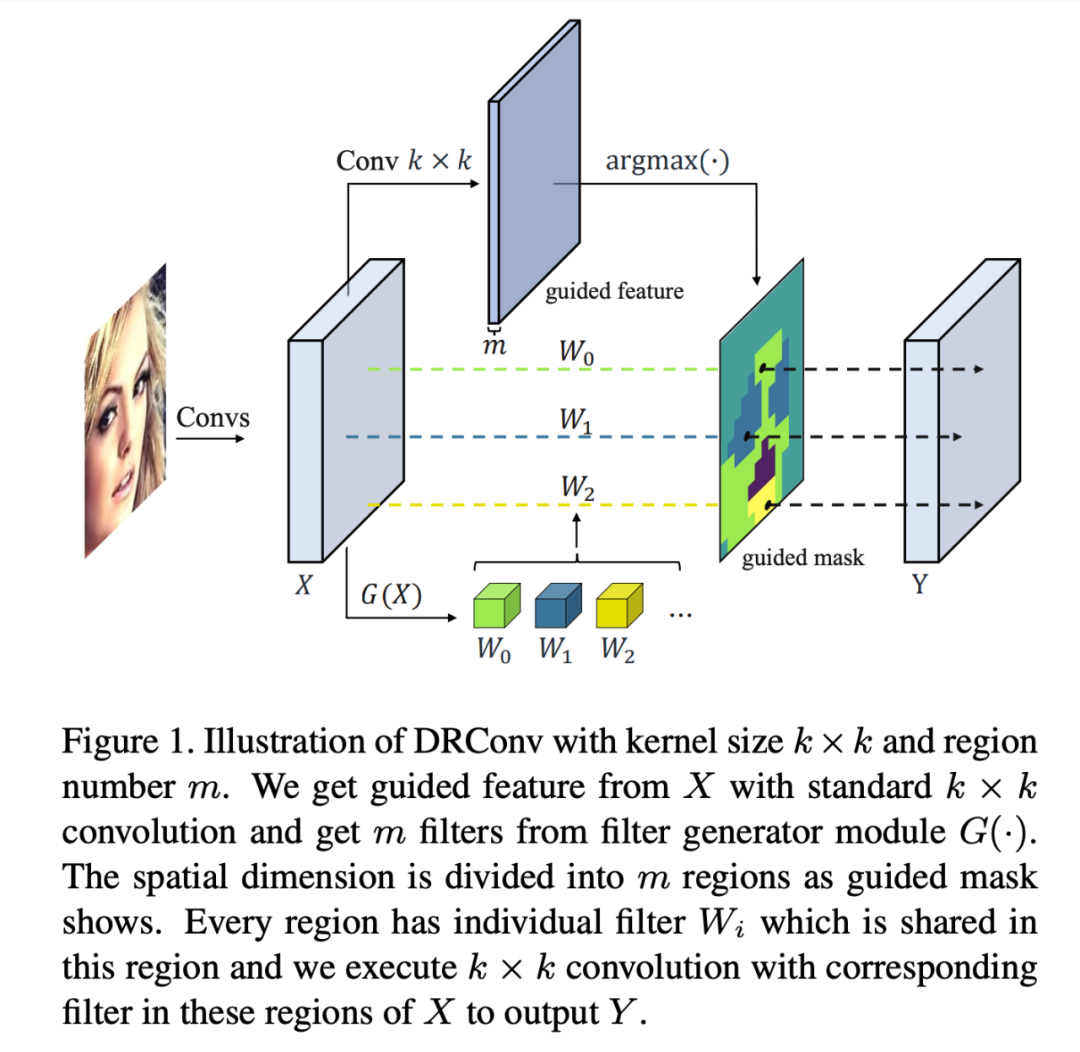
本文提出一种新的卷积操作----动态区域注意卷积(DRConv: Dynamic Region-Aware Convolution),该卷积可以根据特征相似度为不同平面区域分配定制的卷积核。这种卷积方式相较于传统卷积极大地增强了对图像语义信息多样性的建模能力。标准卷积层可以增加卷积核的数量以提取更多的视觉元素,但会导致较高的计算成本。DRConv使用可学习的分配器将逐渐增加的卷积核转移到平面维度,这不仅提高了卷积的表示能力,而且还保持了计算成本和平移不变性。DRConv是一种用于处理语义信息分布复杂多变的有效而优雅的方法,它可以以其即插即用特性替代任何现有网络中的标准卷积,且对于轻量级网络的性能有显著提升。本文在各种模型(MobileNet系列,ShuffleNetV2等)和任务(分类,面部识别,检测和分割)上对DRConv进行了评估,在ImageNet分类中,基于DRConv的ShuffleNetV2-0.5×在46M计算量的水平下可实现67.1%的性能,相对基准提升6.3%。https://arxiv.org/abs/2003.12243Diverse Branch Block: Building a Convolution as an Inception-like Unit
我们提出一种卷积网络基本模块(DBB),用以丰富模型训练时的微观结构而不改变其宏观架构,以此提升其性能。这种模块可以在训练后通过结构重参数化(structural re-parameterization)等效转换为一个卷积,因而不引入任何额外的推理开销。
我们归纳了六种可以此种等效转换的结构,包括1x1-KxK连续卷积、average pooling等,并用这六种变换给出了一种代表性的形似Inception的DBB实例,在多种架构上均取得了显著的性能提升。我们通过实验确认了“训练时非线性”(而推理时是线性的,如BN)和“多样的链接”(比如1x1+3x3效果好于3x3+3x3)是DBB有效的关键。
👉关键词:结构重参数化,无推理开销,无痛提升
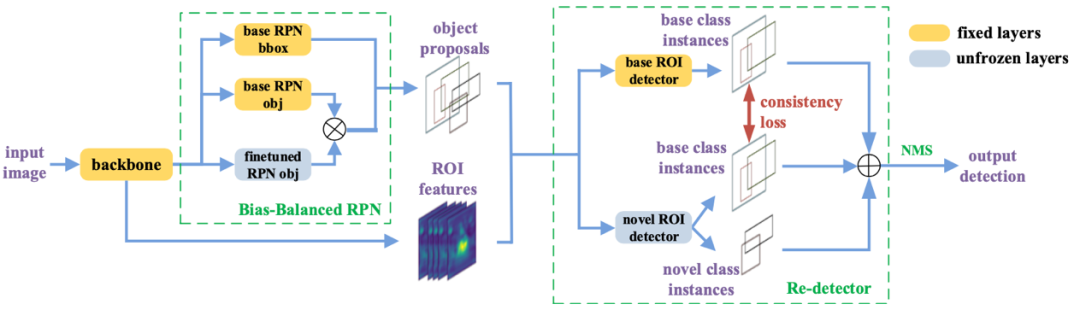
Generalized Few-Shot Object Detection without Forgetting过去的工作大都聚焦在小类样本类别性能而牺牲了大类样本的性能。本文提出一种无遗忘效应的小类样本目标检测器,能够在实现更好的小类样本类别性能的同时,不掉落大类样本类别的性能。在本文中,我们发现了预训练的检测器很少在未见过的类别上产生假阳性预测,且还发现RPN并非理想的类别无关组件。基于这两点发现,我们设计了Re-detector和Bias-Balanced RPN两个简单而有效的结构,只增加少量参数和推断时间即可实现无遗忘效应的小类样本目标检测。Distribution Alignment: A Unified Framework for Long-tail Visual Recognition
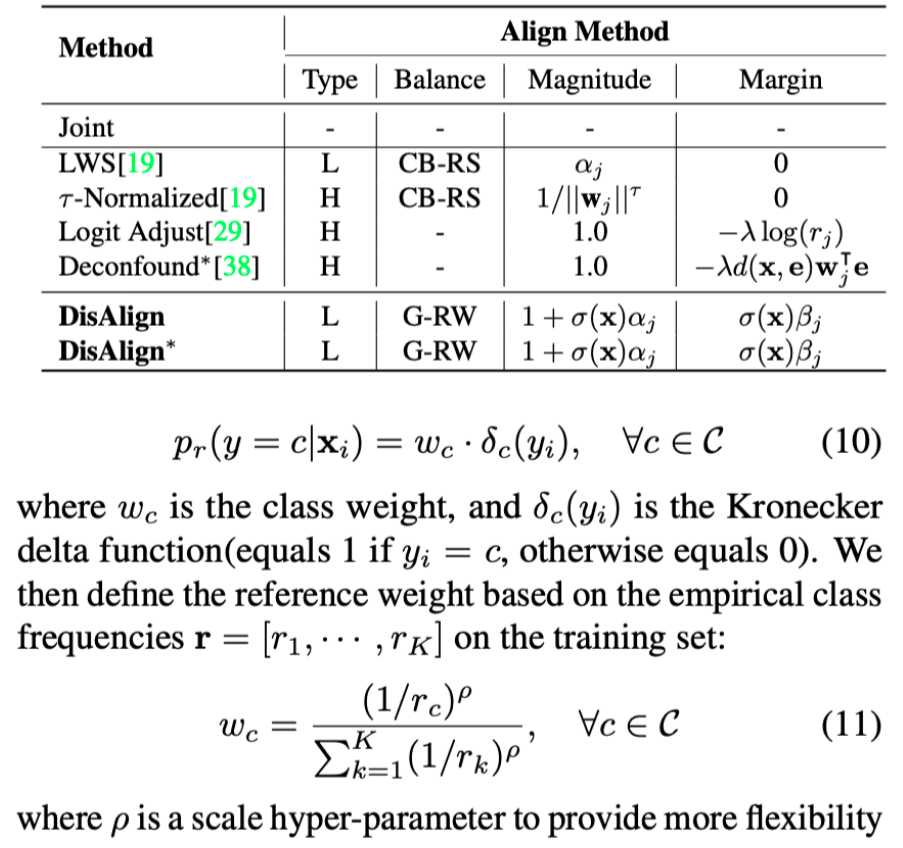
本文提出了一个处理含有长尾数据分布的视觉识别任务的统一框架。我们首先针对现有的处理长尾问题的两阶段的方法进行了实验分析,找出现有方法主要的性能瓶颈。基于实验分析,我们提出了一种分布对齐策略来系统性解决长尾视觉任务。该框架基于两阶段方法设计,在第一阶段,使用instance-balanced 采样策略进行特征表示学习(representation learning)。在第二阶段,我们首先设计了一个input-aware的对齐函数,以实现对输入数据的得分进行矫正。同时,为了引入数据集分布的先验,我们设计了一个泛化重加权(Generalized Re-weight)方案, 来处理图像分类,语义分割,物体检测和实例分割等多种视觉任务场景。我们在四个任务上验证了我们的方法,在各个任务上均取得了明显的性能提升。End-to-End Object Detection with Fully Convolutional Network
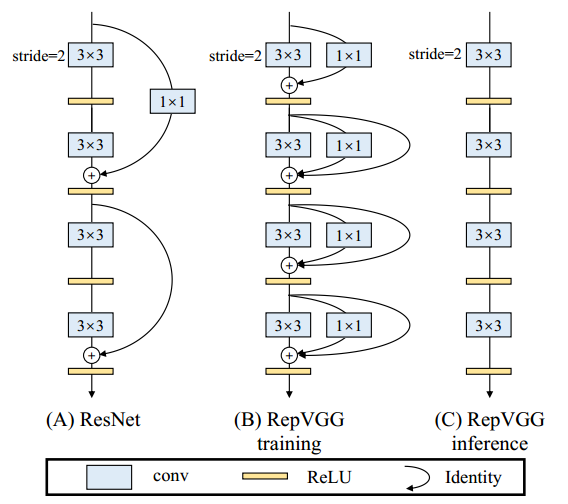
本文首次在全卷积目标检测器上去除了NMS(非极大值抑制)后处理,做到了端到端训练。我们分析了主流一阶段目标检测方法,并发现传统的一对多标签分配策略是这些方法依赖NMS的关键,并由此提出了预测感知的一对一标签分配策略。此外,为了提升一对一标签分配的性能,我们提出了增强特征表征能力的模块,和加速模型收敛的辅助损失函数。我们的方法在无NMS的情况下达到了与主流一阶段目标检测方法相当的性能。在密集场景上,我们的方法的召回率超过了依赖NMS的目标检测方法的理论上限。
👉关键词:端到端检测,标签分配,全卷积网络
https://arxiv.org/abs/2012.03544
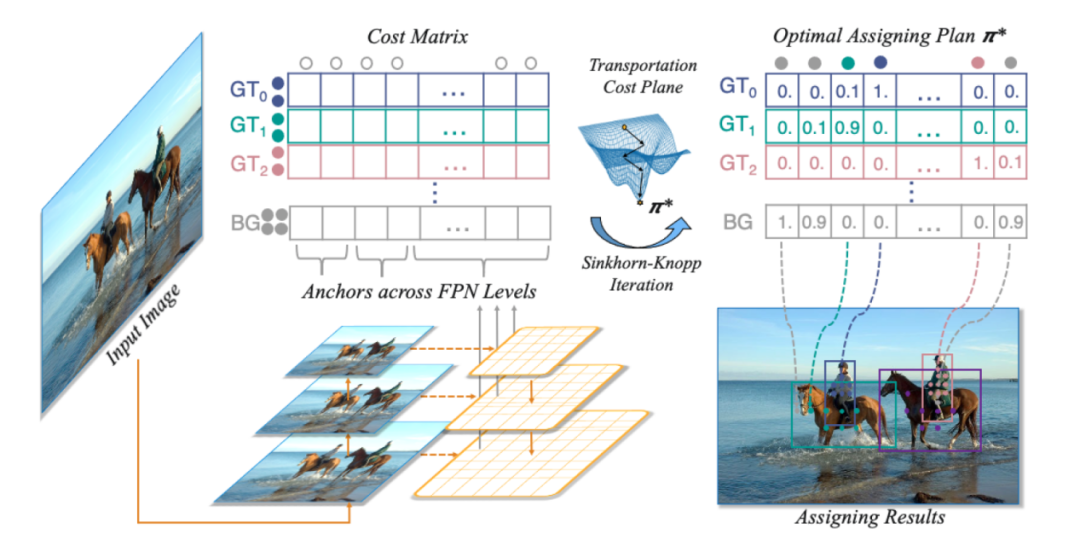
OTA: Optimal Transport Assignment for Object Detection
我们提出了一种基于最优传输理论的目标检测样本匹配策略,利用全局信息来寻找最优样本匹配的结果,相对于现有的样本匹配技术,具有如下优势:1). 检测精度高。全局最优的匹配结果能帮助检测器以稳定高效的方式训练,最终在COCO数据集上达到最优检测性能。2). 适用场景广。现有的目标检测算法在遇到诸如目标密集或被严重遮挡等复杂场景时,需要重新设计策略或者调整参数,而最优传输模型在全局建模的过程中包括了寻找最优解的过程,不用做任何额外的调整,在各种目标密集、遮挡严重的场景下也能达到最先进的性能,具有很大的应用潜力。
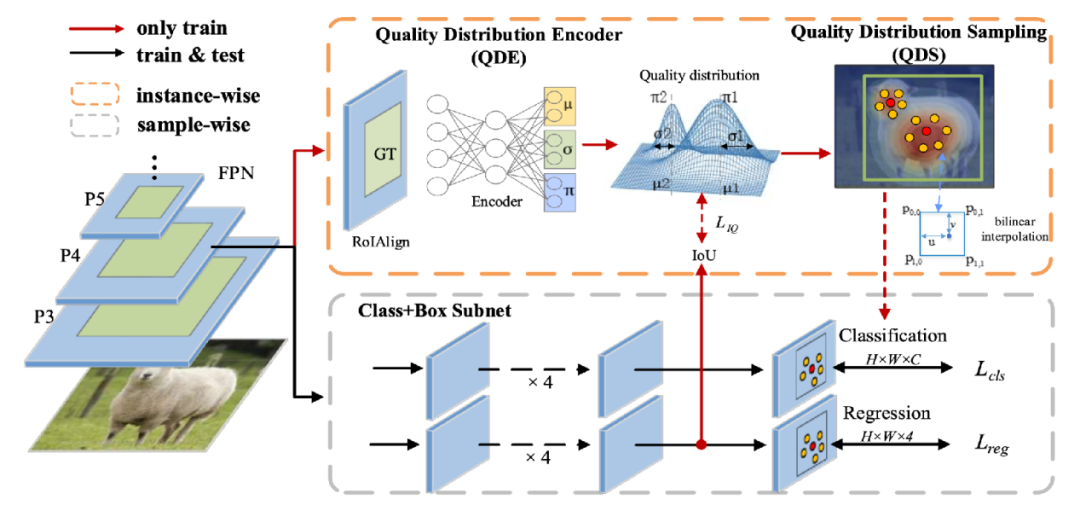
IQDet: Instance-wise Quality Distribution Sampling for Object Detection
由于一阶段检测器的标签分配有静态、没有考虑目标框的全局信息等不足,我们提出了一种基于目标质量分布采样的目标检测器。在本文中,我们提出质量分布编码模块QDE和质量分布采样模块QDS,通过提取目标框的区域特征,并基于高斯混合模型来对预测框的质量分布进行建模,来动态的选择检测框的正负样本分配。本方法只涉及训练阶段标签分配,就可以在COCO等多个数据集上实现当前最佳结果。
👉关键词:标签分配
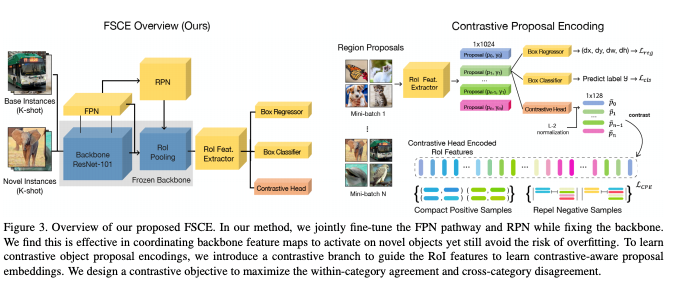
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
论文提出的FSCE方法旨在从优化特征表示的角度去解决小样本物体检测问题。小样本物体检测任务中受限于目标样本的数目稀少,对目标样本的分类正确与否往往对最终的性能有很大的影响。FSCE借助对比学习的思想对相关候选框进行编码优化其特征表示,加强特征的类内紧凑和类间相斥,最后方法在常见的COCO和Pascal VOC数据集上都得到有效提升。
👉关键词:小样本目标检测,对比学习论文链接:https://arxiv.org/abs/2103.05950


 End
End