
ETL 可行性方案 Kettle
一、Kettle
1.1 简介
Kettle是一款基于Java语言开发的可视化编程开源ETL工具,支持单机、集群方式部署。
数据处理简化为Job(流程控制、调度)和Transform(数据转换流)。
1.2 ETL
ETL工具特性:
连接、平台独立、数据规模(并发、分区、集群)、复用性、扩展性、数据转换、测试和调试、日志审计
二、优点
基于Java开发、开源、跨平台,社区支持
支持分布式集群方式部署,主从架构
插件架构扩展性好, 支持的扩展插件: 作业、转换、分区、数据库
全面的数据访问支持(支持多个数据库, 如果非默认支持,还可以通过插件扩展)
方便易用的GUI操作界面
支持java/script/sql自定义转换逻辑,支持自定义失败处理步骤
可视化编程,容易上手?(组件繁杂、熟练使用需要一定时间)
三、缺点
集群模式采用主从结构,不具备自动切换主从的功能。所以一旦主节点宕机,整个系统不可用
对网络要求高,节点之间需要不断的传输数据
免费版的Kettle缺乏必要的数据异常处理(简单抛出)和监控运维等管理功能服务。实际测试中经常出现一些莫名异常,调试比较困难。
bulk load数据无法查找出错误明细。
内存占用。并发模型中各组件以管道(hop)相连,后续某个组件处理速度较慢时,容易成为性能瓶颈.
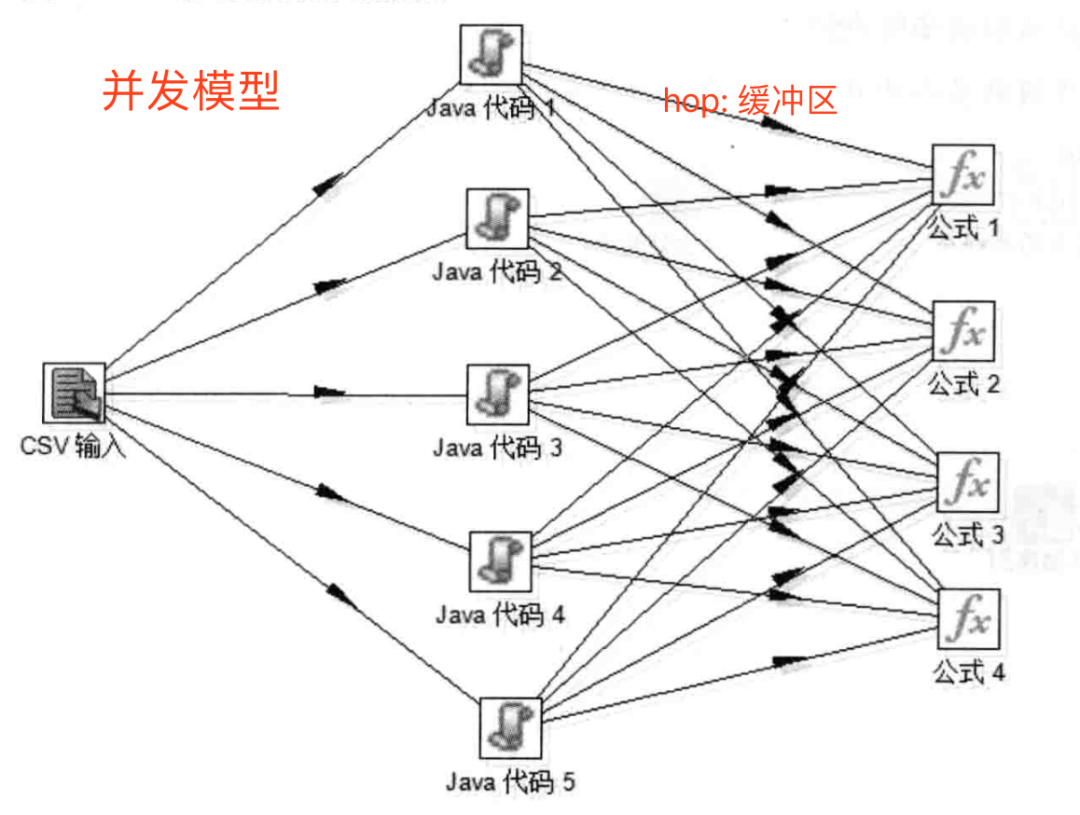
支持简单的数据分析工作,如sort/group by/aggregator,不适用数据量较大的场景。
对于数据分析工作来说,需注意Kettle目前不具备时间窗口、中间状态存储、延迟消息策略等实时计算引擎特性
对于简单的ETL任务Kettle略显笨重,8.2版本安装包1.1G大小.手动编译的9.2版本1.7G
Kettle资源库用于保存自定义的转换任务等元数据信息,支持本地、数据库方式。测试中使用数据库方式时操作卡顿频繁。
对最近几年新出现存储引擎的支持不足(相对datax来说). 如: elasticsearch/druid/kudu...
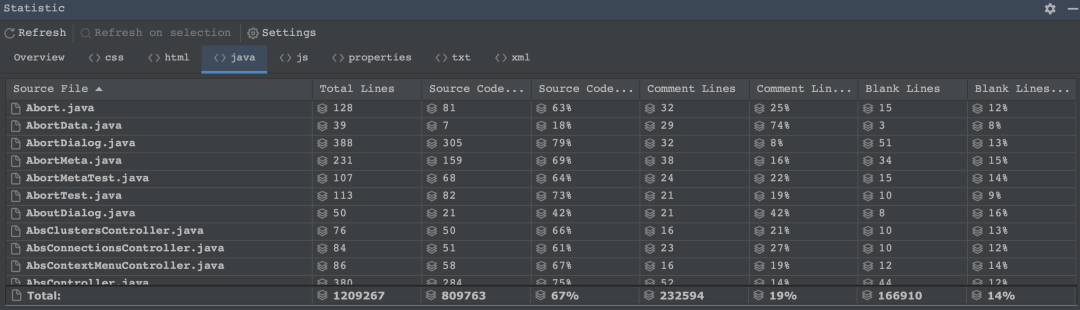
源码统计
四、测试
4.1 测试环境
kettle版本: 8.2.0.0
测试环境:
master 10.128.2.64
slave1 10.128.2.86
slave2 10.128.2.54
JVM: -Xms1024m -Xmx2048m
kettle集群监控web页面: http://10.128.2.64:8090/kettle/status/
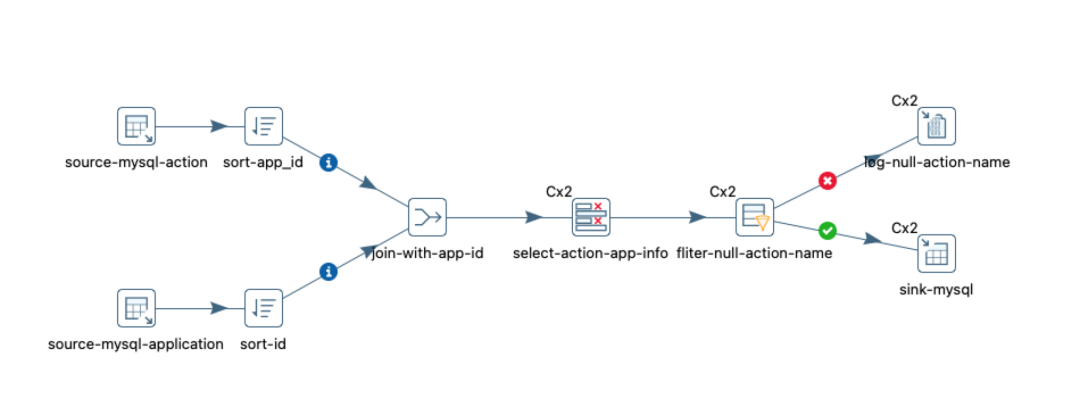
4.2 Mysql连接查询
场景: 集群模式,表现良好.
2.139/2.54 mysql数据库: SVR_N_ACTION/SVR_U_APPLICATION关联查询
查询2.54 SVR_U_ACTION表(500w记录)
查询1.139 SVR_U_APPLICATION(1224记录)
action.app_id=application.id关联
字段选择: action_id, action_name, application_name
过滤action_name字段输出到log日志
查询结果同步到2.54 SVR_U_ACTION
拓扑图:
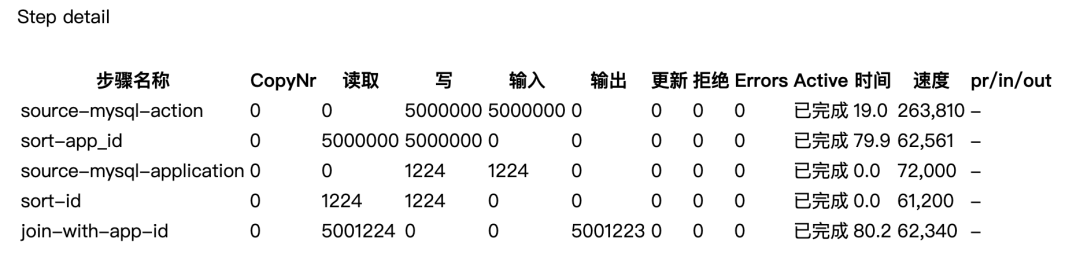
集群运行监控:
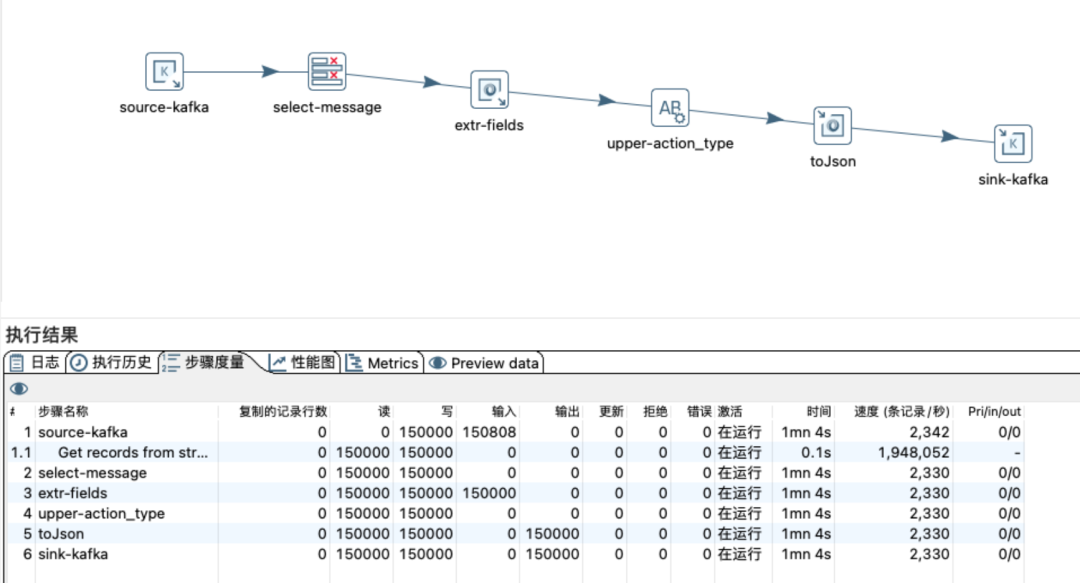
4.3 kafka
场景: 本地, kafka消费、生产
数据结构:
{
"trace_id":"05543abec3cd444a861ad32f232d872b",
"action_type":"bg",
"application_id":366,
"url":"4p6g3cab0h6mbqfyt6ggaaozqw70mo",
"biz_system_id":529,
"action_id":970677,
"action_name":"angxk9ahcr",
"id":"82e9b1e4a34a427097e2a5ed4a15ab27",
"perf":102388,
"timestamp":"2021-02-12 16:42:38"
}
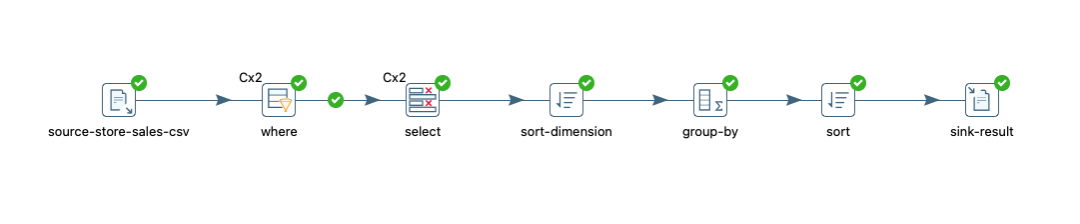
4.4 group_by-1000w
场景: 集群模式, 1000w记录
SQL:
select
ss_sold_date_sk,
ss_wholesale_cost,
avg(ss_item_sk) as ss_item_sk_avg,
COUNT(DISTINCT ss_sales_price) as ss_sales_price_cnt,
count(*) as cnt
from store_sales_all
where ss_sold_date_sk
between 2451813 and 2451900 and ss_sold_time_sk between 65400 and 66000
group by ss_sold_date_sk,ss_wholesale_cost
order by ss_item_sk_avg desc,ss_sold_date_sk拓扑:
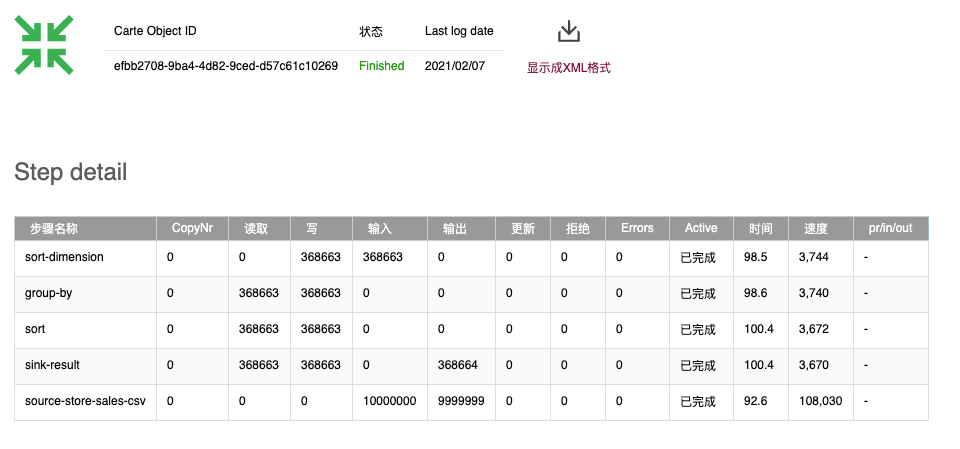
运行监控:
4.5 group-by-5000w
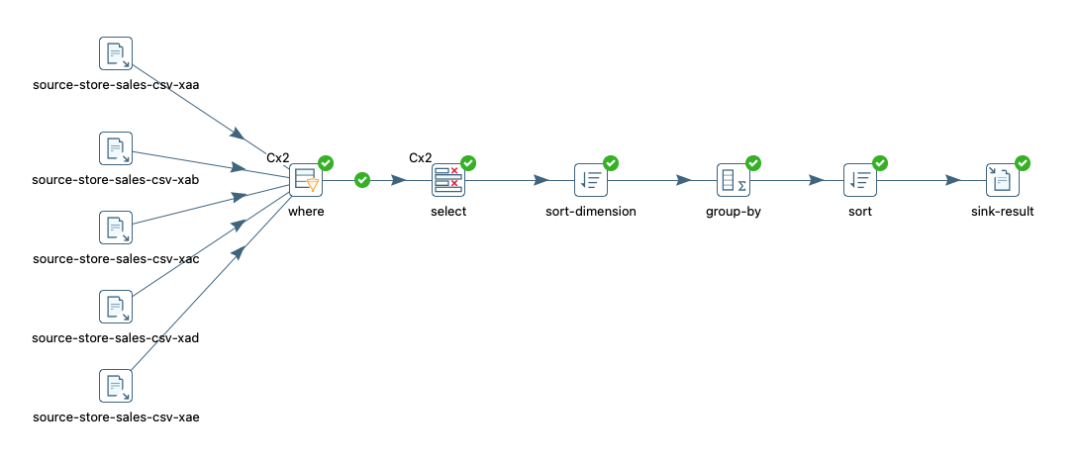
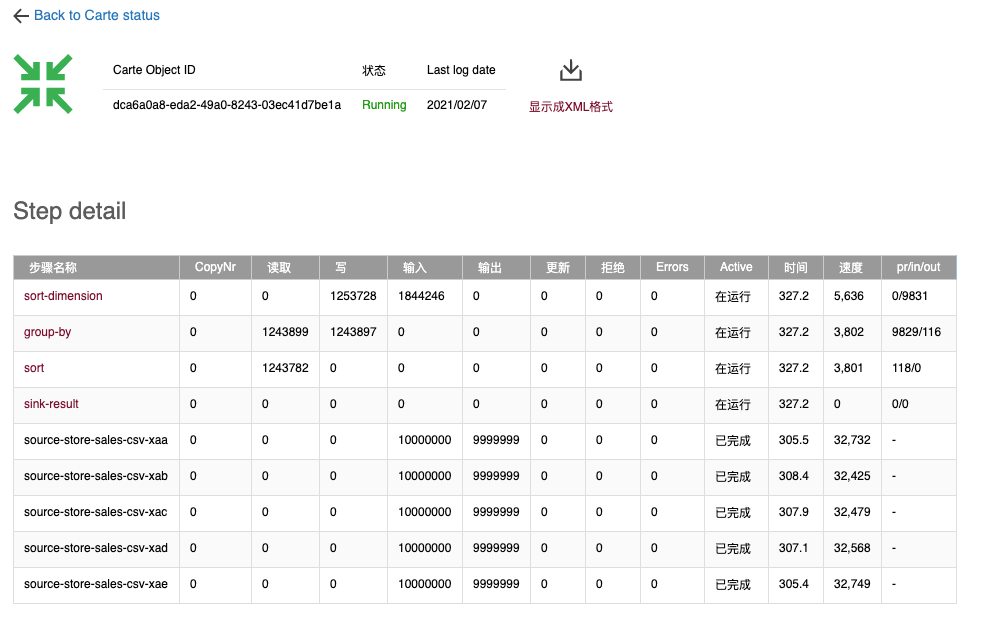
4.6 group-by-all-5000w
去除where过滤条件,全量group by
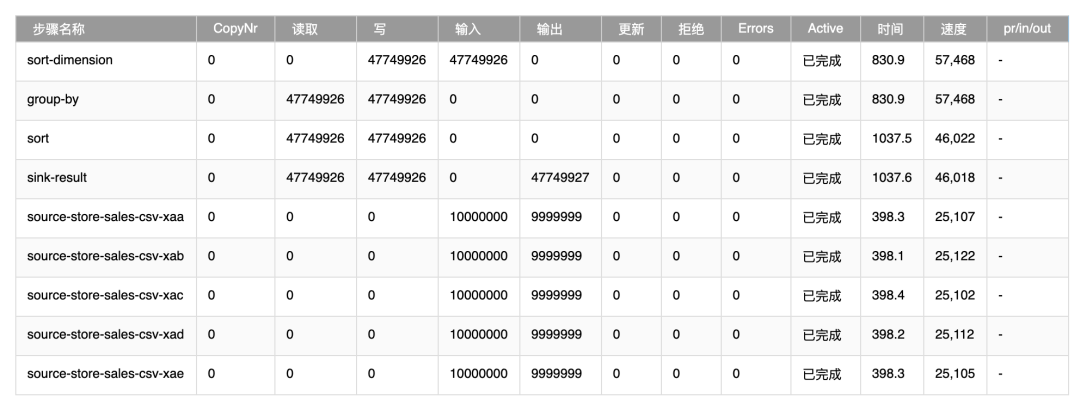
4.7 group-by-all-2.8亿
五、总结
Kettle历经近二十年发展,架构设计(插件体系)、交互设计比较完善,若从头设计有较好的参考性。
作为ETL工具来说功能比较丰富, 甚至略显繁杂,有一定的学习成本。
支持分布式集群,目前开源的datax不支持.
使用感受,作为研发人员来说不太习惯. 比如一些简单的逻辑处理,通过图形界面操作比较麻烦,甚至说有点折磨!
数据同步、失败处理、任务调度、管理和监控、拓扑设计与调试
对于实时etl场景来说,无论kettle还是datax支持都不够, 实际场景中很可能需要类似flume这种第三方工具支持.
基本满足BPI业务需求
六、个人意见
综合投入成本,项目周期等因素,建议前期以Kettle作为ETL基础.可能的话BPI先行.
架构实现上, web端ETL拓扑数据模型单独设计,与底层ETL引擎进行隔离.
参考:
《Pentaho Kettle解决方案:使用PDI构建开源ETL解决方案》
Kettle插件结构: https://zhuanlan.zhihu.com/p/24982421
Kettle体系结构: https://blog.csdn.net/romaticjun2011/article/details/40680483
source: https://www.yuque.com/gejuntingyun/kb/pgwv5q

喜欢,在看