
Python爬虫打卡,来了!

大家周末好,今天来聊一聊网络爬虫。
爬虫是一个很热的概念,很多人学习python就是为了能get爬虫技能,能从网上抓取各式数据似乎是一件很酷的事。
我们熟知的微信机器人、抢票软件、小说下载器、新闻抓取、舆情分析等都是爬虫,或者说以爬虫为核心的集成应用。
爬虫是一个形象的叫法,网络爬虫其实是网络数据采集,针对性地用代码实现网络上各种数据(文字、图片、视频)的抓取。
通俗点说,爬虫就像是一个穿梭于网络世界的智能蜘蛛,你给它一个网址(url),然后设定规则,它就能突破重重险阻,把你想要的数据抓取下来,然后保存。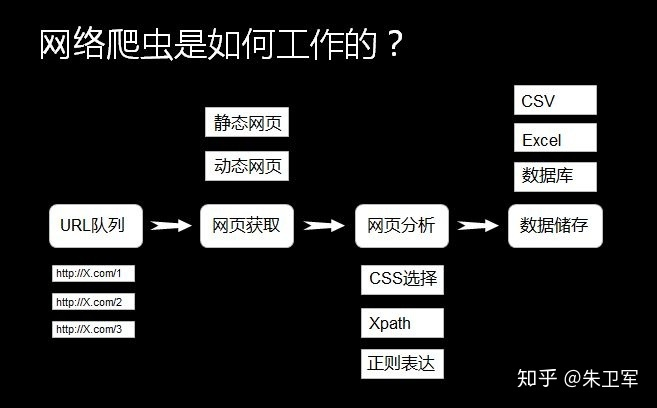
能实现爬虫的语言有很多,像Java、PHP、Python、C#...都可以用各种方式达到你的要求,那为什么要用python呢?
人生苦短,python当歌!
python是一门高级编程语言,语法简介,十分适合初学者。其次,Python拥有超级强大的开发社区,捣鼓出各种神奇的第三方库,比如requests、beautifulsoup、scrapy、xpath、selenium等,都是爬虫界的利器。
现在越来越多的人使用python来实现爬虫,网上的教程、案例层出不穷。
我们的星球也开启了python爬虫打卡系列,从认识爬虫到实战项目,从requests到xpath,通通安排打卡。
话不多说,给大家发一波星球优惠码(不多,50张),一起来爬虫吧!
之前,星球已经完成pandas、seaborn、matplotlib、正则表达式的打卡,积累了很多学习素材,进星球可直接获取。
那这次python爬虫打卡训练营有什么特色呢?
不需要你有任何爬虫基础,我们从零开始,循序渐进 每一小节配合教程、案例、作业,大家可在评论区打卡 每周安排2~3次打卡,留有充足的学习时间 重点突破requests和xpath这两个核心库 定期安排实战项目
目前打卡已经进行到第三天:

小伙伴们积极参与:

我一直觉得学习是自己的事情,打卡是监督学习最好的方式之一,且能积累大量的学习笔记。
爬虫,就从这里开始!
注:进入星球后,我会拉你进专门的python爬虫群,里面会提供技术问答服务。