
带你用数据分析看透美国总统大选
导读:很多小伙伴都在问,数据分析到底是什么?该怎么做?数据思维又是什么?数据分析怎么应用到日常工作生活?你会发现得到各种各样的答案——有人说数分不就是做表嘛,有人说不对不对,数分就是做分析报告,还有人说,数分就是大数据,是人工智能。按我说呢,这些都对,也都不对,因为这只是大家看到的冰山一角。
其实,数学的应用从游牧时代开始,就已经涉及到数据分析了。今天抓了一头野猪,明天抓了一头羊,所以猎物总共有两只,怎么分配呢?羊可以养起来,因为羊可以产奶,给孩子补充营养,猪可以杀掉,一天吃不完,那就分两天吃,首领分多一些,其他人分少一些……大家留意到没有,这正好是数据分析的思维。这个思维延伸到现在,就变成了,公司今天收入多少,奖励池可以多分一些给贡献度大的员工,然后剩余的可以当做下个季度激励方案的奖金……总之,数据分析的历史很悠久,可以说从人们开始使用数字的时候开始就已经有数分的意识了。
那么,为了更好的理解数据分析的这些问题,我们现在来结合美国大选这个具体例子,带着大家做一场“探索性数据分析”。
美国总统大选投票结果已公布,一阵热闹过后,是否好奇,想看清这场“闹剧”是怎么回事?出于这个目的,我们收集数据,来做一次“探索性数据分析”之旅。
看着选票地图,很多人想不通的是,为什么老百姓都参加了投票,但是官方显示的票数,每个州只有几票?这些票到底怎么来的?
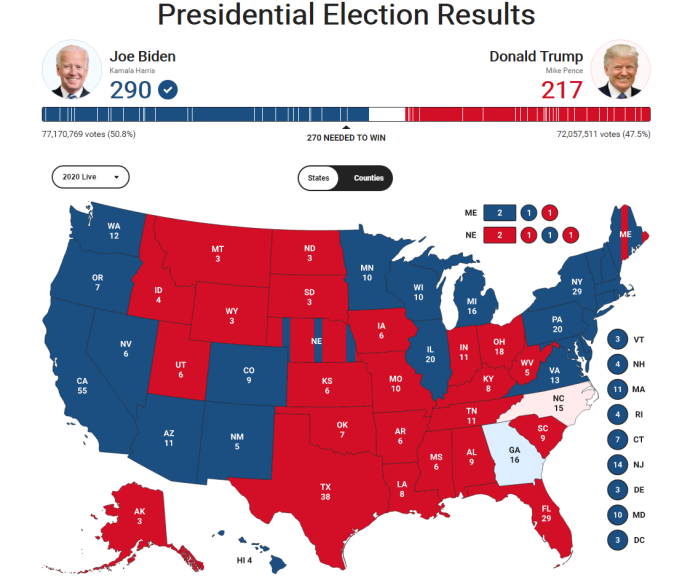
这就和美国的选举规则有关,美国各州人民都参与了投票,但是总统并不是由他们直接选出来的,能投票选总统的是另外一波人“国会议员”:
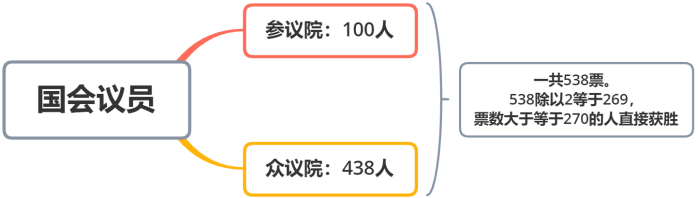
既然是议员投票选总统,选民还投票干嘛?
这和另外一个规则有关,虽然议员的票数决定了谁做总统,但是议员不能决定自己想投给谁,而是由选民决定的,也就是说,全体选民投票的结果决定议员的票给谁。比如:阿拉巴马州有超过50%的选民投票给A,那么这个州所有议员的票都属于A,这个规则叫“赢家通吃”。
所以我们看到各州的投票结果显示 XX : 0 赢的人得到所有选票,输的人一张也得不到。
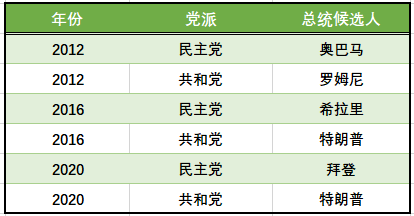
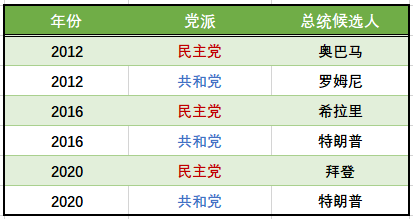
总统选举背景材料(近三届的候选人和党派)
理解完业务,开始产生以下疑问:
有哪些州?
选举的州作为指标:需要所有州的名字
每个州可以投多少票?
每个州的投票数:需要所有州对应的投票票数
这些票最后投给了谁? 但是每一届参与选举的候选人都不一样,这个“谁”,在不同的选举年份中怎么做交叉对比?
想到的字段:每次选举的两个人分别代表两个党派,为了做交叉对比,得票的主体用“党派”
1、寻找美国州名的数据。
在电脑上搜索到有州名的网页,上面看到一张州名列表。我们用EXCEL根据以下步骤把这张表提取出来。
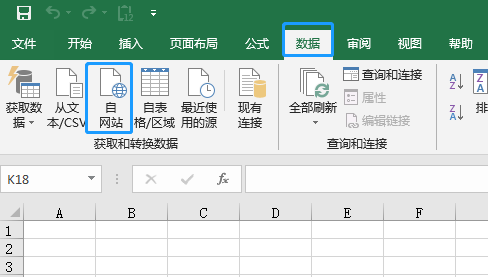
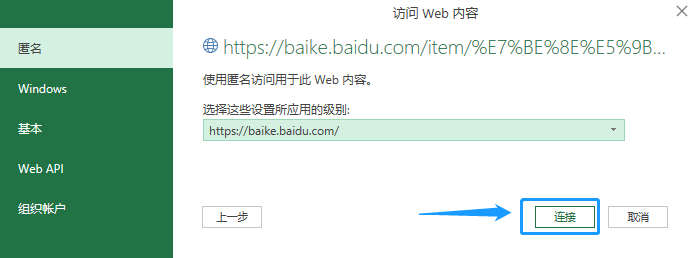
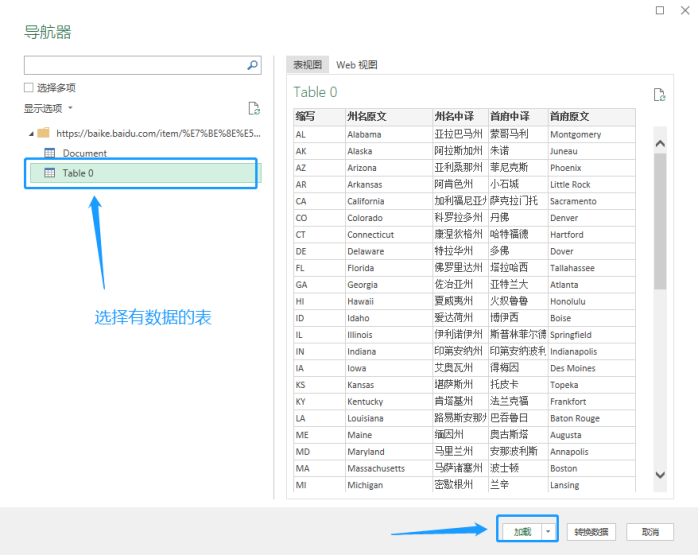
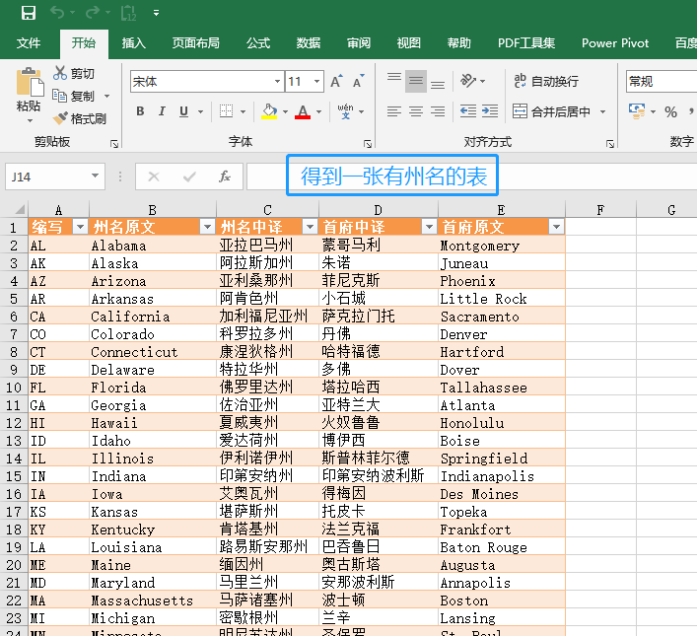
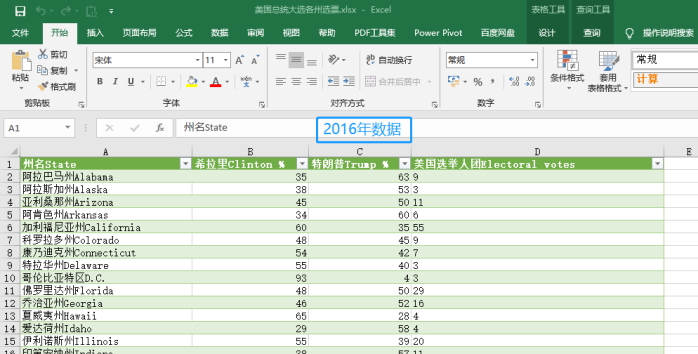
2、获取近三年的选票数据。
在网上找到2016年选票数据,用EXCEL直接获取下来。(步骤如上略)
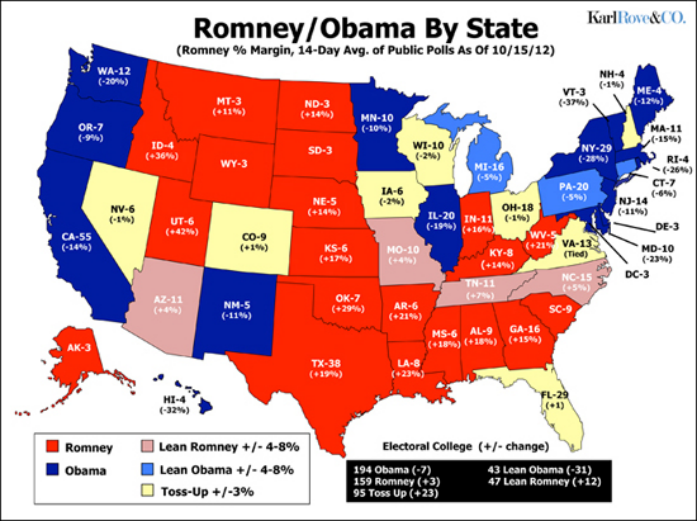
但是找2012年选票数据的时候,只找到一个选票地图
再去找2020年选票,找到最详细的数据,复制时发现是“图片格式”!
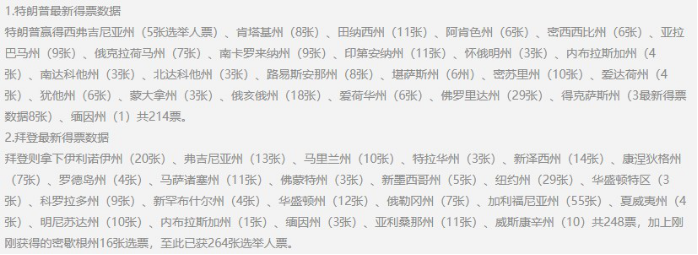
那我们怎么获得图片里这些数据,难道要抄下来?
不!我们是“数据分析师”,我们要专业,不能手抄,我们用Python!
Python获取图片中信息:
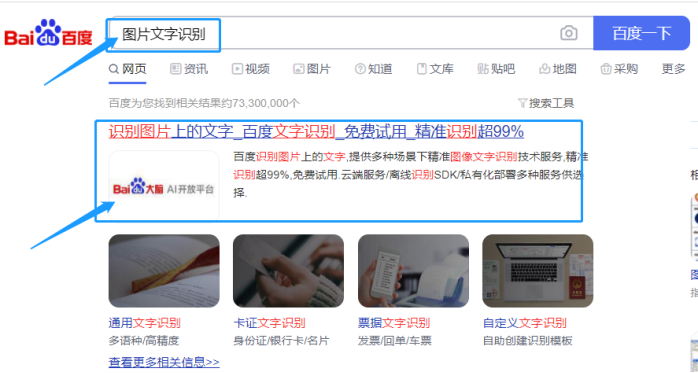
市面上有免费图片文字识别的开源功能,我们只需要调用相应接口,此处选择了百度的图片文字识别。
思路:用Python 调用现成的“图片文字识别接口”,识别提取两张图片中的文字数字信息。
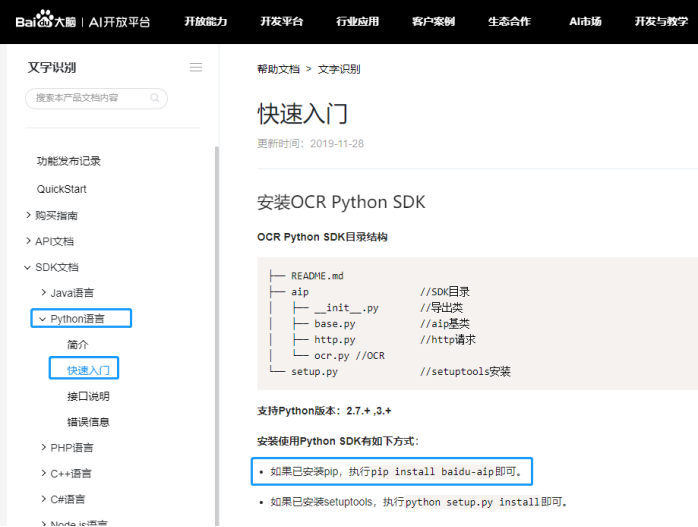
按照教程先安装“百度接口包”
打开python的shell 如下图安装“百度接口包”
再按照教程“新建AipOcr”
打开自己的Python编辑器(此处我用的是PyCharm),把教程上的代码拷贝到PyCharm
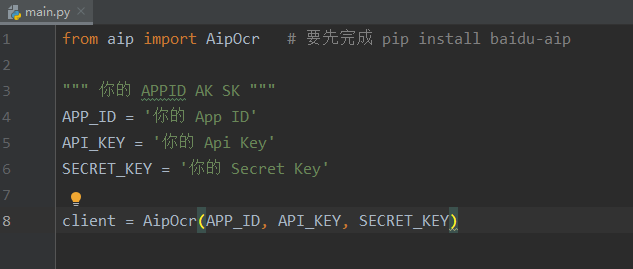
以上步骤是生成一个Client对象,这个对象能调用“百度接口”里面的各种功能接口。
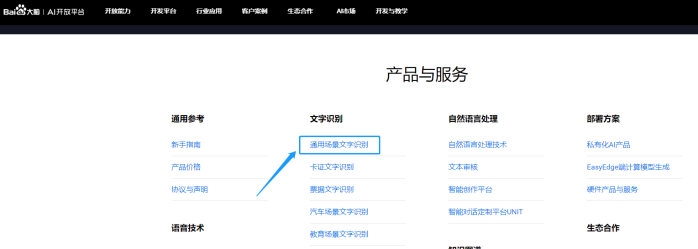
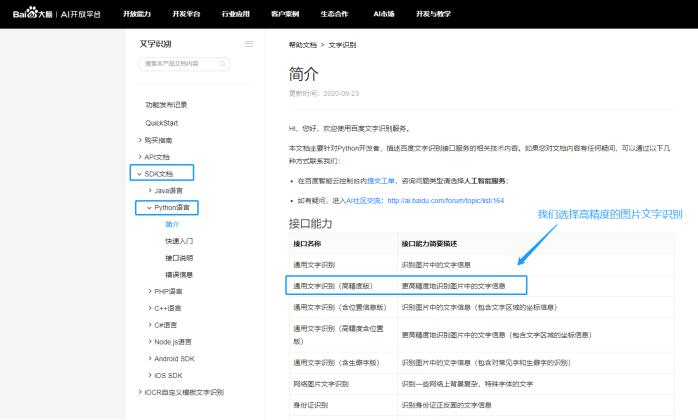
那么下一步告诉python,这个对象要去调用哪个接口。如下图我们之前选择了“通用文字识别(高精度版)”
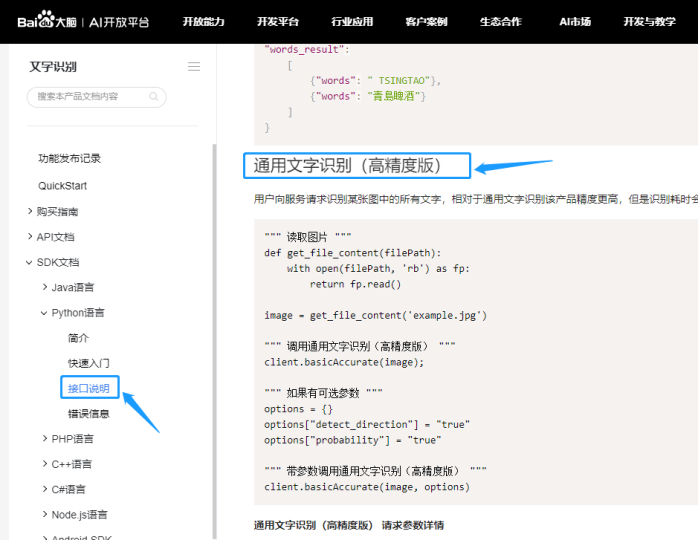
在接口说明里,找到了这个接口的调用方法,按照教程,把需要的部分拷贝下来
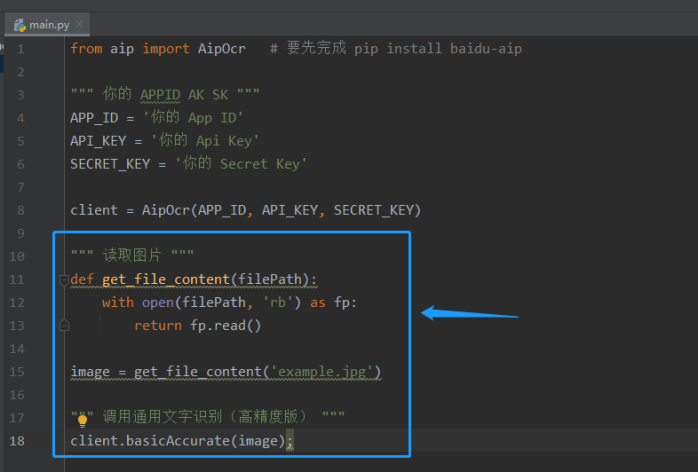
获取完官方标准的教程代码,现在我们来完善他。去“控制台”注册登录账号和创建应用。
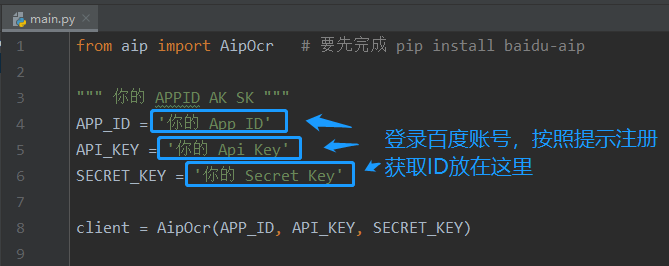
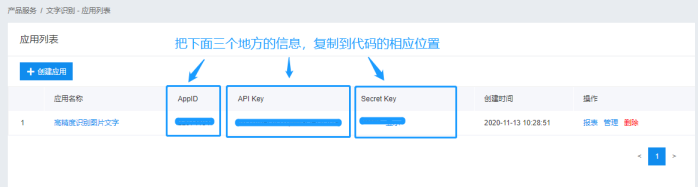
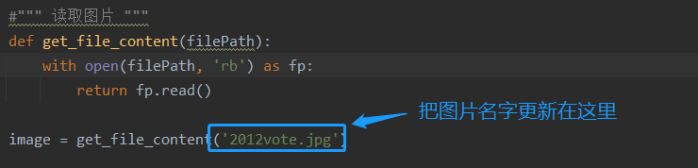
更新完ID再告诉python是哪张图片
Python默认去识别同一个项目文件夹下的图片,所以把之前网络上找到图片直接保存在python这个代码的文件夹下
当然也可以再调用两个包,做成“截图,保存,识别文字,三个步骤一体的python小工具”,此处不做展开。
最终修改完成的代码如下:
from aip import AipOcr # 要先完成 pip install baidu-aip
#""" 你的 APPID AK SK """
APP_ID = '你的APP_ID'
API_KEY = '你的API_KEY'
SECRET_KEY = '你的SECRET_KEY'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
while 1:
#""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('2020vote.jpg')
#""" 调用通用文字识别(高精度版) """
client.basicAccurate(image);
message = client.basicAccurate(image)
message_result = message['words_result']
for i in message_result:
print(i['words'])
break
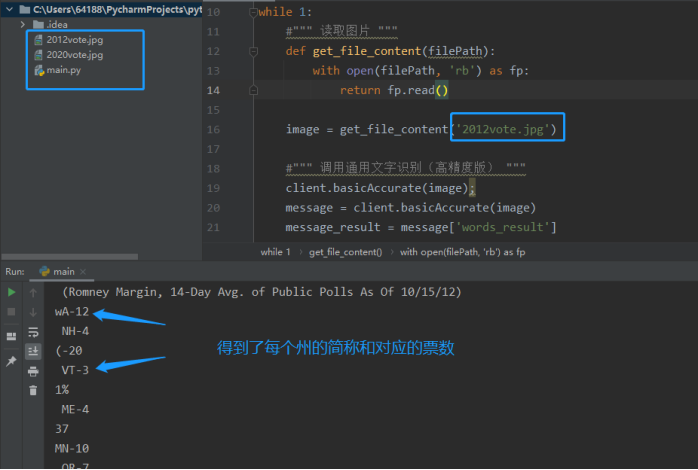
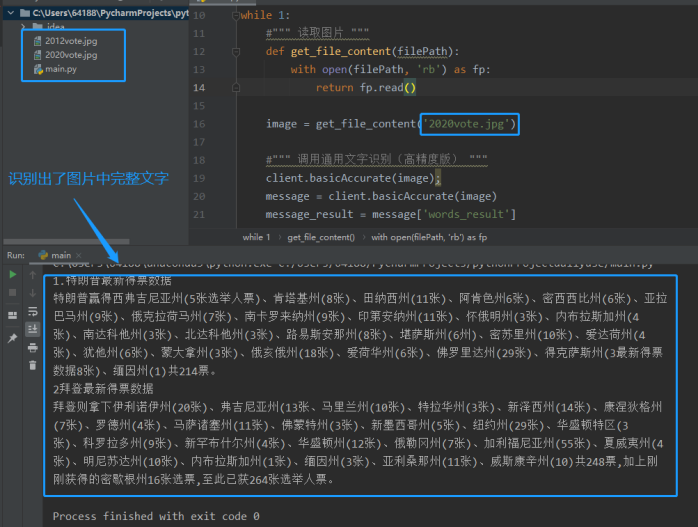
此处数据量不大,把获取的数据放在excel里面清洗后,得到格式统一的表。
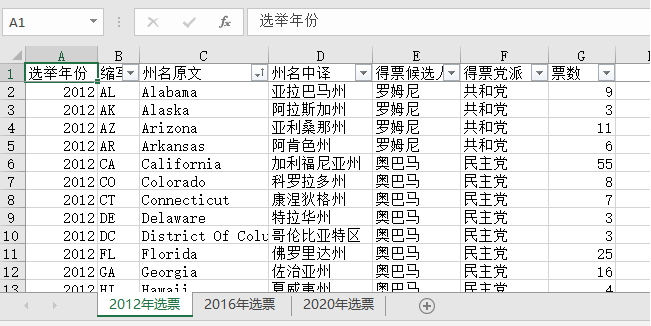
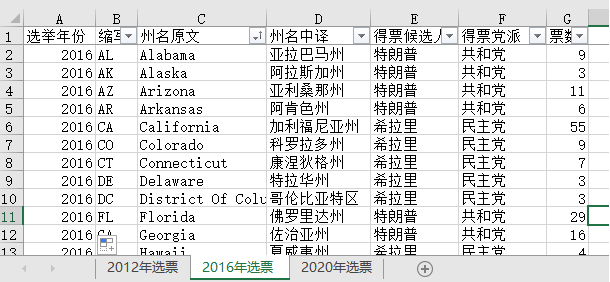
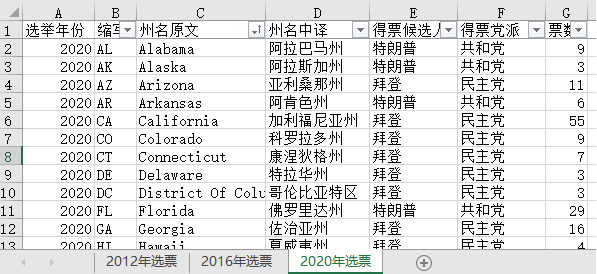
有清洗干净的完整数据之后,我们开始探索分析,这里用一种简单又低成本的方式:Power BI
为了便于分析,再载入一张年份表和一张党派表

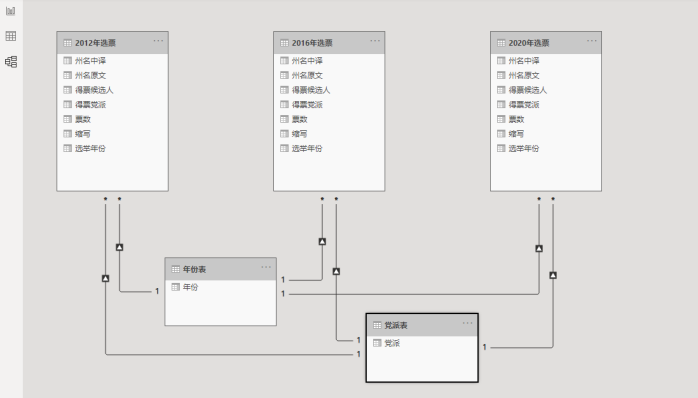
全部载入后,在Power BI里面做一个简单建模
先做个选票地图看看
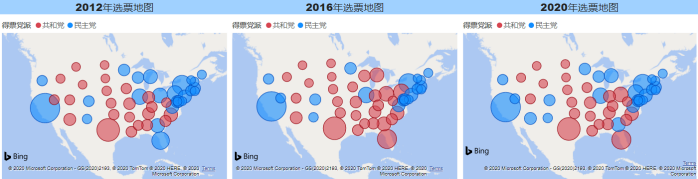
看着做完的地图,似乎发现了些什么!
首先,气泡大小代表州的票数,虽然每年根据人口数量相应票数有变化,但是大体基本一致。
其次,这三张图,看着很相似,颜色的分布变化不大。也就是说,每年都有一些固定支持共和党或者固定支持民主党的州。
最后,有少部分州,是每年支持的党派都不一样。
这部分的结论是:虽然每次选总统是两个人竞选,但其实支持他们的人,很多是出于这些人所在的党派。
再去探索一下票数
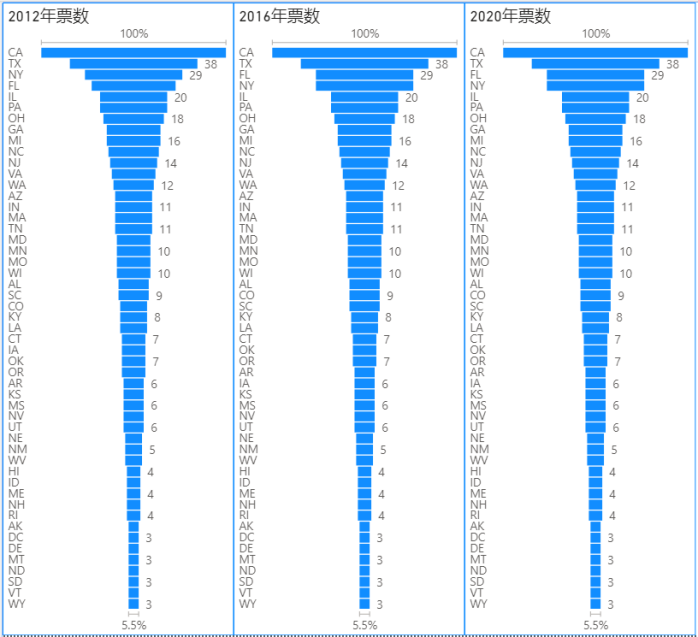
可以看出每个不同的州,票数相差很远,有约20%左右的州,占到总票数一半以上。也就是以下地区可投选票的数量较多
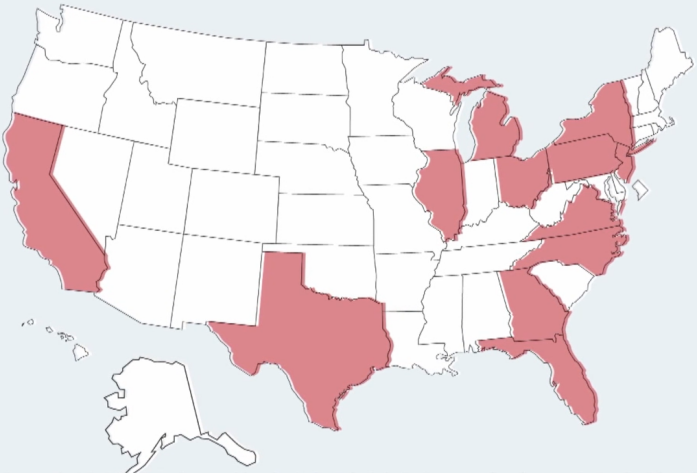
这部分结论是:尽量去争取上图的州,获胜机会大。
最后总结数据分析结论如下:
1、有部分州,每年都一定选择共和党或者一定选择民主党,剩下小部分州会在两党之间摇摆,也就是说,美国总统大选,候选人背后代表的党派影响力,大于他们个人的影响力。
2、从竞选策略上来说,每年可以“不用太关心”一定会投票给自己党派的州,应该把重点放在“摇摆州”上。而“摇摆州”应该先从上图中占票数多的州开始争取,然后再根据各州的票数占比,区分轻重缓急依次做竞选攻略。

总结
做了一次完整数据分析,让我们回顾整个步骤:
第一步:确定分析目的
第二步:理解业务
第三步:确定研究指标
第四步:寻找原始数据
第五步:数据清洗
第六步:数据分析
第七步:总结结论
以上就是一次标准又简洁的数据分析全过程演示。然而,在实际的业务分析中,一般在第七步得到了结论后还会回到第一步分析的目的,去与业务或者运营人员沟通,反馈结论,比如是否有异常、异常原因、下一步动作等事宜,这也就使数据分析形成了“闭环”。然后相关业务人员再次提出疑问去确立新的分析目标,通过如此反复的迭代优化及分析,可提高营销活动有效性,提高投资回报率等等数据指标……“闭环”其实就是“扬长避短”,让数据引导动作到更有价值的地方,实现资源配置最大化,也就是所谓的数据驱动业务。
总而言之,数据分析的有趣之处就是,当你把自己想成福尔摩斯的话,那数据背后一定存在真相。也由此可见,数据分析的应用范围很广,在各行各业都可以渗透,为什么可以渗透?那是因为各行各业都离不开数字,只要有数字的地方,就有数据分析的用武之地;且数据分析的内容也可以很深,从加减乘除算数运算,到建模回归机器学习,都已经广泛运用起来了;从上面的分析看,数据分析的工具那更是数不胜数,爬虫、清洗、可视化、数据库等,只有你想不到的,没有市场上满足不了需求的。数据分析就像一双翅膀能让你飞得更远,希望大家通过这个具体的例子,学会用数据分析赋能到你工作生活的方方面面。
--end--
扫描下方二维码
添加好友,备注【交流】
可私聊交流,也可进资源丰富学习群