
IJCAI2022《对抗序列决策》教程

来源:专知 本文为教程,建议阅读5分钟
本教程将概述在序列决策设置中的对抗性学习的最新研究。

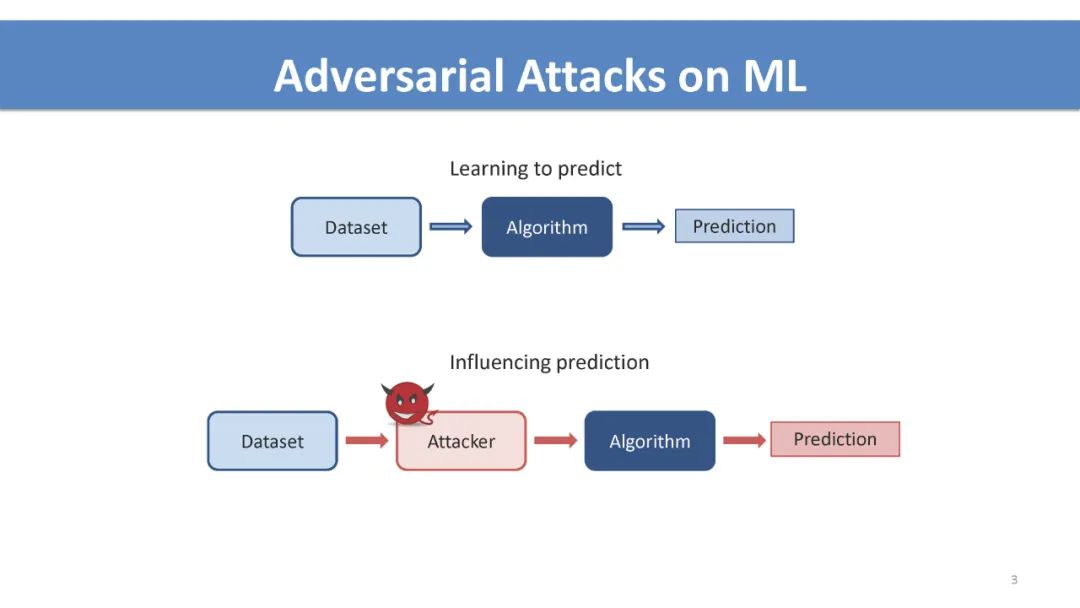
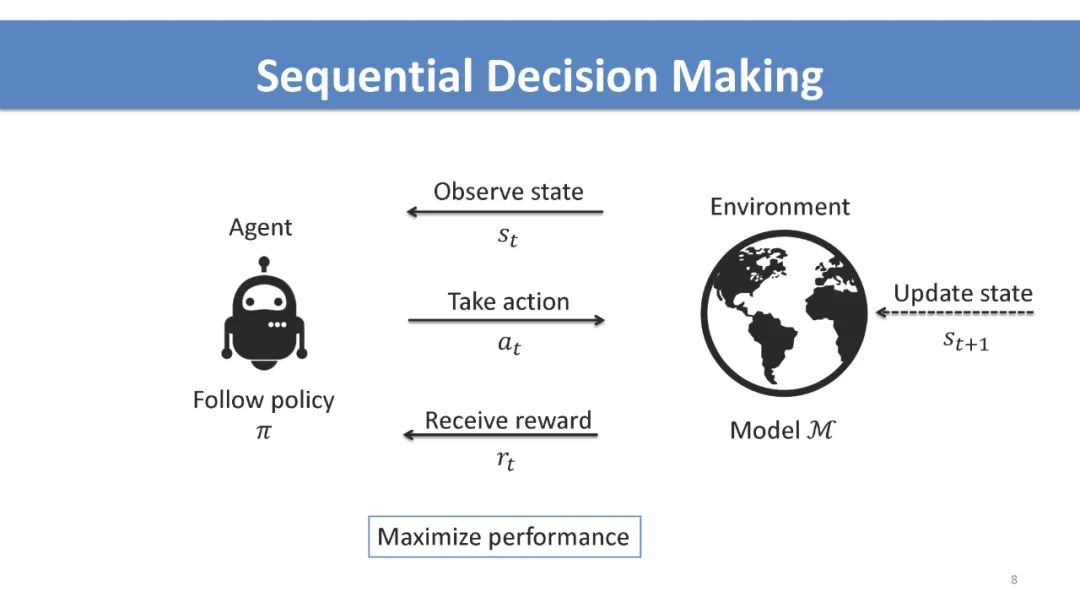
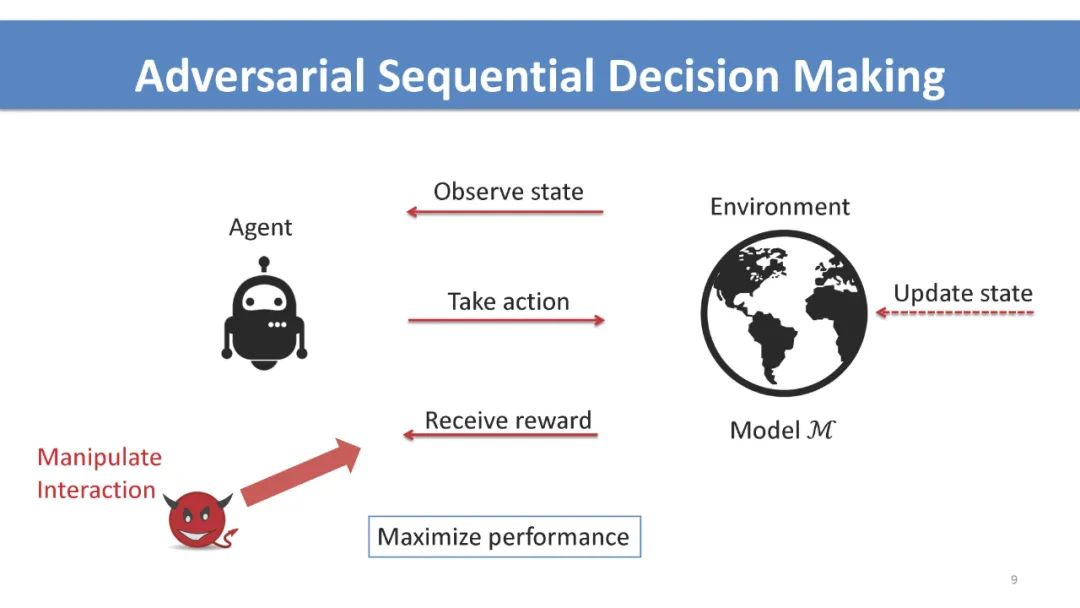
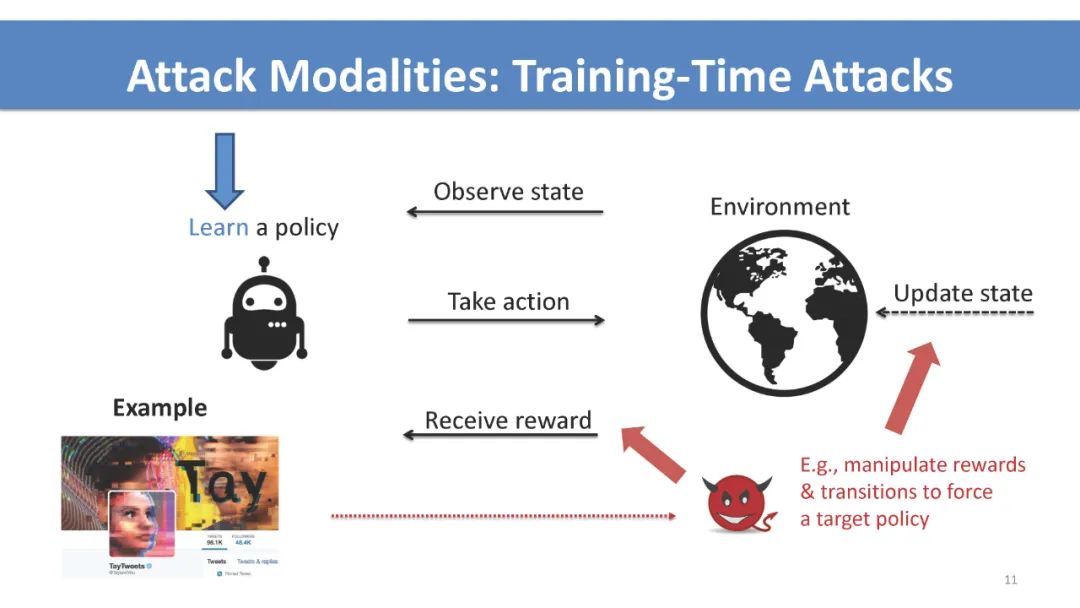
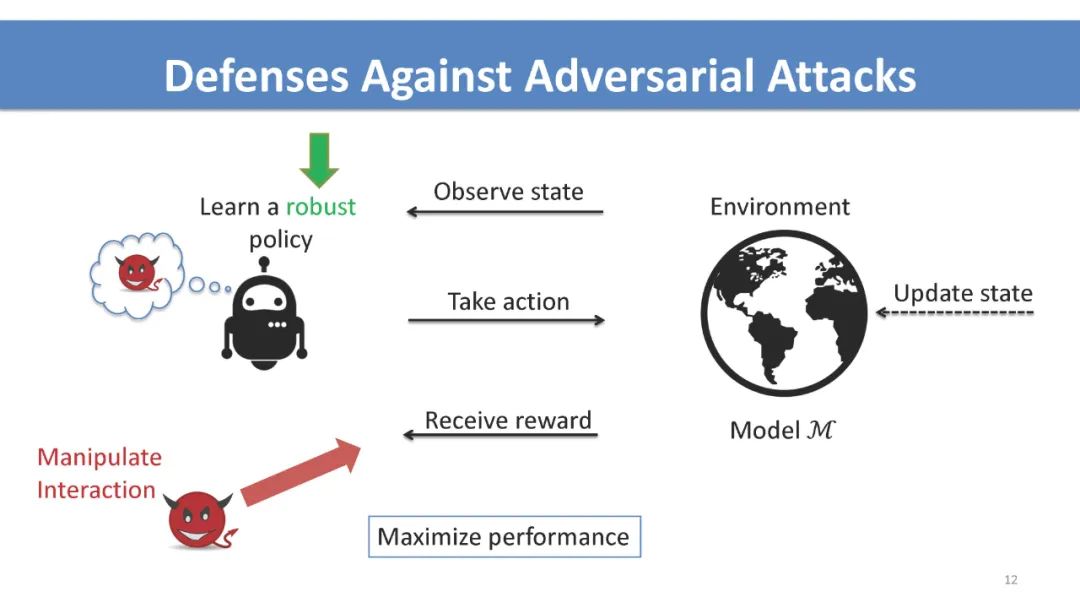
介绍 序列决策入门: 多臂赌博机,强化学习,多智能体交互,和博弈。 对抗性序列决策如何不同于对抗性监督学习的高级概述。 攻击策略和防御机制的高级概述。 多臂赌博机 不同反馈破坏模型和目标下的最优攻击策略。 最近在设计鲁棒算法、关键挑战和开放问题方面的工作。 强化学习 讨论不同的学习范式(例如,模仿学习、离线学习和在线学习),以及它们在对抗性攻击中是如何区别的。 测试时间、训练时间和后门攻击的最优攻击策略。 不同数据破坏模型和攻击目标下的最优攻击策略。 最近在设计鲁棒算法、关键挑战和开放问题方面的工作。 多智能体相互作用和博弈论考虑 多智能体系统中通过控制其他智能体的攻击和非健忘攻击。 利用博弈论工具防御攻击。 实际考虑和讨论 针对学习代理的安全威胁案例研究。 在对抗性序列决策中开发基准工具和数据集。 与观众公开讨论,促进跨社区合作。



评论