
Kettle构建Hadoop ETL实践(二):安装与配置
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源



猜你想看系列:
Kettle构建Hadoop ETL实践(一):ETL与Kettle
目录一、安装1. 安装环境(1)选择操作系统(2)安装规划2. 安装前准备(1)安装Java环境(2)安装GNOME Desktop图形界面(3)安装配置VNC远程控制(4)在客户端安装vncviewer3. 安装运行Kettle(1)下载和解压(2)运行Kettle程序(3)创建Spoon快捷启动方式二、配置1. 配置文件和.kettle目录(1).spoonrc(2)jdbc.properties(3)kettle.properties(4)kettle.pwd(5)repositories.xml(6)shared.xml2. 用于启动Kettle程序的shell脚本(1)shell脚本的结构(2)classpath里增加一个jar包(3)改变虚拟机堆大小(4)修改图形工具包环境3. 管理JDBC驱动三、小结

在前一篇里介绍了ETL和Kettle的基本概念,内容偏重于理论。从本篇开始,让我们进入实践阶段。工欲善其事,必先利其器。既然我们要用Kettle构建Hadoop ETL应用,那么先要做的就是安装Kettle。本篇首先阐述选择安装环境所要考虑的因素,之后详细介绍Kettle的安装过程,最后说明Kettle配置文件、启动脚本和JDBC驱动管理。本专题后面的实践部分都是基于这里所安装的Kettle之上完成的。
1. 安装环境
(1)选择操作系统
有些熟悉Kettle的用户一定会觉得,Kettle的安装过程相当简单,基本上就是开箱即用,而这里所谓的“开箱”也仅仅是执行一个解压缩命令而已,根本没有必要单开一篇文章进行说明。稍安勿躁,且听我慢慢道来。这里要讨论的是在Linux系统而不是Windows上安装Kettle,原因有如下两点:
用户和权限问题
Windows上运行的Kettle在连接Hadoop集群时,需要在HDFS上建立Windows登录用户的主目录,并进行权限配置。否则在测试Hadoop集群连接时,User Home Directory Access和Verify User Home Permissions会报错。hdfs是启动其进程所使用的用户,而Kettle始终用本机用户连接Hadoop集群。通常Linux和Windows系统上缺省创建的用户名是不同的,因此需要在HDFS上创建Windows用户目录:
hdfs dfs -mkdir /user/Windows用户名缺省Hadoop并不进行用户验证,这个工作交由操作系统代劳。为解决Verify User Home Permissions问题,需要在config.properties文件(该文件在Kettle安装目录下的hadoop插件目录下,例如D:\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh61)中添加配置:
authentication.superuser.provider=NO_AUTH最后重启Kettle使配置生效。
Kettle中执行MapReduce报错
Windows上的Kettle在执行Pentaho MapReduce作业项时会报类似下面的错误:
ERROR (version 8.3.0.0-371, build 8.3.0.0-371 from 2019-06-11 11.09.08 by buildguy) : org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)ZERROR (version 8.3.0.0-371, build 8.3.0.0-371 from 2019-06-11 11.09.08 by buildguy) : java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Zat org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:606)at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1202)at org.apache.hadoop.fs.FileUtil.list(FileUtil.java:1407)at org.apache.hadoop.fs.RawLocalFileSystem.listStatus(RawLocalFileSystem.java:468)at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1853)at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1895)at org.apache.hadoop.fs.ChecksumFileSystem.listStatus(ChecksumFileSystem.java:678)at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:395)at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:379)at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:2354)at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:2320)at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:2283)at org.pentaho.hadoop.shim.common.DistributedCacheUtilImpl.stageForCache(DistributedCacheUtilImpl.java:443)at org.pentaho.hadoop.shim.common.DistributedCacheUtilImpl.stageForCache(DistributedCacheUtilImpl.java:713)at org.pentaho.big.data.impl.shim.mapreduce.PentahoMapReduceJobBuilderImpl.stageMetaStoreForHadoop(PentahoMapReduceJobBuilderImpl.java:587)at org.pentaho.big.data.impl.shim.mapreduce.PentahoMapReduceJobBuilderImpl.submit(PentahoMapReduceJobBuilderImpl.java:534)at org.pentaho.big.data.impl.shim.mapreduce.MapReduceJobBuilderImpl.submit(MapReduceJobBuilderImpl.java:277)at org.pentaho.big.data.kettle.plugins.mapreduce.entry.pmr.JobEntryHadoopTransJobExecutor.execute(JobEntryHadoopTransJobExecutor.java:780)at org.pentaho.di.job.Job.execute(Job.java:686)at org.pentaho.di.job.Job.execute(Job.java:827)at org.pentaho.di.job.Job.execute(Job.java:498)at org.pentaho.di.job.Job.run(Job.java:384)
如果说上一个问题能通过修改配置的方式来解决还是可接受的,那么这个问题则需要修改Hadoop中NativeIO类的源代码并重新编译来解决。该方案对于非程序员用户来说确是强人所难了。
Linux上运行的Kettle不存在上述两个问题。我们只要使用Linux系统中缺省创建的用户(如root)运行Kettle,就能成功访问Hadoop集群,因为Hadoop集群同样是安装部署在Linux系统之上。而且Linux上的Kettle执行Pentaho MapReduce作业项也不会报NativeIO错误。这就是我们选择Linux作为Kettle安装平台的原因。
下面就要解决确定Linux平台所引入的一系列相关问题:
为了使用Kettle GUI,需要安装Linux图形环境,如GNOME。
为了远程访问Linux图形环境,需要安装远程控制软件,如VNC Server和VNC Client。
为了使用中文输入和显示,需要安装相应的输入法,如智能拼音。
创建Kettle桌面快捷启动方式。
(2)安装规划
这里只是演示Kettle安装的过程,不作为生产环境使用,因此建立四台Linux虚机,每台硬盘50G,内存8G。IP与主机名如下:
172.16.1.101 hdp1
172.16.1.102 hdp2
172.16.1.103 hdp3
172.16.1.104 hdp4
主机规划:以上四台主机构成Kettle集群。本篇只说明在172.16.1.101一台主机上的安装过程,其它三台主机上的Kettle安装过程完全相同。Kettle集群的配置和使用,详见本专题的(十一)Kettle集群与数据分片。
操作系统:CentOS Linux release 7.2.1511 (Core)
Java版本:openjdk version 1.8.0_262
Kettle版本:GA Release 8.3.0.0-371
2. 安装前准备
(1)安装Java环境
Kettle是一个Java程序,需要Java运行时环境(Java虚拟机/JVM和一组运行时类)。Kettle与Java的版本要匹配,本例中的Kettle 8.3需要Java 1.8的支持。如果只是运行Kettle,只需要安装Java Runtime Environment(JRE) 1.8。如果要从源代码编译Kettle或自己开发Kettle插件,需要安装Java Development Kit(JDK) 1.8。
手工安装Java
从https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html下载Linux x64 RPM Package对应的RPM包。下载后直接使用rpm命令进行安装,例如:
rpm -ivh jdk-8u261-linux-x64.rpm使用yum
yum全称为 Yellowdog Updater Modified,是一个在Fedora、RedHat以及CentOS中流行的shell前端软件包管理器。它基于RPM包管理,能够从指定的服务器(在资源库文件中定义)自动下载安装RPM包,并且可以自动处理依赖性关系,一次安装所有依赖的软件包,无须繁琐地一次次下载安装。yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁好记。
在CentOS下使用yum安装Java非常简单:
# 查找yum资源库中的java包yum search java | grep -i --color JDK# 安装Java 1.8yum install -y java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64# 验证安装java -version
如果在本地资源库中没有需要安装的软件包,可以从网上下载公开的yum源。例如将http://mirrors.163.com/.help/CentOS7-Base-163.repo文件下载到本地的/etc/yum.repos.d/目录下,然后再执行yum命令即可。
(2)安装GNOME Desktop图形界面
这里选择GNOME Desktop作为运行Kettle界面的图形环境。GNOME Desktop是主流Linux发行版本的默认桌面,主张简约易用,够用即可。GNOME的全称为GNU网络对象模型环境(The GNU Network Object Model Environment),基于GTK+图形库,使用C语言开发,官方网站是gnome.org。
1. 安装GNOME Desktop
# 列出可安装的桌面环境
yum grouplist
此命令显示了系统安装过程中没有被安装的软件组,下面是本例中该命令的部分输出:
...
Available Environment Groups:
...
GNOME Desktop
KDE Plasma Workspaces
...
Available Groups:
...
Graphical Administration Tools
...
从中我们可以看到,Centos 7中有两大桌面环境安装组GNOME Desktop和KDE Plasma Workspaces。执行下面的命令安装GNOME Desktop。
yum groupinstall "GNOME Desktop" -yyum groupinstall命令安装一组软件包,这组软件包包含了很多单个软件,以及各个软件之间的依赖关系。-y参数表示安装过程中省略确认,避免交互式输入。当安装成功后,可以再次执行yum grouplist命令,从输出中可以看到已经安装的GNOME Desktop。
...
Installed Environment Groups:
GNOME Desktop
...
2. 配置中文支持
locale -a命令列出当前系统支持的所有语言包。如果没有zh_CN,则需要先安装一个中文语言包,例如:
yum install kde-l10n-Chinese如果系统包含中文语言包,但在安装CentOS 7时没有选择中文,安装完成后需要再使用中文,可以按照下面的步骤进行操作。
# 安装系统语言配置工具yum install -y system-config-language# 执行语言配置system-config-language# 选择“chinese (P.R. of China) - 中文(简体)”。
确定后,会自动将系统语言设置成zh_CN.UTF-8。也可以执行下面的命令修改系统默认语言为中文:
localectl set-locale LANG=zh_CN.UTF-8可以在终端输入locale命令查看更改后的系统语言变量,输出如下:
LANG=zh_CN.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER="zh_CN.UTF-8"
LC_NAME="zh_CN.UTF-8"
LC_ADDRESS="zh_CN.UTF-8"
LC_TELEPHONE="zh_CN.UTF-8"
LC_MEASUREMENT="zh_CN.UTF-8"
LC_IDENTIFICATION="zh_CN.UTF-8"
LC_ALL=
然后执行下面的命令安装中文拼音输入法:
yum install -y ibus ibus-libpinyin最后重启系统:
reboot(3)安装配置VNC远程控制
为了能够在远程终端中使用GNOME桌面环境,需要安装配置VNC软件。VNC(Virtual Network Console)是虚拟网络控制台的缩写。它是一款优秀的远程控制工具,是基于UNIX和Linux操作系统的免费开源软件,远程控制能力强大,高效实用。在Linux中,VNC 包括四个命令:vncserver、vncviewer、vncpasswd和vncconnect。大多数情况下用户只需要其中的两个命令,即vncserver和vncviewer。
VNC服务器工具有很多,例如tightvnc、vnc4server、tigervnc、realvnc等。这里选择tigervnc作为VNC服务器。tigervnc包含服务器控制端用于实现vnc服务,其中包含一个名为X0VNC的特殊服务,该服务运行后可以把当前桌面会话远程传输给远端客户端让其操控,而不是传统VNC的虚拟会话桌面模式。执行以下步骤安装配置tigervnc服务器。
1. 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2. 关闭seLinux
# 查看状态
sestatus
# 临时关闭
setenforce 0
# 永久关闭
vim /etc/sysconfig/selinux
SELINUX=disabled
3. 安装tigervnc服务器
yum install -y tigervnc-server4. 启动vncserver
# 启动
vncserver
命令输出如下:
You will require a password to access your desktops.Password:Verify:Would you like to enter a view-only password (y/n)? nA view-only password is not usedNew 'hdp1:1 (root)' desktop is hdp1:1Creating default startup script /root/.vnc/xstartupCreating default config /root/.vnc/configStarting applications specified in /root/.vnc/xstartupLog file is /root/.vnc/hdp1:1.log
首次启动vncserver时提示输入设置远程连接密码,可以不同于本地密码,该密码以后可以使用vncpasswd命令重置。注意当出现 Would you like to enter a view-only password (y/n)? 提示时输入n。
# 查看vncserver进程列表
vncserver -list
命令输出如下,显示当前启动了一个VNC服务器进程:
TigerVNC server sessions:
X DISPLAY # PROCESS ID
:1 2431
5. 设置自动启动的vncserver服务
# 复制缺省配置文件cp /lib/systemd/system/vncserver@.service /lib/systemd/system/vncserver@:1.service# 修改配置文件/lib/systemd/system/vncserver@:1.service,内容如下(主要是修改root用户):[Unit]Description=Remote desktop service (VNC)After=syslog.target network.target[Service]Type=forkingUser=root# Clean any existing files in /tmp/.X11-unix environmentExecStartPre=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :'ExecStart=/sbin/runuser -l root -c "/usr/bin/vncserver %i"PIDFile=/root/.vnc/%H%i.pidExecStop=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :'[Install]WantedBy=multi-user.target# 重新加载服务配置文件systemctl daemon-reload# 设置开机启动systemctl enable vncserver@:1.service# 重启系统reboot
(4)在客户端安装vncviewer
从https://www.realvnc.com/en/connect/download/viewer/下载对应操作系统的安装文件,这里为VNC-Viewer-6.19.1115-Windows.exe。直接运行该文件进行安装,安装目录为缺省。成功安装后运行 C:\Program Files\RealVNC\VNC Viewer\vncviewer.exe 文件打开VNC Viewer,点击右键菜单中的“New connection...”,在VNC Server中输入VNC服务器地址,本例为172.16.1.101:1,如图2-1所示,然后点击OK按钮保存。冒号后面的1指定一个TigerVNC server sessions号。
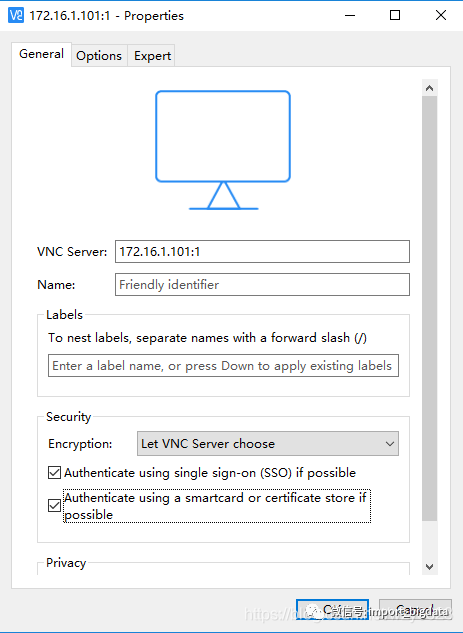 图2-1 在VNC Viewer添加新连接
图2-1 在VNC Viewer添加新连接双击刚才建立的连接,输入并保存初次启动VNC服务器时设置(或者由vncpasswd所设置)的密码,如图2-2所示。
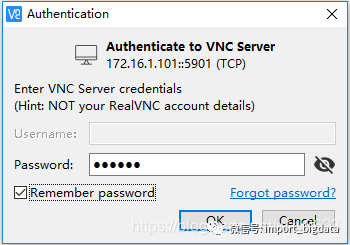 图2-2 输入并保存VNC连接密码
图2-2 输入并保存VNC连接密码在第一次使用GNOME Desktop时,需要进行一些初始化设置,如配置语言、时区和输入法等。因为我们已经设置了系统的缺省语言为中文,并且安装了拼音输入法,所以缺省选择就是中文。配置好打开的GNOME桌面如图2-3所示,界面显示为中文,并支持中文输入。
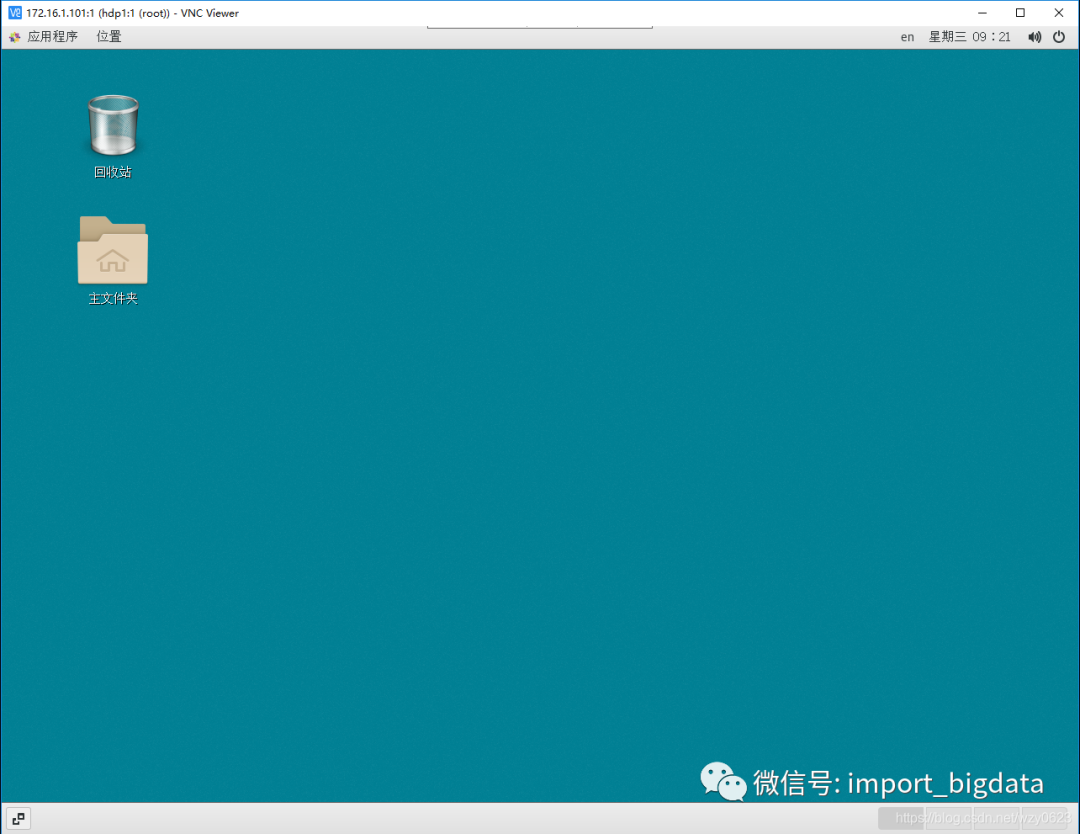 图2-3 支持中文的GNOME桌面
图2-3 支持中文的GNOME桌面也可以随时在GNOME桌面环境中设置语言和时区相关选项,例如执行以下步骤添加中文拼音输入法。
1. 选择菜单“应用程序” -> “系统工具” -> “设置” -> “Region & Language”,打开如图2-4所示的窗口。
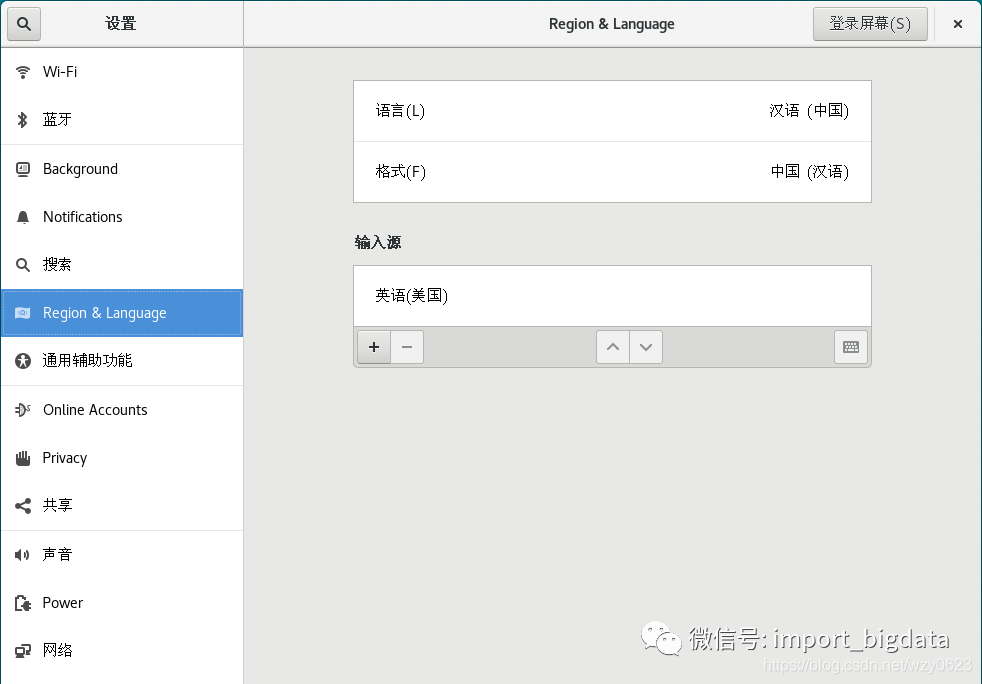 图2-4 设置语言和时区
图2-4 设置语言和时区
2. 在图2-4中点击“输入源”下的“+”按钮,在弹出窗口中选择“汉语(中国)” -> “汉语(Intelligent Pinyin)”,如图2-5所示。
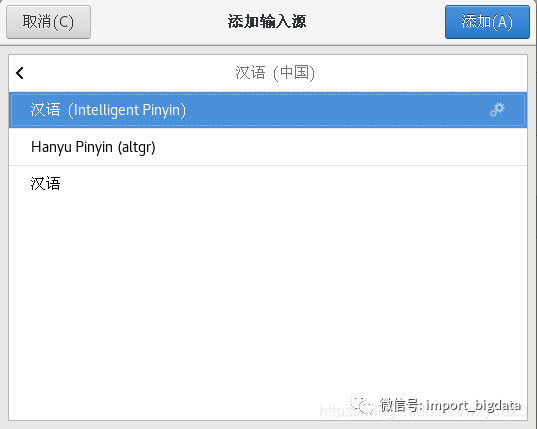 图2-5 添加中文拼音输入法
图2-5 添加中文拼音输入法点击图2-5中的“添加”按钮就可添加输入法。缺省使用“Super+空格”组合键切换输入法,Super键就是普通键盘上的Win键。下面还有一步操作是将ibus拼音输入法设置为默认输入方法。如果缺少了这一步,每次重启系统后ibus拼音输入法就不能正常工作。设置方法为,在GNOME桌面点击右键菜单中的“打开终端”,在终端窗口中执行以下命令:
# 安装输入法选择器
yum install im-chooser
# 设置默认输入法
imsettings-switch ibus
注意一定要在图形界面下的终端窗口而不是字符界面控制台执行命令,如图2-6所示。
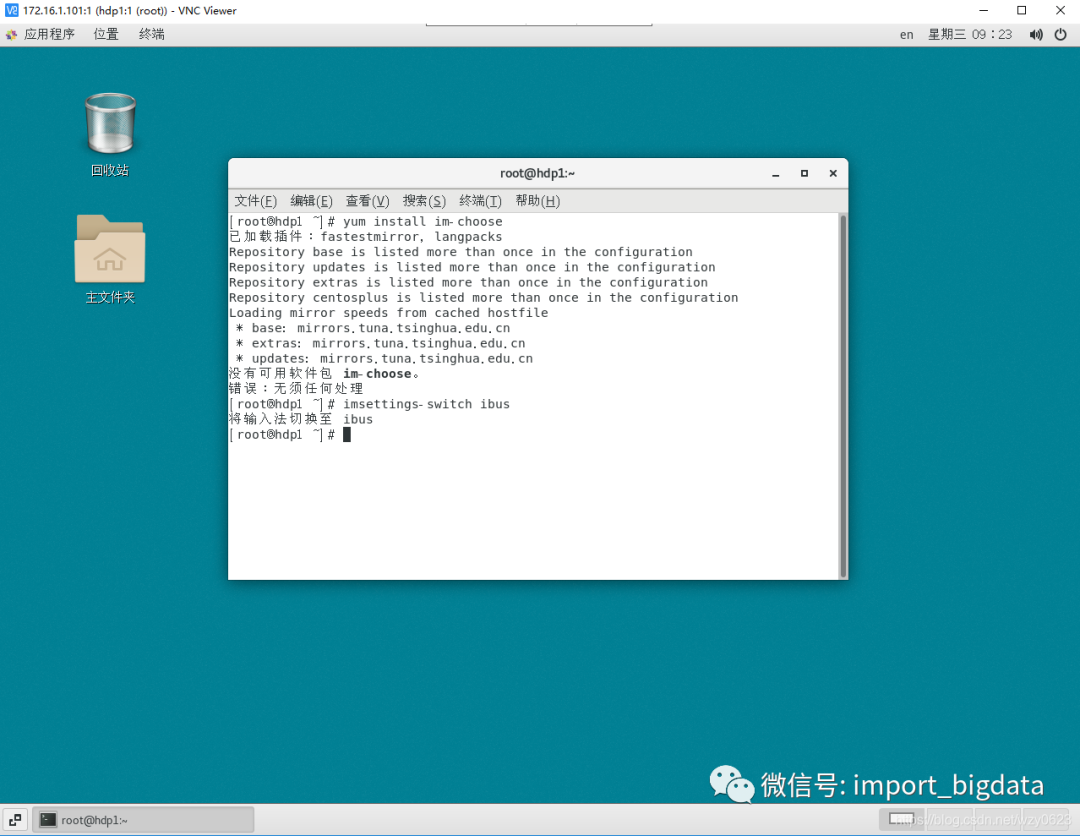 图2-6 设置默认输入法
图2-6 设置默认输入法至此,Kettle安装前的准备工作已经完成,Java环境、图形界面、中文支持、远程控制都已配置好。
3. 安装运行Kettle
Kettle作为一个独立的压缩包发布,可以从sourceforge.net上下载。作为Pentaho BI项目的一部分,可以在https://sourceforge.net/projects/pentaho/files目录下找到Kettle的所有版本。
(1)下载和解压
在sourceforge网站上,每个版本都对应一个独立的目录,目录名就是版本号。例如本专题中使用的是8.3版本,所属目录为Pentaho 8.3。在该目录下包含 shims、server、plugins、other、client-tools五个子目录,Kettle在client-tools目录下。sourceforge版本路径下保存的归档文件是zip格式,还有与.zip文件对应的.sum文件,用于校验zip文件的完整性,一般只需要下载.zip文件。归档文件的命名格式依照pdi-ce-version-extension格式,pdi代表Pentaho Data Integration,ce代表Community Edition。Kettle是跨平台的,无论什么操作系统都是同一下载文件。
可以直接从浏览器中下载,或者使用终端命令行工具(如wget)下载。本例执行下面的命令将Kettle 8.3版本zip文件下载到本地,然后进行解压缩:
# 下载安装包wget https://sourceforge.net/projects/pentaho/files/Pentaho%208.3/client-tools/pdi-ce-8.3.0.0-371.zip# 解压缩,会创建data-integration目录unzip pdi-ce-8.3.0.0-371.zip# 修改目录名使之包含版本号mv data-integration pdi-ce-8.3.0.0-371
Kettle不关心被解压缩到哪个目录下,所以可以根据实际情况来解压缩。例如在Windows开发环境下,一般是在Program Files目录下创建kettle或pentaho目录,然后解压缩到这个目录下。在类UNIX系统下,如果用于开发目的,一般在home目录下创建一个目录。如果用于生产环境,一般创建/opt/kettle或/opt/pentaho目录。
解压缩归档文件会产生一个data-integration目录。最好重新命名这个目录,以反映出原来的版本号。一个比较好的方法就是简单地命名为压缩文件的文件名,但不包括扩展名。我们使用Kettle根目录一词来表示这个安装目录。
重命名目录使之包含版本号,可以让在这个环境下工作的人一眼就看出目录下的Kettle是哪个版本。这也便于在一个目录下同时维护多个Kettle版本,当希望测试新版本或进行Kettle版本升级时就可以看出这种命名方式的优点。
(2)运行Kettle程序
所有Kettle程序都可以通过运行Kettle根目录下的shell脚本来启动。在运行shell脚本上Windows和类UNIX系统基本相同。运行Kettle的shell脚本要求当前的工作目录就是Kettle根目录。这意味着在写自己的shell脚本时,调用Kettle程序之前,需要先切换工作路径到Kettle根目录下。
解压缩之后,Windows用户通过执行Kettle根目录下的bat文件启动Kettle程序。例如,要设计转换或作业可以双击Spoon.bat来启动Spoon。要执行作业可以在命令行下运行Kitchen.bat,或在自己的脚本里调用这个bat文件。
对于类UNIX系统来说,可以执行相应的.sh脚本来运行Kettle,但要在运行之前设置.sh文件可执行。例如,在Kettle根目录下可以通过执行下面的命令让所有.sh文件可执行:
chmod 755 *.sh执行完该命令后就可以运行所有脚本了,当然前提是Kettle根目录是当前工作目录。本例在GNOME桌面打开一个终端窗口执行下面的命令,即可启动spoon界面。
cd pdi-ce-8.3.0.0-371/
./spoon.sh
(3)创建Spoon快捷启动方式
因为经常要使用Spoon,可能希望在任务栏或桌面上创建一个Spoon的快捷方式。Windows用户可以打开资源管理器到Kettle根目录,然后选中Spoon.bat,在右键弹出菜单中选择“发送到”->“桌面快捷方式”。这样就在桌面上创建了一个快捷方式(.lnk)文件用于启动Spoon。
右键单击新创建的快捷文件,在弹出菜单中选择“属性”。打开的属性对话框里显示了“快捷方式”标签。在这个标签下,“目标”和“起始位置”输入框已经被正确填写,不用编辑这些属性。“更改图标”按钮可以为这个快捷方式选中一个容易识别的图标,一般选择Kettle根目录下的spoon.ico文件。
在GNOME桌面上也可以创建应用的快捷启动方式,但方法比Windows稍微复杂一些。GNOME系统中的桌面快捷方式文件称为 Desktop Entry 文件,以".desktop"为后缀。每个应用程序快捷方式都和一个 Desktop Entry 文件相对应。本例中我们希望使用root用户执行Spoon程序,因此创建/root/桌面/Spoon.desktop文件,内容如下:
[Desktop Entry]
Encoding=UTF-8
Name=spoon
Exec=sh /root/pdi-ce-8.3.0.0-371/spoon.sh
Terminal=false
Type=Application
Desktop Entry 文件通常以字符串"[Desktop Entry]"开始。文件的内容由若干键值对条目组成。Desktop Entry 文件定义了一系列标准关键字。标准关键字分为必选和可选两种:必选标准关键字必须在 .desktop 文件中被定义;而可选关键字则不必。以下是对本例中所使用关键字的简单描述。
Encoding[可选]:指定了当前 Desktop Entry 文件中特定字符串所使用的编码方式。
Name[必选]:指定了桌面快捷方式显示的名称。
Exec[可选]:关键字“Exec”只有在“Type”类型是“Application”时才有意义。“Exec”的值定义了启动指定应用程序所要执行的命令,在此命令是可以带参数的。
Terminal[可选]:关键字“Terminal”的值是布尔值(true或false),并且该关键字只有在“Type”类型是“Application”时才有意义。其值指出了相关应用程序(即关键字“Exec”的值)是否在终端窗口中运行。
Type[必选]:关键字“Type”定义了Desktop Entry文件的类型。常见的值是“Application”和“Link”。“Application”表示当前Desktop Entry文件指向了一个应用程序,而“Link”表示当前Desktop Entry文件指向了一个URL(Uniform Resource Locator)。
关于Desktop Entry的完整说明参见https://developer.gnome.org/desktop-entry-spec/。
创建/root/桌面/Spoon.desktop文件后,在GNOME桌面按F5刷新桌面,会看到桌面上出现了一个名为“Spoon.desktop”的图标,如图2-7(a)所示。
 图2-7 GNOME桌面快捷方式
图2-7 GNOME桌面快捷方式
双击该图标,首次执行会出现如图2-8所示的警告信息。
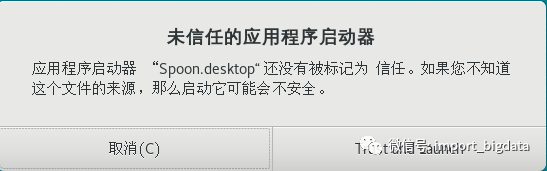 图2-8 未信任的应用程序启动器提示
图2-8 未信任的应用程序启动器提示点击图2-8中的“Trust and Launch”按钮,信任并启动spoon程序,之后再运行桌面快捷方式将不会弹出未信任应用的警告。同时桌面上对应的图标和名称也会变为如图2-7(b)所示。
与Windows快捷方式类似,点击桌面快捷方式图标右键,在弹出菜单中选择“属性”,点击对话框中的图标,可以选择更换自定义图标。例如选择了spoon.ico作为图标后如图2-7(c)所示。
至此Kettle在Linux上安装的所有技术细节都已完成。
二、配置Kettle运行环境内的一些因素会影响其运行方式。这些因素包括配置文件和与Kettle集成在一起的外部软件。我们把这些因素统称为Kettle的配置。将在本节了解到Kettle的配置包括哪些部分,以及应如何管理这些配置。
1. 配置文件和.kettle目录
Kettle运行环境中有几个文件影响了它的运行情况,这些文件可以看成是Kettle配置文件。当Kettle做了环境移植或升级时,这些文件也要随之改变,包括:
.spoonrc
jdbc.properties
kettle.properties
kettle.pwd
repositories.xml
shared.xml
.spoonrc文件只用于spoon程序,其余的则用于Kettle里的多个程序。这些文件大部分都存放在.kettle目录下。.kettle目录默认情况下位于操作系统用户的主目录下,每个用户都有自己的主目录(如/home/
.kettle目录的位置也可以配置,这需要设置KETTLE_HOME环境变量。例如在生产机器上,可能希望所有用户都使用同一个配置来运行转换和作业,就可以设置KETTLE_HOME使之指向一个目录,这样所有操作系统用户就可以使用相同的配置文件了。与之相反,也可以给某个ETL项目设置一个特定的配置目录,此时需要在运行这个ETL的脚本里设置KETTLE_HOME环境变量。
下面说明每个配置文件的作用。
(1).spoonrc
从名字就可以看出,.spoonrc文件用于存储Spoon程序的运行参数和状态。其它Kettle的程序都不使用这个文件。.spoonrc文件位于.kettle目录下。因为在默认情况下,.kettle目录位于用户主目录下,所以不同用户都使用各自的.spoonrc文件。.spoonrc文件中包括的主要属性如下:
通用的设置和默认值:在Spoon里,这些设置在“选项”对话框的“一般”标签下设置。“选项”对话框可以通过主菜单的“工具” -> “选项”菜单项打开。
外观,例如字体和颜色:在Spoon里,这些都在“选项”对话框的“观感”标签下。
程序状态数据:如最近使用的文件列表。
通常不用手工编辑.spoonrc文件。如果新安装了一个Kettle代替一个旧版本的Kettle,可用旧版本的.spoonrc文件覆盖新安装的.spoonrc文件,这样来保留旧版本Kettle的运行状态。为了保留历史版本以备恢复之需,定时备份.spoonrc文件也是必要的。
(2)jdbc.properties
Kettle还有一个jdbc.properties文件,保存在Kettle根目录下的simple-jndi子目录下。这个文件用来存储JNDI连接对象的连接参数。Kettle可以用JNDI的方式引用JDBC连接参数,如IP地址、用户认证等,这些连接参数最终用来在转换和作业中构造数据库连接对象。
JNDI是Java Naming and Directory Interface的缩写,是一个Java标准,可以通过一个名字访问数据库服务。注意JNDI只是Kettle指定数据库连接参数的一种方式,数据库连接参数也可以保持在转换或作业的数据库连接对象或资源库里。JNDI数据库连接配置是整个Kettle配置的一部分。
在jdbc.properties文件里,JNDI连接参数以多行文本形式保存,每一行就是一个键值对,等号左右分别是键和值。键包括了JNDI名字和一个属性名,中间用反斜线分隔。属性名前的JNDI名称决定了JNDI连接包括几行参数。以JNDI名称开头的行就构成了建立连接需要的所有参数。如下是一些属性名称:
type:这个属性的值永远是javax.sql.DataSource。
driver:实现了JDBC里Driver类的全名。
url:用于连接数据库的JDBC URL连接串。
user:数据库用户名。
password:数据库密码。
下面是一个jdbc.properties里保存JNDI连接参数的例子:
SampleData/type=javax.sql.DataSourceSampleData/driver=org.h2.DriverSampleData/url=jdbc:h2:file:samples/db/sampledb;IFEXISTS=TRUESampleData/user=PENTAHO_USERSampleData/password=PASSWORD
在这个例子里,JNDI名字是SampleData,可用于建立h2数据库的连接,数据库用户名是PENTAHO_USER,密码是PASSWORD。
可以按照SampleData的格式,把自己的JNDI名字和连接参数写到jdbc.properties文件里。因为在jdbc.properties里定义的连接可以在转换和作业里使用,用户需要保存好这个文件,至少需要做定时备份。
另外还需要注意部署问题,在部署使用JNDI方式的转换和作业时,记住需要更改部署环境里的jdbc.properties文件。如果开发环境和实际部署环境相同,就可以直接使用开发环境里的jdbc.properties文件。但大多数情况下,开发环境使用的是测试数据库,在把开发好的转换和作业部署到实际生产环境中后,需要更改jdbc.properties的内容,使之指向实际生产数据库。使用JNDI的好处就是部署时不用再更改转换和作业,只需要更改jdbc.properties里的连接参数。
(3)kettle.properties
kettle.properties文件是一个通用的保存Kettle属性的文件。属性对Kettle而言就如同环境变量对操作系统的shell命令。它们都是全局字符串变量,用于把作业和转换参数化。例如,可以使用一个属性来保存数据库连接参数、文件路径,或一个用在某个转换里的常量。
kettle.properties文件使用文本编辑器来编辑。一个属性是一个等号分隔的键值对,占据一行。键在等号前面,作为以后使用的属性名,等号后面就是这个属性的值。下面是一个kettle.properties文件的例子:
# connection parameters for the job server
DB_HOST=dbhost.domain.org
DB_NAME=sakila
DB_USER=sakila_user
DB_PASSWORD=sakila_password
# path from where to read input files
INPUT_PATH=/home/sakila/import
# path to store the error reports
ERROR_PATH=/home/sakila/import_errors
转换和作业可以通过${属性名}或%%属性名%%的方式来引用kettle.properties里定义的这些属性值,用于对话框里输入项的变量。图2-9显示的是CSV输入步骤对话框。
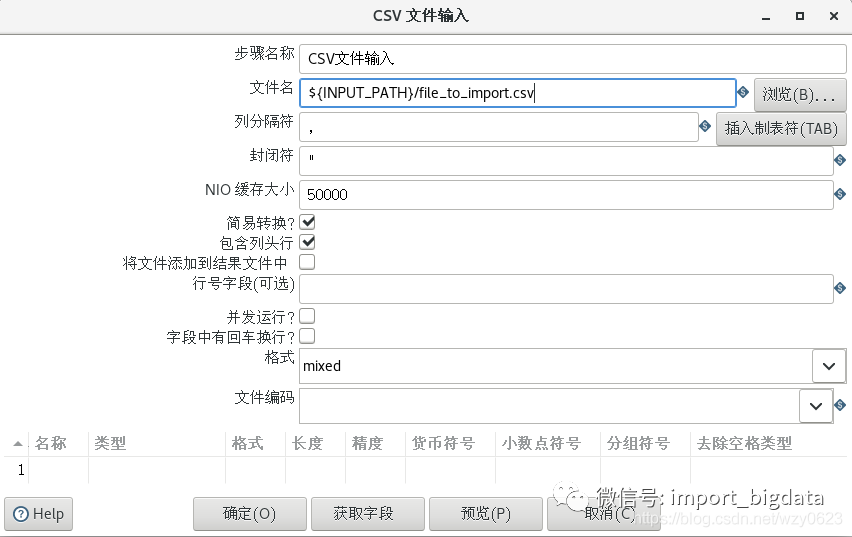 图2-9 引用kettle.properties文件里定义的变量
图2-9 引用kettle.properties文件里定义的变量如图中所示,在文件名字段里不再用硬编码路径,而使用了变量的方式${INPUT_PATH}。对任何带有“$”符号的输入框都可以使用这种变量的输入方式。在运行阶段,这个变量的值就是/home/sakila/import,即在kettle.properties文件里设置的值。
这里属性的使用方式和前面讲过的jdbc.properties里定义的JNDI连接参数的使用方式类似。例如可以在开发和生产环境中使用不同的kettle.properties文件,以便快速切换。尽管使用kettle.properties和jdbc.properties相似,但也有区别。首先,JNDI只用于数据库连接,而属性可用于任何情况。其次,kettle.properties里的属性名字可以是任意名字,而JNDI里的属性名是预先定义好的,只用于JDBC数据库连接。
关于kettle.properties文件还有一点要说明:kettle.properties文件里可以定义用于资源库的一些预定义变量。如果使用资源库保存转换或作业,如下这些预定义变量就可以定义一个默认资源库:
KETTLE_REPOSITORY:默认的资源库名称。
KETTLE_USER:资源库用户名。
KETTLE_PASSWORD:用户名对应的密码。
使用上面这些变量,Kettle会自动使用KETTLE_REPOSITORY定义的资源库。
(4)kettle.pwd
使用Carte服务执行作业需要授权。默认情况下,Carte只支持最基本的授权方式,就是将密码保存在kettle.pwd文件中。kettle.pwd文件位于Kettle根目录下的pwd目录下。kettle.pwd文件的默认内容如下:
# Please note that the default password (cluster) is obfuscated using the Encr script provided in this release
# Passwords can also be entered in plain text as before
#
cluster: OBF:1v8w1uh21z7k1ym71z7i1ugo1v9q
最后一行定义了一个用户cluster,以及加密后的密码(这个密码也是cluster)。文件的注释部分说明了这个加密的密码是由Encr.bat或encr.sh脚本生成的。如果使用Carte服务,尤其当Carte服务不在局域网范围内时,就要编辑kettle.pwd文件,至少要更改默认密码。直接使用文本编辑器就可以编辑。
(5)repositories.xml
Kettle可以通过资源库管理转换、作业和数据库连接这样的资源。如果不使用资源库,转换、作业也可以保存在文件里,每一个转换和作业都保存各自的数据库连接。Kettle资源库可以存储在关系数据库里,也可以使用插件存储到其它存储系统,例如存储到一个像SVN这样的版本控制系统。为了使操作资源库更容易,Kettle在repositories.xml文件中保存了所有资源库。repositories.xml文件可以位于两个目录:
位于用户主目录(由Java环境变量中的user.home变量指定)的.kettle目录下。Spoon、Kitchen、Pan会读取这个文件。
Carte服务会读取当前启动路径下的repositories.xml文件。如果当前路径下没有,会使用上面的用户主目录下的.kettle目录下的repositories.xml文件。
对开发而言,不用手工编辑这个文件。无论什么时候连接到了资源库,这个文件都由Spoon自动维护。但对部署而言情况就不同了,在部署的转换或作业里会使用资源库的名字,所以在repositories.xml文件里必须要有一个对应的资源库的名字。和上面讲到的jdbc.properties或kettle.properties文件类似,实际运行环境的资源库和开发时使用的资源库往往是不同的。实践中一般直接将repositories.xml文件从开发环境复制到运行环境,并手工编辑这个文件使之匹配运行环境。
(6)shared.xml
Kettle里有一个概念叫共享对象,共享对象就是类似于转换的步骤、数据库连接定义、集群服务器定义等这些可以一次定义,然后在转换和作业里多次引用的对象。共享对象在概念上和资源库有一些重叠,资源库也可以被用来共享数据库连接和集群服务器的定义,但还是有一些区别。资源库往往是一个中央存储,多个开发人员都访问同一个资源库,用来维护整个项目范围内所有可共享的对象。
在Spoon里单击左侧树状列表的“主对象树”标签,选择想共享的对象。右键单击,然后在弹出菜单中选择“Share”。必须保存文件,否则该共享不会被保存。以这种方式创建的共享可以在其它转换或作业里使用(可以在左侧树状列表的“主对象树”标签中找到)。但是,共享的步骤或作业项不会被自动放在画布里,需要把它们从树状列表中拖到画布里,以便在转换或作业里使用。
共享对象存储在shared.xml文件中。默认情况下,shared.xml文件保存在.kettle目录下,.kettle目录位于当前系统用户的主目录下。也可以给shared.xml文件自定义一个存储位置。这样用户就可以在转换或作业里多次使用这些预定义好的共享对象。在转换或作业的设置对话框里可以设置shared.xml文件的位置。对作业来说,在“作业设置”对话框的“设置”标签下。对转换而言,在“转换设置”对话框的“杂项”标签下。
可以使用变量指定共享文件的位置。例如,在转换里可以使用类似下面的路径:
${Internal.Transformation.Filename.Directory}/shared.xml这样不论目录在哪里,所有一个目录下的转换都可以使用同一个共享文件。对部署而言,需要确保任何在开发环境中直接或间接使用的共享文件也要在部署环境中可以找到。一般情况下,在两种环境中,共享文件应该是一样的。所有环境差异的配置应该在kettle.properties文件中设置。
2. 用于启动Kettle程序的shell脚本
在下面一些情况下,可能要调整一下启动Kettle程序的shell脚本:
给Java classpath增加新的jar包。通常是因为在转换和作业里直接或间接引用了非默认的Java Class文件。
改变Java虚拟机的参数,如可用内存大小。
修改图形工具包环境。
(1)shell脚本的结构
所有Kettle程序用的shell脚本都类似:
初始化一个classpath的字符串,字符串里包括几个Kettle最核心的jar文件。
将libext目录下的jar包都包含在classpath字符串中。
将和程序相关的其它一些jar包都包含在classpath字符串中。例如Spoon启动时,要包含swt.jar文件,用于生成Spoon图形界面。
构造Java虚拟机选项字符串,前面构造的classpath字符串也包含在这个字符串里。虚拟机选项设置了最大内存大小。
利用上面构造好的虚拟机选项字符串,构造最终可以运行的Java可执行程序的字符串,包括Java可执行程序、虚拟机选项、要启动的Java类名。
上面描述的脚本结构是Kettle 3.2和以前版本的脚本文件结构,Kettle 4.0和以后版本都统一使用Pentaho的Launcher作为启动程序。
(2)classpath里增加一个jar包
在Kettle的转换里可以写Java脚本,Java脚本可能会引用第三方jar包。例如可以在“Java Script”步骤里实例化一个对象,并调用对象的方法,或者在“User defined Java expression”步骤里直接写Java表达式。当编写Java脚本或表达式时,需要注意classpath中有Java脚本里使用的各种Java类。最简单的方法就是在libext目录下新建一个目录,然后把需要的jar包都放入该目录下。因为在.sh脚本里可以加载libext目录下的所有jar文件(包括子目录),见下面的.sh文件里的代码
# ***************************************************# ** JDBC & other libraries used by Kettle: **# ***************************************************for f in `find $BASEDIR/libext -type f -name "*.jar"` \`find $BASEDIR/libext -type f -name "*.zip"`doCLASSPATH=$CLASSPATH:$fdone
这个sh脚本遍历libext目录下(包括各级子目录)的所有jar和zip文件,并添加到classpath中。在Kettle 4.2及以后的版本中,使用Launcher作为启动类,使用Kettle根目录下launcher子目录下的launcher.properties文件配置需要加载的类。用户增加了新的jar包,只要修改launcher.properties文件,不用再修改.sh脚本文件。
(3)改变虚拟机堆大小
所有Kettle启动脚本都指定了最大堆大小。如在spoon.sh中,有类似下面的语句:
# ******************************************************************# ** Set java runtime options **# ** Change 2048m to higher values in case you run out of memory **# ** or set the PENTAHO_DI_JAVA_OPTIONS environment variable **# ******************************************************************if [ -z "$PENTAHO_DI_JAVA_OPTIONS" ]; thenPENTAHO_DI_JAVA_OPTIONS="-Xms1024m -Xmx2048m -XX:MaxPermSize=256m"fi
当运行转换或作业时,如果遇到Out of Memory的错误,或者运行Java的机器有更多的物理内存可用,可以在这里增加堆的大小。只需把2048改成更大的数字,不要修改其它任何地方。
(4)修改图形工具包环境
例如,spoon.sh文件中有一个环境变量配置为export SWT_GTK3=0。使用该默认配置在创建资源库时会报类似下面的错误:
No more handles because no underlying browser available.SWT on GTK 2.x detected. It is reccomended to use SWT on GTK 3.x and Webkit2 API.org.eclipse.swt.SWTError: No more handles because no underlying browser available.SWT on GTK 2.x detected. It is reccomended to use SWT on GTK 3.x and Webkit2 API.
将配置改为export SWT_GTK3=1即可解决这个问题。
3. 管理JDBC驱动
随Kettle带了很多种数据库的JDBC驱动。一般一个驱动就是一个jar文件。Kettle把所有JDBC驱动都保存在lib目录下。
要增加新的JDBC驱动,只要把相应的jar文件放到lib目录下即可。Kettle的各种启动脚本会自动加载lib下的所有jar文件到classpath。添加新数据库的JDBC驱动jar包,不会对正在运行的Kettle程序起作用。需要将Kettle程序停止,添加JDBC jar包后再启动才生效。
当升级或替换驱动时,要确保删除了旧的jar文件。如果想暂时保留旧的jar文件,可以把jar文件放在Kettle之外的目录中,以避免旧的jar包也被意外加载。
三、小结本篇讲述了如何在Linux系统上安装配置Kettle,包括以下要点:
选择操作系统需要考虑的问题。
安装Java(Kettle运行环境)。
安装GNOME桌面。
配置VNC Server和VNC Client以远程连接GNOME桌面。
安装配置中文字符集和输入法。
使用脚本启动Kettle程序。
在GNOME桌面配置Spoon快捷启动方式。
Kettle的主要配置文件。
下一篇引入本专题涉及的另一个关键技术,Hadoop及其生态圈,实际演示Kettle对Hadoop的支持。


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。编辑|冷眼丶微信公众号|import_bigdata文章不错?点个【在看】吧! ?