
Diffusion Models 10 篇必读论文(2)DDIM
【导语】Diffusion Models 是近期人工智能领域最火的方向,也衍生了很多实用的技术。最近开始整理了几篇相关的经典论文,加上一些自己的理解和公式推导,分享出来和大家一起学习,欢迎讨论:702864842(QQ),https://github.com/Huangdebo。这是本系列第 2 篇:《DENOISING DIFFUSION IMPLICIT MODELS》
【导语】Diffusion Models 是近期人工智能领域最火的方向,也衍生了很多实用的技术。最近开始整理了几篇相关的经典论文,加上一些自己的理解和公式推导,分享出来和大家一起学习,欢迎讨论:702864842(QQ),https://github.com/Huangdebo。这是本系列第 2 篇:《DENOISING DIFFUSION IMPLICIT MODELS》
1、摘要
2、背景
3、非马尔科夫变分推理过程
3.1 非马尔科夫过程
3.2 产生过程(采样过程)
4、生成过程
4.1 隐性模型的去噪扩散
4.2 加速生成过程
4.3 与 DDPM 对比
5、总结
1、摘要
DDMP 中把正向扩散和逆扩散以及生成(采样)过程都看成是一个马尔科夫链,每一步扩散都与上一步产生的数据有关。因为是在近似拟扩散过程,所以每一步的扩散率必须要取值很小,故扩散步数取值必须要大(比如T=1000),而导致模型执行耗时过大。DDIM则通过观察优化目标中的特性,在满足和DDPM 同样的边缘分布下,提出了非马尔科夫过程来进行生成(采样),从而大幅度加速了模型,并且还具有生成一致性。
2、背景
对于一个数据的分布 q(x0),我们希望容易地学到一个能近似 q(x0) 的模型 p(x0)。在DDPM中,把这个模型(采样生成过程)设计成一个一个马尔科夫链: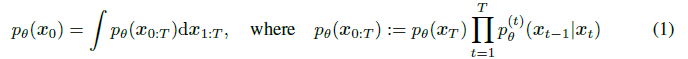 模型的优化目标是对数似然函数:
模型的优化目标是对数似然函数: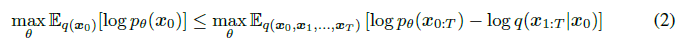 在模型的学习中,DDPM 的正向扩散过程也就是高斯核的马尔科夫过程,学习的过程其实就是在拟合拟扩散过程:
在模型的学习中,DDPM 的正向扩散过程也就是高斯核的马尔科夫过程,学习的过程其实就是在拟合拟扩散过程: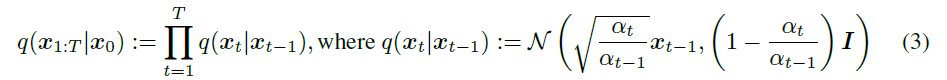 可以推导出:
可以推导出: 经过简化之后,优化目标转化成:
经过简化之后,优化目标转化成: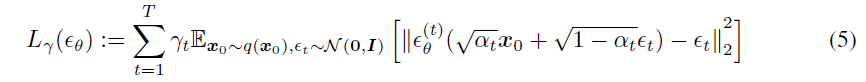
3、非马尔科夫变分推理过程
虽然 DDPM 的马尔科夫生成过程可以得到高质量的图像,但因为 DDPM 把生成过程也看成是一个马尔科夫链,所以需要重新几百上千个步骤才能生成一张图像,耗时很大。作者观察到学习目标 L 只与边缘分布 q(xt|x0) 有关,而不是直接和联合分布 q(x1:T|x0)有关,想到也许有很多形式的联合分布能够满足 q(xt|x0) ,这样的话,推理过程就不一定需要时马尔科夫链了:
3.1 非马尔科夫过程
作者假设符合上述的边缘分布的过程是很多种可能的联合分布,也就是使用不同的 σ :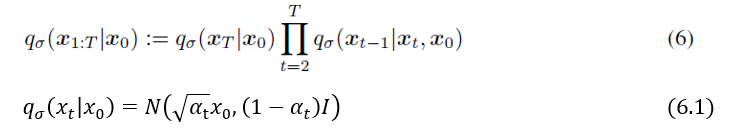 最关键的地方是作者把逆扩散的过程设计为:
最关键的地方是作者把逆扩散的过程设计为: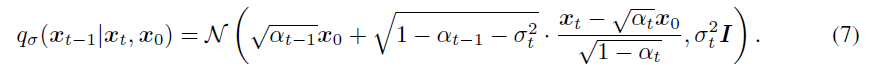 这个逆过程和 DDPM 中的不一样,但一样满足 (6)和(6.1),这个很重要,说明(7)假设对应的正常扩散过程中每个xt 都和 DDPM 中的一样,所以前传过程一致,这样便满足所有的模型假设,也可以使用 DDPM 与训练好的模型。 根据贝叶斯公式,前传过程(因为每一步的结果都不仅仅是依赖前一步的结果,所以不能再看成是之前所定义的扩散过程)可以得出:
这个逆过程和 DDPM 中的不一样,但一样满足 (6)和(6.1),这个很重要,说明(7)假设对应的正常扩散过程中每个xt 都和 DDPM 中的一样,所以前传过程一致,这样便满足所有的模型假设,也可以使用 DDPM 与训练好的模型。 根据贝叶斯公式,前传过程(因为每一步的结果都不仅仅是依赖前一步的结果,所以不能再看成是之前所定义的扩散过程)可以得出: 一般情况下,逆扩散和正扩散的每一步都是带有随机性的(因为会添加一点随机噪声来控制方差,式子(7)),所以σ 可以看成是逆扩散过程的随机性,当 σ->0 时,则在只观察 xt 和 x0的时候,xt-1便是确定的了(在DDPM 中,每一步的 σ 的值是固定的,DDIM 则先假设是一系列可能的值)。
一般情况下,逆扩散和正扩散的每一步都是带有随机性的(因为会添加一点随机噪声来控制方差,式子(7)),所以σ 可以看成是逆扩散过程的随机性,当 σ->0 时,则在只观察 xt 和 x0的时候,xt-1便是确定的了(在DDPM 中,每一步的 σ 的值是固定的,DDIM 则先假设是一系列可能的值)。
3.2 产生过程(采样过程)
模型训练目的就是为了得到一个能拟合你过程的一个生成过程 p(x0:T)。首先,可以利用式子(4)可以换算出一个伪 x0 ,使用预测的噪声和xt 来直接计算的准x0,并不是最终的x0,这里使用 fθ(xt) 来表示,然后也可以直接定了生成过程: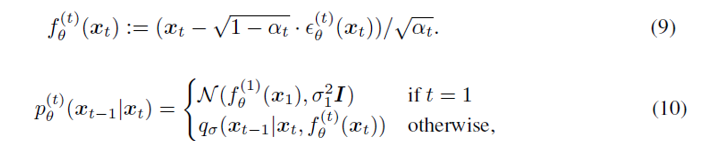 DDIM的优化目标为:
DDIM的优化目标为: 根据式子(5)中Lγ的表达式和 Jσ的定义,可推导出(文章附页):
根据式子(5)中Lγ的表达式和 Jσ的定义,可推导出(文章附页): 从Jσ 的表达式中可以看出,如果直接进行优化,需要计算所有 σ 可能取值的情况,这就导致不可计算或者计算量巨大。观察Lγ,发现如果模型权重在训练时不是在所有步骤中共享的,则每次都是对单个步骤(each term)进行最大化,这样优化求解就不依赖权重 γ了。 那么 DDIM 自然也可以参考 DDPM 中的优化目标,也把 Lγ 简化成 L1,也就是式子 (5)中系数 γ=1。
从Jσ 的表达式中可以看出,如果直接进行优化,需要计算所有 σ 可能取值的情况,这就导致不可计算或者计算量巨大。观察Lγ,发现如果模型权重在训练时不是在所有步骤中共享的,则每次都是对单个步骤(each term)进行最大化,这样优化求解就不依赖权重 γ了。 那么 DDIM 自然也可以参考 DDPM 中的优化目标,也把 Lγ 简化成 L1,也就是式子 (5)中系数 γ=1。
4、生成过程
由于优化目标和 DDPM 一致,同样都满足边缘分布 q(xt|x0) ,所以 DDIM 可以直接使用 DDPM 训练好的模型,而更多地去关注生成过程。希望通过选择合适的 σ,而找出更加高效的非马尔科夫生成过程。
4.1 隐性模型的去噪扩散
根据式子(10)和(7),可以得到: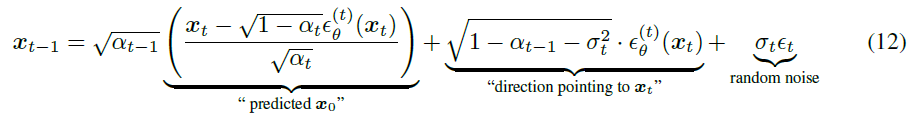 当 σt 满足某个情况时便就是 DDPM的马尔科夫逆扩散过程。如果让 σt=0,生成过程便成了一个确定的过程(这也是 DDIM 可以稳定输出的原因,给定一个xt,则每次都可以生成同样的 x0)。
当 σt 满足某个情况时便就是 DDPM的马尔科夫逆扩散过程。如果让 σt=0,生成过程便成了一个确定的过程(这也是 DDIM 可以稳定输出的原因,给定一个xt,则每次都可以生成同样的 x0)。
4.2 加速生成过程
在DDPM扩散模型中,生成过程就是在近似逆扩散的过程。因为扩散过程是T步逐步扩散的,所以一般生成过程也是T步。但仔细从 L1(式子35,γ=1) 的表达式来看,优化目标(式子35)中依赖了 xt,也就是只依赖了边缘分布 q(xt|x0),而不是整个逆扩散过程的联合分布 q(x1:T|x0),所以换个想法,那只要在满足边缘分布的情况下(式子 6.1),那么其实生成过程并不一定非要是T步的马尔科夫过程。于是可以使用一种跳跃式的生成过程来近似逆扩散。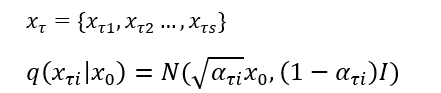 从[1,T] 中挑出一个子集,而且边缘分布也满足(式子 6.1),这样便可以大幅度加速了生成过程(式子(12)中 的 σ=0):
从[1,T] 中挑出一个子集,而且边缘分布也满足(式子 6.1),这样便可以大幅度加速了生成过程(式子(12)中 的 σ=0):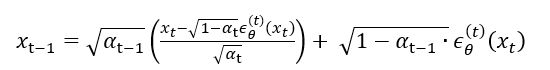
4.3 与 DDPM 对比
在DDPM 生成过程中,每一步都会添加一个随机噪声,这个噪声的方差是(参考 DDPM 中的 3.2): 在 DDIM 中,直接取消随机噪声,也就是 σ=0。但作者还是使用了一个超参数 η(eta)来调节 σ,与 DDPM 进行比对
在 DDIM 中,直接取消随机噪声,也就是 σ=0。但作者还是使用了一个超参数 η(eta)来调节 σ,与 DDPM 进行比对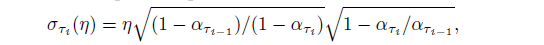
 η 表示 DDIM(不同取值);σ 表示 DDPM。表明在生成过程中,采用步数比较少的时候, DDIM 比 DDMP 更好,而且在 DDIM 中,η 取值越小越好
η 表示 DDIM(不同取值);σ 表示 DDPM。表明在生成过程中,采用步数比较少的时候, DDIM 比 DDMP 更好,而且在 DDIM 中,η 取值越小越好
5、总结
虽然DDPM 能生成高质量的图像,但因为其生成过程是在近似拟扩散了逆扩散过程,在满足同过程,所以每一步的扩散率必须要取值很小,故扩散步数取值必须要大(比如T=1000),而导致模型执行耗时过大。DDIM则使用非马尔科夫过程来进行生成(采样),从而大幅度加速了模型。并且 DDIM 具有生成一致性,在初始的噪声等信息相同时,生成的图像便在高层特征是也基本一致。