
实操教程|我的PyTorch模型比内存还大,怎么训练呀?
↑ 点击蓝字 关注极市平台

作者丨McGL
来源丨PyVision
编辑丨极市平台
极市导读
本文介绍了一种技术:梯度检查点。通过从计算图中省略一些激活值,减少了计算图使用的内存,降低了总体内存压力。 >>公众号后台回复“79”或者“陈鑫”获得CVPR 2021:TransT 直播链接
随着深度学习的飞速发展,模型越来越臃肿,哦不,先进,运行SOTA模型的主要困难之一就是怎么把它塞到 GPU 上,毕竟,你无法训练一个设备装不下的模型。改善这个问题的技术有很多种,例如,分布式训练和混合精度训练。
本文将介绍另一种技术: 梯度检查点(gradient checkpointing)。简单的说,梯度检查点的工作原理是在反向时重新计算深层神经网络的中间值(而通常情况是在前向时存储的)。这个策略是用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)。
文末有一个示例基准测试,它显示了梯度检查点减少了模型 60% 的内存开销(以增加 25% 的训练时间为代价)。
详细代码请查看我的 GitHub 库: https://github.com/spellml/tweet-sentiment-extraction/blob/master/notebooks/5-checkpointing.ipynb
>>> 神经网络如何使用内存
为了理解梯度检查点是如何起作用的,我们首先需要了解一下模型内存分配是如何工作的。
神经网络使用的总内存基本上是两个部分的和。
第一部分是模型使用的静态内存。尽管 PyTorch 模型中内置了一些固定开销,但总的来说几乎完全由模型权重决定。当今生产中使用的现代深度学习模型的总参数在100万到10亿之间。作为参考,一个带 16GB GPU 内存的 NVIDIA T4 的实际限制大约在1-1.5亿个参数之间。
第二部分是模型的计算图所占用的动态内存。在训练模式下,每次通过神经网络的前向传播都为网络中的每个神经元计算一个激活值,这个值随后被存储在所谓的计算图中。必须为批中的每个单个训练样本存储一个值,因此数量会迅速的累积起来。总开销由模型大小和批次大小决定,一般设置最大批次大小限制来适配你的 GPU 内存。
要了解更多关于 PyTorch autograd 的信息,请查看我的 Kaggle 笔记本《PyTorch autograd 解释》: https://www.kaggle.com/residentmario/pytorch-autograd-explained
>>> 梯度检查点是如何起作用的
大型模型在静态和动态方面都很耗资源。首先,它们很难适配 GPU,而且哪怕你把它们放到了设备上,也很难训练,因为批次大小被迫限制的太小而无法收敛。
现有的各种技术可以改善这些问题中的一个或两个。梯度检查点就是这样一种技术; 分布式训练,是另一种技术。
梯度检查点(gradient checkpointing) 的工作原理是从计算图中省略一些激活值。这减少了计算图使用的内存,降低了总体内存压力(并允许在处理过程中使用更大的批次大小)。
但是,一开始存储激活的原因是,在反向传播期间计算梯度时需要用到激活。在计算图中忽略它们将迫使 PyTorch 在任何出现这些值的地方重新计算,从而降低了整体计算速度。
因此,梯度检查点是计算机科学中折衷的一个经典例子,即在内存和计算之间的权衡。
PyTorch 通过 torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 提供梯度检查点,根据官方文档的 notes,它实现了如下功能,在前向传播时,PyTorch 将保存模型中的每个函数的输入元组。在反向传播过程中,对于每个函数,输入元组和函数的组合以实时的方式重新计算,插入到每个需要它的函数的梯度公式中,然后丢弃。网络计算开销大致相当于每个样本通过模型前向传播开销的两倍。
梯度检查点首次发表在2016年的论文 《Training Deep Nets With Sublinear Memory Cost》 中。论文声称提出的梯度检查点算法将模型的动态内存开销从 O(n)(n 为模型中的层数)降低到 O(sqrt(n)),并通过实验展示了将 ImageNet 的一个变种从 48GB 压缩到了 7GB 内存占用。
>>> 测试 API
PyTorch API 中有两个不同的梯度检查点方法,都在 torch.utils.checkpoint 命名空间中。两者中比较简单的一个是 checkpoint_sequential,它被限制用于顺序模型(例如使用 torch.nn.Sequential wrapper 的模型)。另一个是更灵活的 checkpoint,可以用于任何模块。
下面是一个完整的代码示例,显示了 checkpoint_sequential 的实际用法:
import torchimport torch.nn as nnfrom torch.utils.checkpoint import checkpoint_sequential# a trivial modelmodel = nn.Sequential(nn.Linear(100, 50),nn.ReLU(),nn.Linear(50, 20),nn.ReLU(),nn.Linear(20, 5),nn.ReLU())# model inputinput_var = torch.randn(1, 100, requires_grad=True)# the number of segments to divide the model intosegments = 2# finally, apply checkpointing to the model# note the code that this replaces:# out = model(input_var)out = checkpoint_sequential(modules, segments, input_var)# backpropagateout.sum().backwards()
如你所见,checkpoint_sequential 替换了 module 对象上的 forward 或 __call__ 方法。out 几乎和我们调用 model(input_var) 时得到的张量一样; 关键的区别在于它缺少了累积值,并且附加了一些额外的元数据,指示 PyTorch 在 out.backward() 期间需要这些值时重新计算。
值得注意的是,checkpoint_sequential 接受整数值的片段数作为输入。checkpoint_sequential 将模型分割成 n 个纵向片段,并对除了最后一个的每个片段应用检查点。
这工作很容易,但有一些主要的限制。你无法控制片段的边界在哪里,也无法对整个模块应用检查点(而是其中的一部分)。
替代方法是使用更灵活的 checkpoint API. 下面展示了一个简单的卷积模型:
class CIFAR10Model(nn.Module):def __init__(self):super().__init__()self.cnn_block_1 = nn.Sequential(*[nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25)])self.cnn_block_2 = nn.Sequential(*[nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25)])self.flatten = lambda inp: torch.flatten(inp, 1)self.head = nn.Sequential(*[nn.Linear(64 * 8 * 8, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 10)])def forward(self, X):X = self.cnn_block_1(X)X = self.cnn_block_2(X)X = self.flatten(X)X = self.head(X)return X
这种模型有两个卷积块,一些 dropout,和一个线性头(10个输出对应 CIFAR10 的10类)。
下面是这个模型使用梯度检查点的更新版本:
class CIFAR10Model(nn.Module):def __init__(self):super().__init__()self.cnn_block_1 = nn.Sequential(*[nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2)])self.dropout_1 = nn.Dropout(0.25)self.cnn_block_2 = nn.Sequential(*[nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2)])self.dropout_2 = nn.Dropout(0.25)self.flatten = lambda inp: torch.flatten(inp, 1)self.linearize = nn.Sequential(*[nn.Linear(64 * 8 * 8, 512),nn.ReLU()])self.dropout_3 = nn.Dropout(0.5)self.out = nn.Linear(512, 10)def forward(self, X):X = self.cnn_block_1(X)X = self.dropout_1(X)X = checkpoint(self.cnn_block_2, X)X = self.dropout_2(X)X = self.flatten(X)X = self.linearize(X)X = self.dropout_3(X)X = self.out(X)return X
在 forward 中显示的 checkpoint 接受一个模块(或任何可调用的模块,如函数)及其参数作为输入。参数将在前向时被保存,然后用于在反向时重新计算其输出值。
为了使其能够工作,我们必须对模型定义进行一些额外的更改。
首先,你会注意到我们从卷积块里删除了 nn.Dropout 层; 这是因为检查点与 dropout 不兼容(回想一下,样本有效地通过模型两次 —— dropout 会在每次通过时任意丢失不同的值,从而产生不同的输出)。基本上,任何在重新运行时表现出非幂等(non-idempotent )行为的层都不应该应用检查点(nn.BatchNorm 是另一个例子)。解决方案是重构模块,这样问题层就不会被排除在检查点片段之外,这正是我们在这里所做的。
其次,你会注意到我们在模型中的第二卷积块上使用了检查点,但是第一个卷积块上没有使用检查点。这是因为检查点简单地通过检查输入张量的 requires_grad 行为来决定它的输入函数是否需要梯度下降(例如,它是否处于 requires_grad=True 或 requires_grad=False模式)。模型的输入张量几乎总是处于 requires_grad=False 模式,因为我们感兴趣的是计算相对于网络权重而不是输入样本本身的梯度。因此,模型中的第一个子模块应用检查点没多少意义: 它反而会冻结现有的权重,阻止它们进行任何训练。更多细节请参考这个 PyTorch 论坛帖子:https://discuss.pytorch.org/t/use-of-torch-utils-checkpoint-checkpoint-causes-simple-model-to-diverge/116271
在 PyTorch 文档(https://pytorch.org/docs/stable/checkpoint.html#)中还讨论了 RNG 状态以及与分离张量不兼容的一些其他细节。
完整的训练代码示例可以看这里:https://gist.github.com/ResidentMario/e3254172b4706191089bb63ecd610e21
和这里: https://gist.github.com/ResidentMario/9c3a90504d1a027aab926fd65ae08139
>>> 基准测试
作为一个快速的基准测试,我在 tweet-sentiment-extraction 上启用了模型检查点,这是一个基于 Twitter 数据的带有 BERT 主干的情感分类器模型。你可以在这里看到代码:https://github.com/spellml/tweet-sentiment-extraction。transformers 已经将模型检查点作为 API 的一个可选部分来实现; 为我们的模型启用它就像翻转一个布尔值标记一样简单:
# code from model_5.pycfg = transformers.PretrainedConfig.get_config_dict("bert-base-uncased")[0]cfg["output_hidden_states"] = Truecfg["gradient_checkpointing"] = True # NEW!cfg = transformers.BertConfig.from_dict(cfg)self.bert = transformers.BertModel.from_pretrained("bert-base-uncased", config=cfg)
我对这个模型进行了四次训练: 分别在 NVIDIA T4和 NVIDIA V100 GPU 上,包括检查点和无检查点模式。所有运行的批次大小为 64。以下是结果:
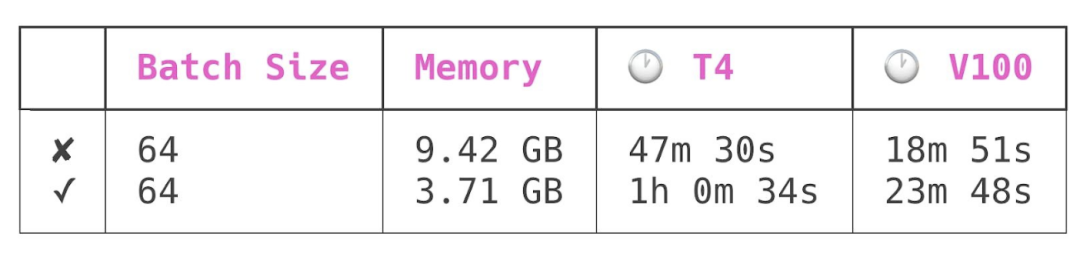
第一行是在模型检查点关闭的情况下进行的训练,第二行是在模型检查点开启的情况下进行的训练。
模型检查点降低了峰值模型内存使用量 60% ,同时增加了模型训练时间 25% 。
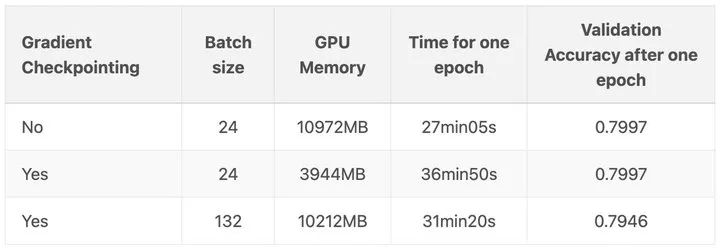
当然,你想要使用检查点的主要原因可能是,这样你就可以在 GPU 上使用更大的批次大小。在另一篇博文:https://qywu.github.io/2019/05/22/explore-gradient-checkpointing.html 中演示了这个很好的例子: 在他们的例子中,每批次样本从 24 个提高到惊人的 132 个!
要处理大型神经网络,模型检查点显然是一个非常强大和有用的工具。
原文:https://spell.ml/blog/gradient-checkpointing-pytorch-YGypLBAAACEAefHs
本文亮点总结
1.梯度检查点的工作原理是在反向时重新计算深层神经网络的中间值(而通常情况是在前向时存储的)。
2.神经网络使用的总内存基本上是两个部分的和:第一部分是模型使用的静态内存;第二部分是模型的计算图所占用的动态内。
3.PyTorch API 中有两个不同的梯度检查点方法,都在 torch.utils.checkpoint 命名空间中。比较简单的是 checkpoint_sequential,它被限制用于顺序模型(例如使用 torch.nn.Sequential wrapper 的模型)。另一个是更灵活的 checkpoint,可以用于任何模块。
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“李铎”获取【极市线下沙龙】CVPR2021:通过反转卷积的内在性质进行视觉识别资源
极市干货
YOLO教程:YOLO系列(从V1到V5)模型解读|YOLO算法最全综述:从YOLOv1到YOLOv5
实操教程:使用Transformer来做物体检测?DETR模型完整指南|PyTorch编译并调用自定义CUDA算子的三种方式
算法技巧(trick):半监督深度学习训练和实现|8点PyTorch提速技巧汇总
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge

# CV技术社群邀请函 #
△长按添加极市小助手
添加极市小助手微信(ID : cvmart2)
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
