
Kafka Connect | 无缝结合Kafka构建高效ETL方案

很多同学可能没有接触过 Kafka Connect,大家要注意不是Connector。
Kafka Connect 是一款可扩展并且可靠地在 Apache Kafka 和其他系统之间进行数据传输的工具。
背景
Kafka connect是Confluent公司(当时开发出Apache Kafka的核心团队成员出来创立的新公司)开发的confluent platform的核心功能。可以很简单的快速定义 connectors 将大量数据从 Kafka 移入和移出. Kafka Connect 可以摄取数据库数据或者收集应用程序的 metrics 存储到 Kafka topics,使得数据可以用于低延迟的流处理。一个导出的 job 可以将来自 Kafka topic 的数据传输到二级存储,用于系统查询或者批量进行离线分析。
大家都知道现在数据的ETL过程经常会选择kafka作为消息中间件应用在离线和实时的使用场景中,而kafka的数据上游和下游一直没有一个。无缝衔接的pipeline来实现统一,比如会选择flume 或者 logstash 采集数据到kafka,然后kafka又通过其他方式pull或者push数据到目标存储。而kafka connect旨在围绕kafka构建一个可伸缩的,可靠的数据流通道,通过 Kafka connect可以快速实现大量数据进出kafka从而和其他源数据源或者目标数据源进行交互构造一个低延迟的数据pipeline.给个图更直观点,大家感受下。
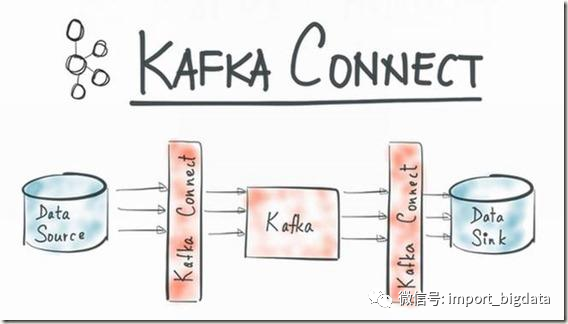
Kafka Connect 功能包括:
Kafka connectors 通用框架:- Kafka Connect 将其他数据系统和Kafka集成标准化,简化了 connector 的开发,部署和管理
分布式和单机模式 - 可以扩展成一个集中式的管理服务,也可以单机方便的开发,测试和生产环境小型的部署。
REST 接口 - 通过易于使用的REST API提交和管理connectors到您的Kafka Connect集群
offset 自动管理 - 只需要connectors 的一些信息,Kafka Connect 可以自动管理offset 提交的过程,因此开发人员无需担心开发中offset提交出错的这部分。
分布式的并且可扩展 - Kafka Connect 构建在现有的 group 管理协议上。Kafka Connect 集群可以扩展添加更多的workers。
整合流处理/批处理 - 利用 Kafka 已有的功能,Kafka Connect 是一个桥接stream 和批处理系统理想的方式。
Kafka Connect的适用场景
连接器和普通的生产者消费者模式有什么区别呢?似乎两种方式都可以达到目的。可能第一次接触connect的人都会由此疑问。在《kafka权威指南》这本书里,作者给出了建议:
如果你是开发人员,你会使用 Kafka 客户端将应用程序连接到Kafka ,井修改应用程序的代码,将数据推送到 Kafka 或者从 Kafka 读取数据。如果要将 Kafka 连接到数据存储系统,可以使用 Connect,因为这些系统不是你开发的,构建数据管道 I 10s你无能或者也不想修改它们的代码。Connect 可以用于从外部数据存储系统读取数据, 或者将数据推送到外部存储系统。如果数据存储系统提供了相应的连接器,那么非开发人员就可以通过配置连接器的方式来使用 Connect。
如果你要连接的数据存储系统没有相应的连接器,那么可以考虑使用客户端 API 或 Connect API 开发一个应用程序。我们建议首选 Connect,因为它提供了一些开箱即用的特性,比如配置管理、偏移量存储、井行处理、错误处理,而且支持多种数据类型和标准的 REST 管理 API。开发一个连接 Kafka 和外部数据存储系统的小应用程序看起来很简单,但其实还有很多细节需要处理,比如数据类型和配置选项,这些无疑加大了开发的复杂性一Connect 处理了大部分细节,让你可以专注于数据的传输。
Kafka Connect架构和组件
Kafka connect的几个重要的概念包括:connectors、tasks、workers、converters和transformers。
Connectors-通过管理任务来细条数据流的高级抽象
Tasks- 数据写入kafka和数据从kafka读出的实现
Workers-运行connectors和tasks的进程
Converters- kafka connect和其他存储系统直接发送或者接受数据之间转换数据
1) Connectors:在kafka connect中,connector决定了数据应该从哪里复制过来以及数据应该写入到哪里去,一个connector实例是一个需要负责在kafka和其他系统之间复制数据的逻辑作业,connector plugin是jar文件,实现了kafka定义的一些接口来完成特定的任务。

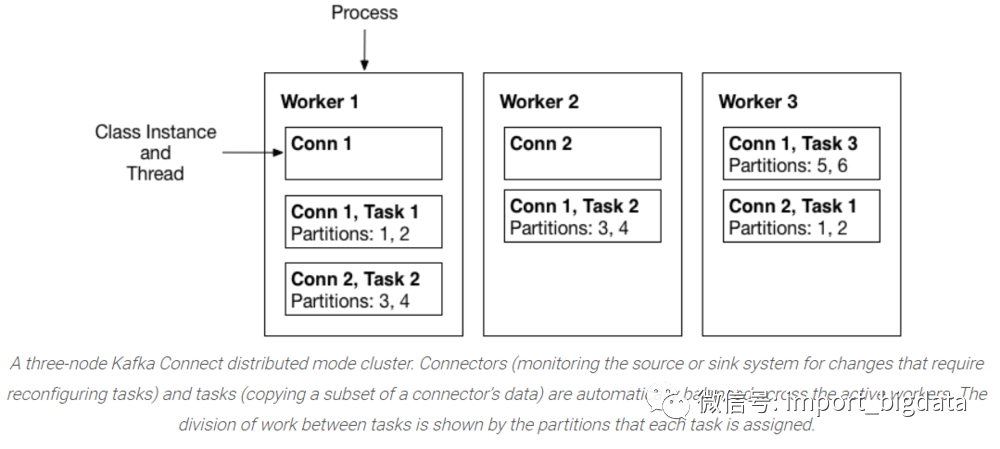
2) Tasks:task是kafka connect数据模型的主角,每一个connector都会协调一系列的task去执行任务,connector可以把一项工作分割成许多的task,然后再把task分发到各个worker中去执行(分布式模式下),task不自己保存自己的状态信息,而是交给特定的kafka 主题去保存(config.storage.topic 和status.storage.topic)。在分布式模式下有一个概念叫做任务再平衡(Task Rebalancing),当一个connector第一次提交到集群时,所有的worker都会做一个task rebalancing从而保证每一个worker都运行了差不多数量的工作,而不是所有的工作压力都集中在某个worker进程中,而当某个进程挂了之后也会执行task rebalance。
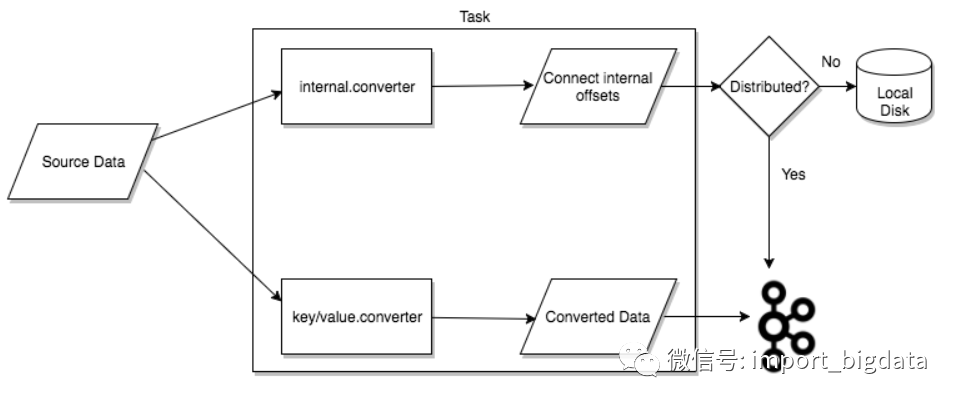
3) Workers:connectors和tasks都是逻辑工作单位,必须安排在进程中执行,而在kafka connect中,这些进程就是workers,分别有两种worker:standalone和distributed。这里不对standalone进行介绍,具体的可以查看官方文档。我个人觉得distributed worker很棒,因为它提供了可扩展性以及自动容错的功能,你可以使用一个group.ip来启动很多worker进程,在有效的worker进程中它们会自动的去协调执行connector和task,如果你新加了一个worker或者挂了一个worker,其他的worker会检测到然后在重新分配connector和task。
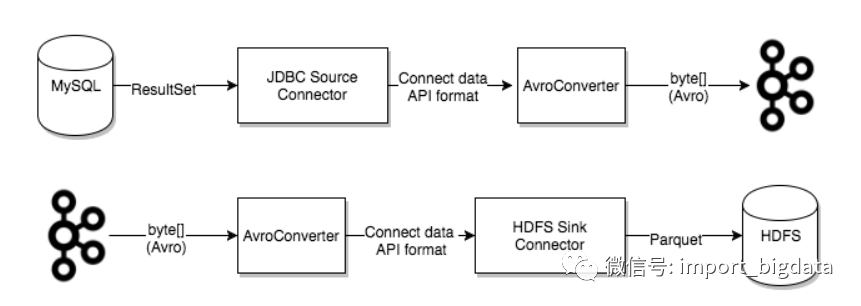
4) Converters:converter会把bytes数据转换成kafka connect内部的格式,也可以把kafka connect内部存储格式的数据转变成bytes,converter对connector来说是解耦的,所以其他的connector都可以重用,例如,使用了avro converter,那么jdbc connector可以写avro格式的数据到kafka,当然,hdfs connector也可以从kafka中读出avro格式的数据。
5) Connector可以配置转换,以便对单个消息进行简单且轻量的修改。这对于小数据的调整和事件路由十分方便,且可以在connector配置中将多个转换链接在一起。然而,应用于多个消息的更复杂的转换最好使用KSQL和Kafka Stream实现。转换是一个简单的函数,输入一条记录,并输出一条修改过的记录。Kafka Connect提供许多转换,它们都执行简单但有用的修改。可以使用自己的逻辑定制实现转换接口,将它们打包为Kafka Connect插件,将它们与connector一起使用。当转换与source connector一起使用时,Kafka Connect通过第一个转换传递connector生成的每条源记录,第一个转换对其进行修改并输出一个新的源记录。将更新后的源记录传递到链中的下一个转换,该转换再生成一个新的修改后的源记录。最后更新的源记录会被转换为二进制格式写入到kafka。转换也可以与sink connector一起使用。
安装和初体验
Kafka Connect 当前支持两种执行方式,单机(单个进程)和分布式。
1、单机模式
./connect-standalone.sh ../config/connect-file.properties ../config/connect-file-source.properties ../config/connect-file-sink.properties
2、分布式
下载相应的第三方Connect后打包编译。
将jar丢到Kafka的libs目录下。
启动connector。
使用Rest API提交connector配置。
./connect-distributed.sh ../config/connect-distributed.properties
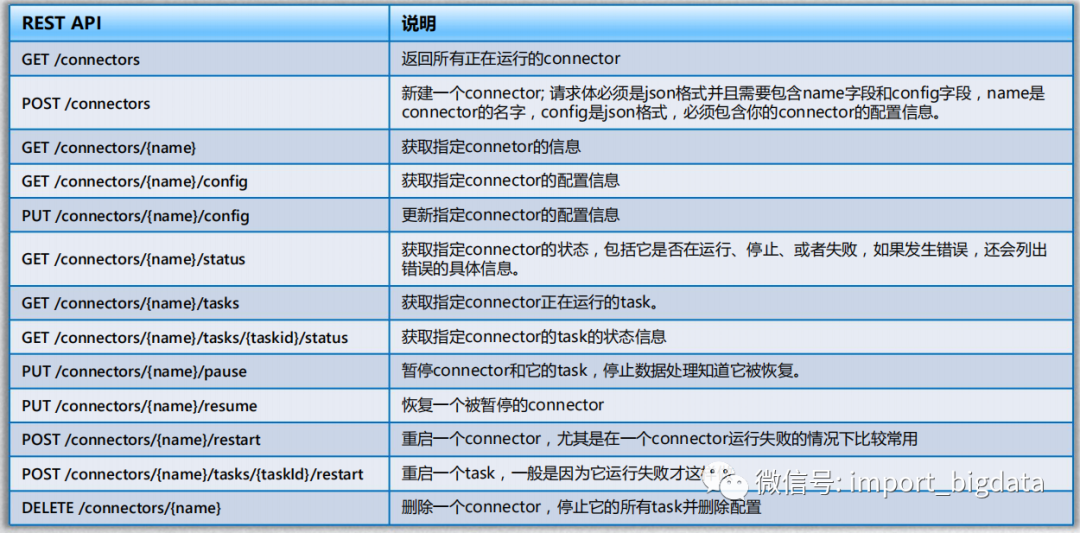
由于Kafka Connect 旨在作为服务运行,它还提供了一个用于管理 connectors 的REST API。默认情况下,此服务在端口8083上运行,支持的一些接口列表如图:
下面我们按照官网的步骤来实现Kafka Connect官方案例,使用Kafka Connect把Source(test.txt)转为流数据再写入到Destination(test.sink.txt)中。如下图所示:
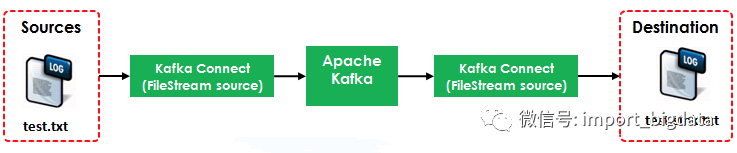
本例使用到了两个Connector:
FileStreamSource:从test.txt中读取并发布到Broker中
FileStreamSink:从Broker中读取数据并写入到test.sink.txt文件中
其中的Source使用到的配置文件是${KAFKA_HOME}/config/connect-file-source.properties
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=test.txt
topic=connect-test其中的Sink使用到的配置文件是${KAFKA_HOME}/config/connect-file-sink.properties
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=test.sink.txt
topics=connect-testBroker使用到的配置文件是${KAFKA_HOME}/config/connect-standalone.properties
bootstrap.servers=localhost:9092key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=trueinternal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000然后我们分别启动Source Connector和Sink Connector:
./bin/connect-standalone.sh
config/connect-standalone.properties
config/connect-file-source.properties
config/connect-file-sink.properties
然后我们向文件写入一些数据:
echo 'hello flink01' >> test.txt
echo 'hello flink02' >> test.txt
然后我们就可以在目标文件中看到:
cat test.sink.txt
hello flink01
hello flink02我们在下篇文章中将更为详细的介绍Kafka Connect在实际生产中的应用以及在各大公司的使用情况。
