
深度学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)

极市导读
本文仅对一些常见的优化方法进行直观介绍和简单的比较。>>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
SGD
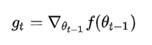
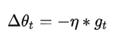
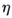 是学习率,
是学习率,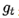 是梯度 SGD完全依赖于当前batch的梯度,所以 可理解为允许当前batch的梯度多大程度影响参数更新
是梯度 SGD完全依赖于当前batch的梯度,所以 可理解为允许当前batch的梯度多大程度影响参数更新 Momentum
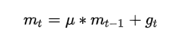
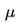 是动量因子
是动量因子下降初期时,使用上一次参数更新,下降方向一致,乘上较大的
能够进行很好的加速 下降中后期时,在局部最小值来回震荡的时候,
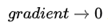 , 使得更新幅度增大,跳出陷阱
, 使得更新幅度增大,跳出陷阱 在梯度改变方向的时候,
能够减少更新 总而言之,momentum项能够在相关方向加速SGD,抑制振荡,从而加快收敛
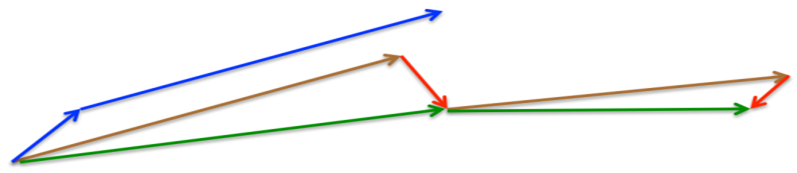
Nesterov
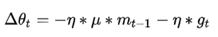
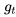 ,所以Nesterov的改进就是让之前的动量直接影响当前的动量。即:
,所以Nesterov的改进就是让之前的动量直接影响当前的动量。即: 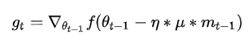
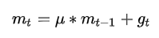
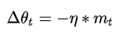
Adagrad
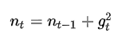
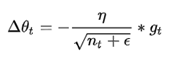 从1到
从1到 进行一个递推形成一个约束项regularizer,
进行一个递推形成一个约束项regularizer,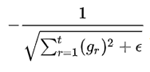 , e用来保证分母非0
, e用来保证分母非0 前期
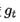 较小的时候, regularizer较大,能够放大梯度
较小的时候, regularizer较大,能够放大梯度 后期
较大的时候,regularizer较小,能够约束梯度 适合处理稀疏梯度
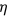 设置过大的话,会使regularizer过于敏感,对梯度的调节太大
设置过大的话,会使regularizer过于敏感,对梯度的调节太大 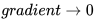 ,使得训练提前结束
,使得训练提前结束 Adadelta
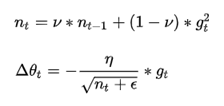
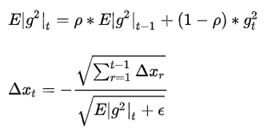
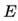 代表求期望。
代表求期望。 训练初中期,加速效果不错,很快
训练后期,反复在局部最小值附近抖动
RMSprop
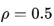 时,
时,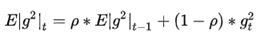 就变为了求梯度平方和的平均数。
就变为了求梯度平方和的平均数。 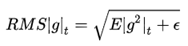 的一个约束:
的一个约束: 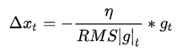
其实RMSprop依然依赖于全局学习率
RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
适合处理非平稳目标 - 对于RNN效果很好
Adam
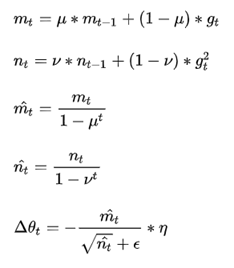
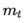 ,
,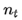 分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望
分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望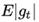 ,
,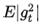 的估计;
的估计;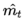 ,
,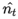 是对 , 的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,而 对学习率形成一个动态约束,而且有明确的范围。
是对 , 的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,而 对学习率形成一个动态约束,而且有明确的范围。结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
对内存需求较小
为不同的参数计算不同的自适应学习率
也适用于大多非凸优化 - 适用于大数据集和高维空间
Adamax
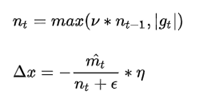
Nadam
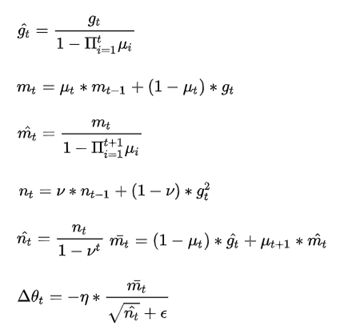
经验之谈
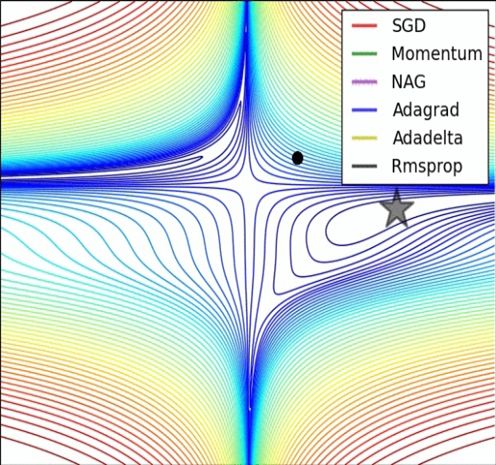
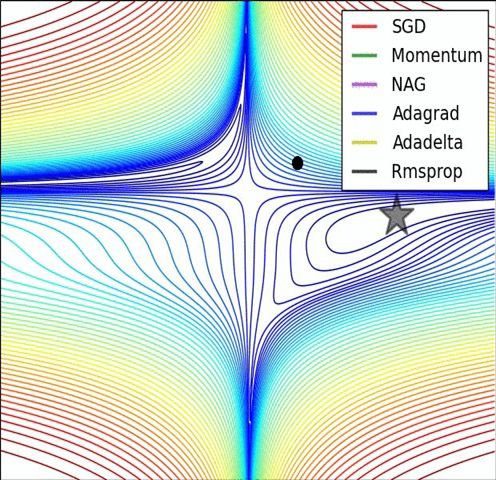
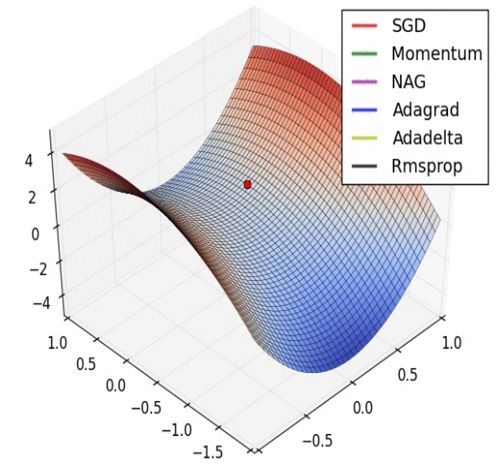
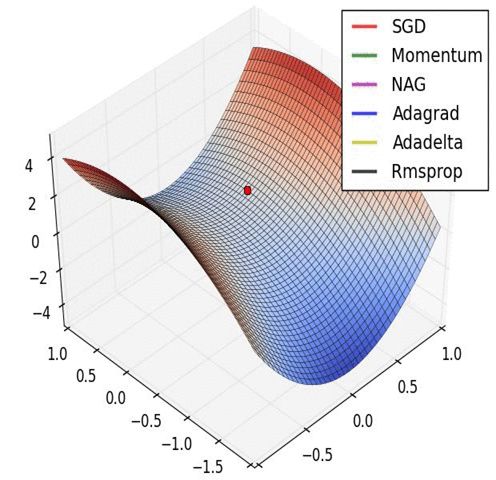
引用:
[1]Adagrad(http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf)
[2]RMSprop[Lecture 6e]
(http://www.cs.toronto.edu/~tijmen/csc321/lecture_notes.shtml)
[3]Adadelta(http://arxiv.org/abs/1212.5701)
[4]Adam(http://arxiv.org/abs/1412.6980v8)
[5]Nadam(http://cs229.stanford.edu/proj2015/054_report.pdf)
[6]On the importance of initialization and momentum in deep learning
(http://www.cs.toronto.edu/~fritz/absps/momentum.pdf)
[7]Keras中文文档(http://keras-cn.readthedocs.io/en/latest/)
[8]Alec Radford(https://twitter.com/alecrad)
[9]An overview of gradient descent optimization algorithms
(http://sebastianruder.com/optimizing-gradient-descent/)
[10]Gradient Descent Only Converges to Minimizers
(http://www.jmlr.org/proceedings/papers/v49/lee16.pdf)
[11]Deep Learning:Nature
(http://www.nature.com/nature/journal/v521/n7553/abs/nature14539.html)
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
