
2020 Crowdhuman人体检测比赛第一名经验总结

极市导读
本文作者分享了他在Crowdhuman人体检测比赛中前期调研的准备以及遇到的坑以及解决过程和经验教训,分享给大家作为参考。>>加入极市CV技术交流群,走在计算机视觉的最前沿
这篇总结其实在19年6月底就完成了,但当时由于种种原因,不方便将细节公开在知乎上。至于今天为什么又放出来,因为这篇文章里的内容其实在CVPR Workshop(https://www.objects365.org/workshop2019.html)上都已经提到,且我已经不在当时公司实习了,不会受到奇怪条条框框的约束。计算机视觉发展日新月异,现在回过头看这篇总结,有些地方难免感觉比较复古,相关的二阶段方法在工业界里也鲜有应用,依然选择放出这篇总结也是希望能对其他打比赛的同行们提供一些参考吧。当然2019年下半年通过一系列实验,我们对通用目标/密集行人检测有了新的认识,相关结果总结进了2篇论文,投到了某计算机视觉会议,希望能有好结果。正文:
前言
我和另一组员 @Magina507是在实习公司leader的指导下参加的这次比赛,以熟悉目标检测相关的技巧和经验。从前期调研算起,到提交完最后一次测试结果,前后历经2个月。最后的分数虽因提交策略上的失误未达到能达到optimal,但大家还算是比较满意。我们希望通过这篇文章,把这次参赛过程中踩过的坑以及学到的经验教训整理出来与大家讨论。
后续内容大致分为以下几个部分:
前期调研及准备 baseline复现 已知/未知的trick探索 后处理
前期调研及准备
虽然leader是检测方面的专家, @Magina507 此前并没有目标检测相关的经验,我仅仅跑过几个开源代码,所以调研部分我们选择求广,大量读paper和资料,过了些通用目标检测(object detection)和行人检测(pedestrian detection)近几年顶会上曝光率较高的文章,主要为第三阶段的做准备,对所有需要试的tricks,根据可靠性做个排序,来决定尝试顺序,细节会在第三部分详细阐述。
另外两个非常重要的调研方向:一是codebase,二是coco/openimage竞赛经验分享。codebase稍加搜索能定位到以下三个candidates:
Google的:
Tensorflow Detection API
https://github.com/tensorflow/models/tree/master/research/object_detection
FAIR的:
roytseng-tw/Detectron.pytorch
https://github.com/roytseng-tw/Detectron.pytorch
以及mmlab的:
open-mmlab/mmdetection
https://github.com/open-mmlab/mmdetection
不用tensorflow的原因想必不用多说,我们在detectron-pytorch和mmdetection选择了后者的原因,当然是mmdetection的author之一 @陈恺近期在知乎上比较活跃,可以每日私信催更 :p 好吧,其实仔细看detectron-pytorch的更新日志,上一次有效commit是1年以前了,而mmdetection不仅是去年coco冠军release的codebase,更保持了~3commits/week的速度, 陈博士在issue回答里的亲力亲为也让人对mmdetection印象大好。如果没有mmdetection,是不可能有我们最终的分数的
竞赛经验分享方面,我们重点参考了 @尼箍纳斯凯奇回答里关于coco竞赛经验分享部分的ppt:
如何评价商汤开源的 mm-detection 检测库?
https://www.zhihu.com/question/294578141/answer/493495238
陈博士cvpr19的:
Hybrid Task Cascade for Instance Segmentation
https://arxiv.org/abs/1901.07518
以及openimage前四名的tech reports:
Google AI Open Images - Object Detection Track
https://www.kaggle.com/c/google-ai-open-images-object-detection-track/discussion
结合以上资料,对可以尝试的tricks做到心中有数有序,调研部分便算是完成了。(数据集部分暂时先跳过。。。)
baseline复现
baseline是我们遇到的第一道坎,也是这次比赛的第一个大坑。放几张测试集图片及我们的预测结果,初步感受下crowdhuman[1]这个数据集:

取自crowdhuman test set

取自crowdhuman test set
看起来并不好解决。与其他比赛一样,第一步需要复现crowdhuman论文里的baseline以确保模型里各个模块及超参正常工作。
需要预先交代的是:Crowdhuman的标注分为3类,分别为visible, full和head。visible为身体可见部分的bbox,full则需要模型额外推测出被遮挡区域的位置。比赛早期由于主办方未公布测试结果是以哪种标注为准,我们选择在visible上先进行实验。(上面两张图里有不少bbox框到没有人体的部分是因为用了预测的full body框,full body也是比赛最后的测评依据,而不是visible)。此外行人检测使用的核心测评指标不是mAP,而是mMR(log average missing rate)。深究原理会发现mMR和coco style的mAP有非常大的区别,具体如下:
mAP-coco在乎的是IoU=0.5:0.95在全score分段上的表现。(越大越好) mMR在乎的是IoU>0.5,且只考虑高分段的表现。(越小越好,可理解为mMR越小,高分段pred_bboxes里miss的gt_bboxes越少)
可以看出,mAP-coco同时关注定位准不准、recall和precision高不高。而mMR对定位的精确度有所放松(IoU>0.5即可),转而关注高分段bbox的precision,如仅关注得分大于0.7的bbox的质量,这个得分阈值是由mMR根据实际结果自适应的。举个例子,一个与gt_bbox的IoU=0.9的pred_bbox, 分数仅为0.4,这样的bbox对mAP是有增益的,但是对mMR可能没有丝毫影响。这个分析结果也让我们能初步察觉到,soft-nms[2]对mMR应该是难有裨益了。
在visible上复现baseline花费了我们近半个月的时间。起初:
原文baseline的配置为:Faster RCNN[3], ResNet50[4], FPN[5], roi pooling(roi pooling还是align不确定) 我们baseline的配置为:Faster RCNN, ResNet50, FPN, roi align[6]
结果不论在mMR和AP@0.5上都差了2个点左右。在这一阶段的尝试中,我们发现了两个很依赖数据集的超参:
对FPN里用到的所有conv套上BN[7] RPN阶段的nms_pre这个参数
实验发现,FPN+BN可以提升1.x个点的AP@0.5,且mMR也有明显改善(具体数字不可考究了),然而加BN这个事情我们却在obj365[8]和coco上观察到了另两种现象,obj365-tiny上AP@0.5升,AP@0.75降,mAP降,coco上则直接全面下降,所以这是个很依赖数据集的setting。RPN阶段的nms_pre在mmdetection中默认为2000,我们发现,这个数字越大,Recall和AP@0.5都有明显提升,mMR却变差,这点可以解释为,rcnn见到sample的diversity会随着nms_pre这个数字变高而增加,所以recall会增加,而之前我们也分析过,AP在意的是全分段的结果,且AP的上限为recall,所以AP也会随着recall的增加而增加。mMR变差的解释为:随着diversity的引入,rcnn训练阶段被强行引入了些hard sample,这些hard sample影响了模型的判断,导致原高置信度bbox的得分出现不同程度的震荡,继而高分段pred_bbox的表现出现下滑。AP和mMR受到nms_pre影响的这个规律在nms_pre∈[1000,12000]之间都成立。所以在crowdhuman上存在这样一个取分技巧:通过调低nms_pre牺牲AP的方式来换取mMR的提升。
上面两点的发现颇有运气成分,随后与leader讨论发现了之前忽视的另一关键点:ignore区域。Crowdhuman将雕塑、影子,镜子里的人等视为ignore区域,此外有一类ignore区域是很难精准预测的密集人群,如下图橙黄色区域(手动标的)。是否预测出来ignore区域的bbox不影响测评分数,绿框是模型的预测结果。训练阶段我们起初直接无视了ignore区域,这导致下图橙黄色ignore区域有在RPN阶段成为训练背景的可能,但细想一下,下图这片ignore区域是一定程度上具备human body特征的,只是分辨率较低,让它作为RPN的阶段的背景显然会影响RPN对每个anchor属于前背景的判断。

取自crowdhuman test set
发现这一点后,我们在anchor的正负例策略中增加了一条:
3. 与ignore bbox的IoA(Intersection over Anchor)大于0.5的anchor不可作为负例(及背景)。
反应在mmdetection的代码中,即:将满足上述条件的anchor在RPN阶段的label设置为-1。综合以上3点改进,我们在visible的baseline上mMR和AP@0.5终于均略微超过原文。
baseline的复现并没有到此为止。主办方在5月10日左右,比赛过了一半还多的时候,宣布测评标准将以full body上的测试结果为准。这一宣布导致我们又呼哧哧去复现full的结果。使用mmdetection,在full上会有小问题,具体在预处理阶段需要对越界bbox的处理,对roi越界的处理需要调整。此时距离比赛结束仅剩1个月的时间,我们只能将visible上的超参原封不动搬到full上,然后祈祷对visible和full的超参有一致的规律。所以我们baseline复现截止的真正时间其实是到5月中,然后发现mMR在full上比原文居然好了4个点。。
tricks探索
虽然full baseline复现较晚,但我们很早便开始在visible上进行各种trick复现和探索,技巧方面的储备还算是充分。下面分几类讲下我们尝试过的技巧:
众所周知的稳定涨点技巧
此类技巧包括: Cascade RCNN[9], Deformable Convolution[10], better backbone, Multi-scale training/testing, Ensemble
这类技巧已经受过无数炼丹师的检验。由于mmdetection的存在,试这些技巧大部分都是改改配置的事情。稍微要提的是backbone方面,我们试尝试了以下几种: ResNet50, ResNeXt101-64x4d[11], SEResNeXt101-32x4d, SENet154[12], HRNetv2p_w40[13]。其中ResNeXt101-64x4d, SEResNeXt101-32x4d和HRNetv2p_w40几乎相当,SENet154与其他论文及经验分享中结论一致,效果拔群,在JI、mMR和AP@0.5上超出前三者1~3个点。
嗯?JI是什么?
主办方也是在5月初,才姗姗来迟地公布了他们的测评标准实为Jaccard Index[14],而非mMR和mAP,细节如下图。我们又是对之前训好的模型一顿调试,具体就不展开说了,一言以蔽之,JI同样是个只在乎高分段pred_bbox性能的指标(与mMR相反,越高越好),只是这个高分段阈值不是自适应,而是需要手动调整的(这也有了开头所说的提交策略影响了最终结果的事情,我们最终卡分的位置并不理想)。JI经过精心的挑选阈值,面对各种trick和超参的规律与mMR几乎相当。

取自竞赛官网
Multi-scale和Ensemble也有些操作空间,细节将放到第四部分详细说明。
2. 该work却不work的技巧--“真的不行”篇
这类技巧主要包括:SyncBN[15],focal loss[16], reflective loss[17], GIoU/IoU Loss[18],pretrain on COCO, IoUNet[19], scale balanced sampling[20], Soft-NMS。需要指明的是,这类技巧在CrowdHuman数据集上没有增益,不代表他们在其他数据集上也没有帮助(DL嘛,你懂的),所以大家不能轻易忽略这类技巧的价值。
SyncBN
baseline里使用的是标准BN,但滑动统计值是取自ImageNet的预训练模型,且训练crowdhuman期间不对滑动统计值进行更新。SyncBN已被证实在coco上有稳定的提升,我们在crowdhuman上却得不到理想的效果。推测原因可能是crowdhuman训练数据只有15000张,数据量远远小于coco的20w+,不足以提供科学的滑动统计值。放弃
Focal Loss
我们观察到了如下现象:pred bbox尺寸越小,分类得分越均匀分散在0~1之间,pred bbox尺寸越大, 分数越靠近0、1两端。小目标分类结果的不确定性为后续尝试JI的卡分阈值带来一定困扰,那有没有办法让模型把小目标得分从中间往两侧推呢?在R-CNN Module的损失函数上应用focal loss从原理上来说当然有可能做到这一点,训练阶段focal loss会将小目标中得分趋向于0.5的目标视为难样本,为其提供较大的梯度权重。然而,rcnn阶段使用了focal loss的模型mMR比baseline掉了2个点。具体原因我们没有详细分析了,可能是对难样本的强行学习反过来伤害到easy sample的表现吧。
GIoU/IoU
Sadly...用不用几乎没有区别。
Pretrain on COCO
在COCO上预训练按理说至少不该伤害模型表现。在以Res50为backbone的时候,JI和mMR确有0.5~1个点的提升,换到了SENet154后,在coco上预训练反而轻微伤害到了模型, sigh...
Soft-NMS
Soft-NMS在第二部分提到,它只能捞回被打入低分段的bbox,对只在乎相对高分段bbox的mMR和JI理应不产生影响,实际实验结果也证实了这点。用不用,到小数点后第四位都看不出来变化,所以某cvpr oral的论文里用了soft-nms影响了mMR的结果真是一眼难尽。。。
3. 该work却不work的技巧--“没尽力调”篇
这类技巧主要包括:Guided Anchor[21], OHEM[22], Adaptive NMS[23]
Guided Anchor
Guided Anchor是一片很独特的文章,比赛期间我们未对该方法和实现做深入研究,仅使用了默认的setting,在mMR上差了baseline 0.5个点。如果原意沉下心来,做更多超参上的调整,相信在baseline上是会有不小提升空间的。
OHEM
OHEM也是考验炼丹师火候的技巧。由于focal loss的失败经历,OHEM几乎没怎么试就放弃了。
Adaptive NMS
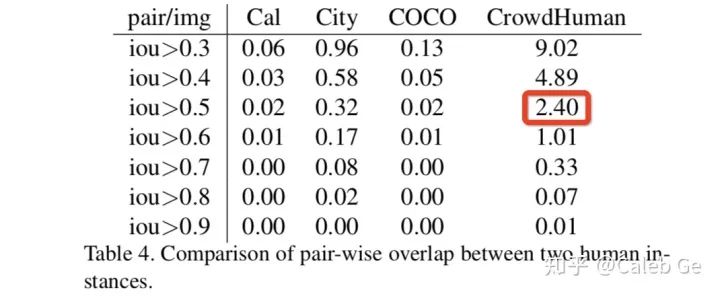
我们对Adaptive NMS抱有很大的期待,因为它的原理真的很make sense。。。标准的post nms会使用0.5作为阈值对pred bbox进行过滤,仔细看下表,红框里的数字表示在crowdhuman这个数据集里,平均每张图片有2.4对bbox之间的IoU>0.5。这意味着使用标准post nms和0.5阈值,每张图从一开始就不可避免的要损失2.4个gt bbox,这对JI有2个点以上的影响。Adaptive NMS提供了一种很巧妙的思路,即根据pred bbox的密度,来动态决定每个pred bbox做nms时候的阈值,这个密度叫density map,测试阶段由模型预测给出。可惜,我们一直未训练出理想的density map,原因至今还未探明。
截自Crowdhuman
4. 勉强work的技巧
这类技巧主要包括:merge cityperson[24], repulsion loss[25], rcnn context
Merge Cityperson
调研发现,在所有public available dataset中,cityperson显得与crowdhuman最为接近且有full body标注框。融合了cityperson的数据集在baseline上约有0.8个点mMR的提升,到了JI上却只有可怜的0.2。
Repulsion Loss
Repulsion loss是专门针对拥挤场景下的行人检测设计的算法,它通过施加loss,迫使所有pred bbox相互之间IoU越接近0越好,此外每个pred bbox与其不对应的gt bbox之间的IoU越接近0越好。加了Repulsion Loss反而轻微伤害了mMR。仔细分析,我们发现Rep Loss这种将IoU推至0的方式有些矫枉过正,如果我们对每个pred bbox和其不对应的gt bbox之间施加一个推的下界,该下界为:该pred bbox的对应gt bbox与该pred bbox的不对应gt bbox之间的IoU。推到此便不再提供任何梯度。这种Bounded Rep Loss可以改进mMR 0.6个点,JI也有0.4x的提升,算勉强有效果吧。
RCNN Context
baseline里每个roi经过roi align,随后被传入rcnn里做分类和回归。Context的意思是额外将原始roi长宽两倍大小的double_size rois经过roi align后concat到之前的roi feature上,一并送入rcnn做分类,为rcnn提供更宽阔的视野以求更精准的定位和回归。RCNN Context可以改进mMR 0.6个点。它与Rep Loss均是rcnn阶段的调整,合到一起可以一共提供0.8个点的mMR改进。
后处理
这部分有两个值得提的地方。一是multi scale testing时候testing scale的选取。在coco上,可以用小至(900, 600)的最长最短边,大至(2100, 1400)的最长最短边,这种大scale跨度对coco的multi scale testing大有裨益。但是我们发现在crowdhuman上,任何低于(1400, 800)的最长最短边加入到testing scales中,都会伤害到ms test的效果。原因很可能是crowdhuman里小目标的“看不清”问题比大目标的“看不全”问题严重得多。最终我们使用的3个testing scale为:[(1600, 1200), (1800, 1300), (2100, 1400)]。ms test在mMR和JI上均有2个点左右的提升。
另一点是ensemble。在ensemble上我们尝试了很多脑洞大开的想法,包括:
百度openimage冠军方案里,为每个模型加权改分,再在nms阶段将分数加回来 直接将所有模型结果拉到一起使用0.5为阈值进行nms 将每个模型的roi都交给其他模型的rcnn算分,最终将所有分平均作为该模型的roi得分。(相当于多一步rcnn ensemble) ...
结果显示这些方法均会对AP带来大量增益(2个点以上),但mMR上他们没有一个work。与leader时他指出在crowdhuman这类拥挤数据集上,nms阈值应相应拉高来保留更多不同模型的意见。顺着这个思路,我们发现最有效的ensemble方法依旧是直接对所有模型结果进行nms,只是需要把阈值从0.5改为0.6。改阈值后的ensemble能带来近1个点JI的提升。最终我们用来ensemble的5个模型为:
Cascade + DCN + SENet154 Cascade + DCN + SENet154 + RepContext Cascade + DCN + SENet154 + RepContext + Cityperson Cascade + DCN + SENet154 + RepContext + coco pretrain Cascade + DCN + SEResNeXt101 + RepContext
一点小遗憾:我们在早期尝试过提交SENet154的test结果,发现了test与val set难度严重不匹配的问题。随后的实验中,我们根据dt bboxes num从val set里筛选出了一个与test set分布看起来一致的val subset,后续调试JI的阈值也都是在val subset上试的。再之后的3次test提交我们才发现,val subset的阈值与test set的阈值依然存在严重不一致的状况。一共只有5次test提交机会,早先浪费的1次和用掉发现规律的3次之后,只剩最后一次了。最后一次我们选择了求稳,获得了0.4的涨点,但同时也意识到,如果有足够的提交次数,现有模型依旧有0.6个点左右的提升空间,算是个不大不小的遗憾。
一些小吐槽
上文trick探讨中,有时会以JI为指标,有时会以mMR为指标,看起来会有些混乱。其实不是故意这么换来换去。5月30日之前,官方提交的JI指标都有bug(竞赛截止日期是北京时间6月13日),我们没法根据JI来衡量模型的好坏,而当bug free的JI代码release之后,便没有针对JI进行进一步调参了,都用了最优于mMR的超参,实际这是不太合适的。另外crowdhuman还会带来一些工程上的问题,比如gt bbox与anchor的overlap矩阵过大,导致SENet154训练的时候会爆内存等等,尝试解决这些问题为这个比赛添加了些额外的乐趣。。。
总结写完,比赛就彻底翻篇儿了
我们团队被收录的论文:
PS-RCNN: Detecting Secondary Human Instances in a Crowd via Primary Object Suppression
https://arxiv.org/abs/2003.07080
NMS by Representative Region: Towards Crowded Pedestrian Detection by Proposal Pairing
https://arxiv.org/abs/2003.12729
以及最近筹建的一个目标检测答疑微信群,二维码失效的话请加微信: xraft2226:
------
2020-03-31:
插播广告:我们后续在CrowdHuman上又做了些尝试,相关结果已被收入至2020年的CVPR和ICME,两篇论文的链接在文末。
比赛经验的视频分享:
【智源-旷视科技】2019冠军团队经验分享 | 2020 CrowdHuman 人体检测大赛经验分享:
https://www.bilibili.com/video/BV1g5411W7Bo?from=search&seid=17939842903110119715
参考:
推荐阅读
