
什么是ETL?一文掌握ETL设计过程

导读:ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。

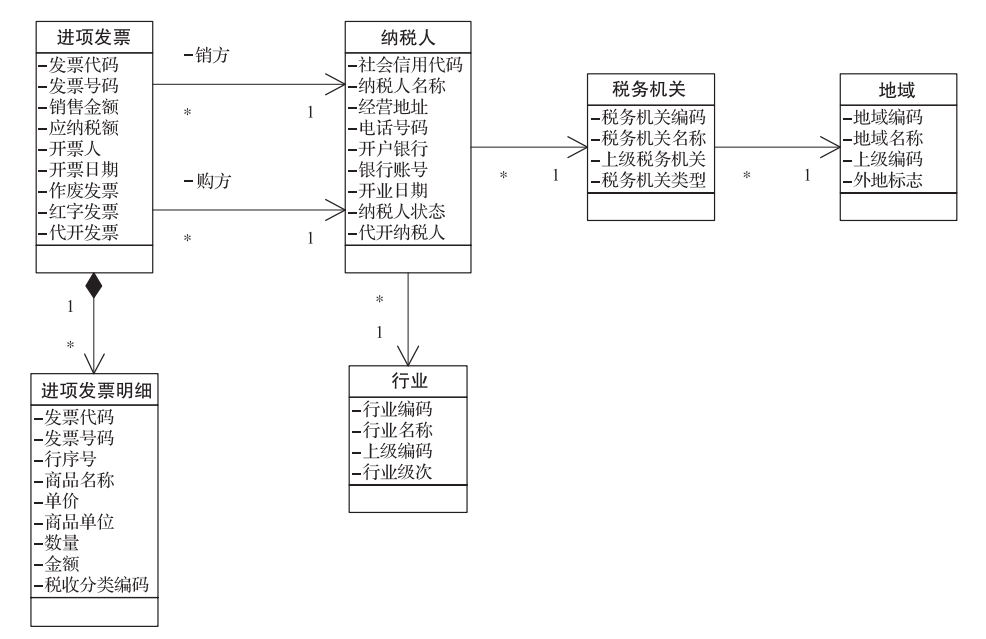
object ZzsfpJx {
def main(args: Array[String]): Unit = {
val task = LogUtils.start("zzsfpJxQd")
try {
val spark = SparkUtils.init("zzsfpJx")
val ETLFPMAPNUM = PropertyFile.getProperty("ETLFPMAPNUM").toInt
spark.udf.register("getJxfpId", (fpdm:String, fphm:String, kprq:String) =>
if(null==kprq) fpdm+"X"+fphm+"X" else fpdm+"X"+fphm+"X"+kprq)
UdfRegister.fillNsr(spark)
UdfRegister.fillSwjg(spark)
UdfRegister.cutSL(spark)
val result = spark.sql("SELECT getJxfpId(D.FPDM,D.FPHM,D.KPRQ) JXFP_ID,D.FPDM,D.
FPHM,'YB' FP_LB,D.JE JE,cast(cutSL(D.SE/D.JE) as double) SL,D.
SE SE,fillNsr(D.XFSBH) XF_NSRSBH, D.XFMC XF_NSRMC, fillNsr(D.GFSBH) GF_NSRSBH,
D.GFMC GF_NSRMC,D.KPRQ, D.KPRQ RZSJ, D.XF_QXSWJG_DM SWJG_DM,
from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') CZSJ,NSR.SWJG_KEY GF_SWJG_DM,
getSwjg(D.XF_QXSWJG_DM,fillNsr(D.XFSBH)) XF_SWJG_DM, case trim(D.fpzt_dm)
when '0' then 'N' when '1' then 'N' else 'Y' end ZFBZ,'' SKM,'' SHRSBH,'
' SHRMC,'' FHRSBH,'' FHRMC,'' QYD,'' SKPH, D.JSHJ,'' CZCH,'' CCDW,''
YSHWXX,D.BZ,D.tspz_dm as TSPZBZ,CASE WHEN
length(trim(D.zfrq))>15 THEN D.zfrq ELSE NULL END ZFSJ FROM dzdz.DZDZ_FPXX_ZZSFP
D JOIN DW.DW_DM_NSR NSR ON D.GFSBH = NSR.NSR_KEY and
NSR.WDBZ='1'").repartition(ETLFPMAPNUM)
DataFrameUtils.saveAppend(result, "etl", "etl_jxfp")
LogUtils.end(task)
} catch { case ex:Exception => LogUtils.error(task, ex) }
}
}val result1 = spark.sql("SELECT getJxfpqdId(R.FPDM,R.FPHM,R.KPRQ,'00','1') JXFPQD_ID,
getJxfpId(R.FPDM,R.FPHM,R.KPRQ) JXFP_ID ,1.0 HH,'YB' FP_LB,
'无商品明细' WP_MC,'' WP_DW,'' WP_XH,1.0 WP_SL,R.JE DJ,R.JE, cast(cutSL(R.SL) as double) SL,R.SE,R.RZSJ, from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') CZSJ,R.KPRQ,'00' QDBZ,'' SKPH,'' SFZHM,'' CD,'' HGZS,'' JKZMSH,'' SJDH,'' FDJHM,
'' CJHM,'' DH,'' ZH,'' KHYH,'' DW,'' XCRS,0.0 JSHJ,'9999999999999999999' spbm "+s"FROM dzdz.DZDZ_HWXX_ZZSFP D
RIGHT JOIN etl.ETL_JXFP R ON (D.FPDM = R.FPDM AND D.FPHM = R.FPHM)
WHERE (D.FPDM is null or D.FPHM is null) and R.FP_LB='YB' ").repartition(ETLFPMAPNUM)
DataFrameUtils.saveAppend(result1, "etl", "etl_jxfp_qd")
延伸阅读👇

《架构真意:企业级应用架构设计方法论与实践》
干货直达👇
评论