
【小白学习PyTorch教程】九、基于Pytorch训练第一个RNN模型
「@Author:Runsen」
当阅读一篇课文时,我们可以根据前面的单词来理解每个单词的,而不是从零开始理解每个单词。这可以称为记忆。卷积神经网络模型(CNN)不能实现这种记忆,因此引入了递归神经网络模型(RNN)来解决这一问题。RNN是带有循环的网络,允许信息持久存在。
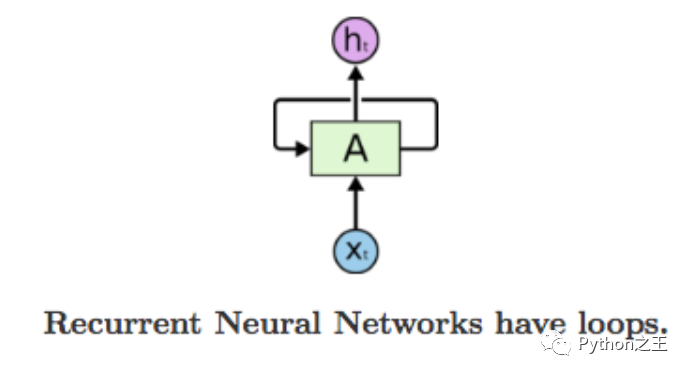
RNN的应用有:
情绪分析(多对一,顺序输入) 机器翻译(多对多,顺序输入和顺序输出) 语音识别(多对多)
它被广泛地用于处理序列数据的预测和自然语言处理。针对Vanilla-RNN存在短时记忆(梯度消失问题),引入LSTM和GRU来解决这一问题。特别是LSTM被广泛应用于深度学习模型中。
本博客介绍了如何通过PyTorch实现RNN和LSTM,并将其应用于比特币价格预测。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.utils.data as Data
from torch.utils.data import DataLoader
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device) #cuda
比特币历史数据集
将通过比较RNN lstm 的性能,来处理时间序列数据,而不是语言数据。使用的数据来自Kaggle比特币历史数据. 比特币是一种加密区块链货币。
data = pd.read_csv("EtherPriceHistory(USD).csv")
data.tail()
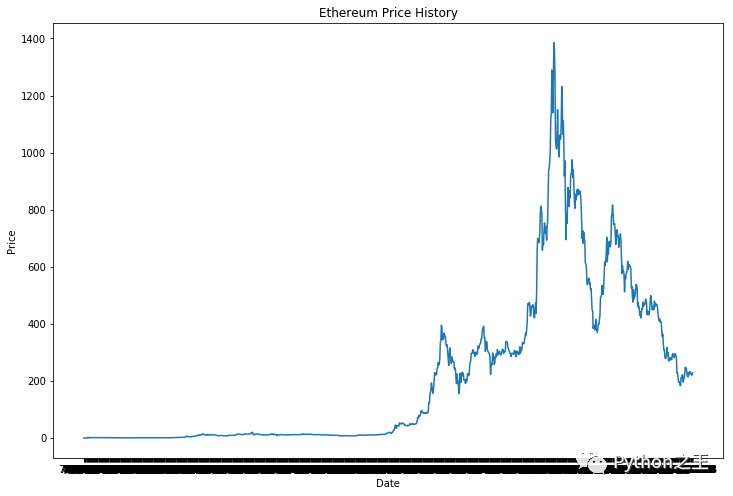
然后我将绘制数据,以查看比特币价格的趋势。
plt.figure(figsize = (12, 8))
plt.plot(data["Date(UTC)"], data["Value"])
plt.xlabel("Date")
plt.ylabel("Price")
plt.title("Ethereum Price History")
plt.show()
# Hyper parameters
threshold = 116
window = 30
input_size = 1
hidden_size = 50
num_layers = 3
output_size = 1
learning_rate = 0.001
batch_size = 16
train_data = data['Value'][:len(data) - threshold]
test_data = data['Value'][len(data) - threshold:]
下面的函数是生成一个滑动窗口,create_sequences扫描所有的训练数据。
def create_sequences(input_data, window):
length = len(input_data)
x = input_data[0:window].values
y = input_data[1:window+1].values
for i in range(1, length - window):
x = np.vstack((x, input_data[i:i+window].values))
y = np.vstack((y, input_data[i+1:window+1+i].values))
sequence = torch.from_numpy(x).type(torch.FloatTensor)
label = torch.from_numpy(y).type(torch.FloatTensor)
sequence = Data.TensorDataset(sequence, label)
return sequence
train_data = create_sequences(train_data, window)
train_loader = Data.DataLoader(train_data,
batch_size = batch_size,
shuffle = False,
drop_last = True)
建立RNN神经网络模型
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.hidden = torch.zeros(num_layers, 1, hidden_size)
self.rnn = nn.RNN(input_size,
hidden_size,
num_layers, # number of recurrent layers
batch_first = True, # Default: False
# If True, layer does not use bias weights
nonlinearity = 'relu', # 'tanh' or 'relu'
#dropout = 0.5
)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# input shape of (batch, seq_len, input_size)
# output shape of (batch, seq_len, hidden_size)
out, hidden = self.rnn(x, self.hidden)
self.hidden = hidden
# output shape of (batch_, seq_len, output_size)
out = self.fc(out)
return out
def init_hidden(self, batch_size):
# hidden shape of (num_layers, batch, hidden_size)
self.hidden = torch.zeros(self.num_layers, batch_size, self.hidden_size)
rnn = RNN(input_size, hidden_size, num_layers, output_size).to(device)
rnn

MSELoss表示均方损失,Adam表示学习率为0.001的Adam优化器。与CNN模型的训练不同,添加了nn.utils.clip_grad_norm_来防止梯度爆炸问题。
def train(model, num_epochs):
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr = learning_rate)
for epoch in range(num_epochs):
for i, (sequences, labels) in enumerate(train_loader):
model.init_hidden(batch_size)
sequences = sequences.view(-1, window, 1)
labels = labels.view(-1, window, 1)
pred = model(sequences)
cost = criterion(pred[-1], labels[-1])
optimizer.zero_grad()
cost.backward()
#防止梯度爆炸问题
nn.utils.clip_grad_norm_(model.parameters(), 5)
optimizer.step()
print("Epoch [%d/%d] Loss %.4f"%(epoch+1, num_epochs, cost.item()))
print("Training Finished!")
train(rnn, 10)

def evaluation(model):
model.eval()
model.init_hidden(1)
val_day = 30
dates = data['Date(UTC)'][1049+window:1049+window+val_day]
pred_X = []
for i in range(val_day):
X = torch.from_numpy(test_data[i:window+i].values).type(torch.FloatTensor)
X = X.view(1, window, 1).to(device)
pred = model(X)
pred = pred.reshape(-1)
pred = pred.cpu().data.numpy()
pred_X.append(pred[-1])
y = test_data[window:window+val_day].values
plt.figure(figsize = (12, 8))
plt.plot(dates, y, 'o-', alpha = 0.7, label = 'Real')
plt.plot(dates, pred, '*-', alpha = 0.7, label = 'Predict')
plt.xticks(rotation = 45)
plt.xlabel("Date")
plt.ylabel("Ethereum Price (USD)")
plt.legend()
plt.title("Comparison between Prediction and Real Ethereum BitCoin Price")
plt.show()
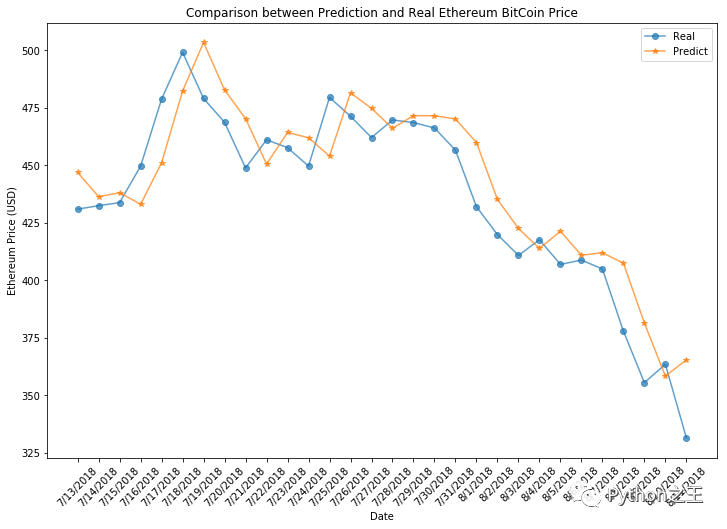
预测价格大致遵循价格变动趋势,但价格绝对值与实际价格相差不大。因此,考虑到价格的巨大变化,但实际它的预测并不坏。可以通过修改模型参数和超参数来改进。
# Save the model checkpoint
save_path = './model/'
if not os.path.exists(save_path):
os.makedirs(save_path)
torch.save(rnn.state_dict(), 'rnn.ckpt')
评论