
基于RGB-D多相机的实时3D动态场景重建系统
本文为媒矿工厂发表的技术文章
原标题:Real-time 3D Reconstruction of Dynamic Scenes with Multiple Kinect v2 Sensors
作者:周凯, 宋利, 胡经川, 郭帅, 董瑜(上海交通大学图像所), Yanying Sun, Yesheng Xu(Intel Corporation, China)
发表会议:IBC2021
原文链接:https://www.ibc.org/download?ac=18719(或点击阅读原文跳转)
目录
Introduction
主要工作
系统概述
硬件架构
软件架构
主要算法
帧同步
外参标定
点云重叠区域去除
后处理
实验结果
性能
质量
总结
参考文献
Introduction
三维重建是捕捉真实物体的形状和外观,并还原三维立体结构的过程。实时三维重建已经成为多媒体和计算机图形领域的活跃研究课题之一。它可以应用于许多新颖的场景,如自由视角视频、3D游戏互动以及增强现实或虚拟现实。这些应用大多对实时性能有很高的要求。然而,尽管实时重建技术在静态物体重建领域已经很成熟,但受限于庞大的数据量和算法的复杂性,动态场景的实时重建仍然是一个很大的挑战。
由于用于深度估计的立体匹配算法的高复杂性和近年来低成本 RGB-D 相机的快速出现,使得 RGB-D 相机通常被用作实时系统的数据采集设备。微软已经发布了三种深度传感器:Kinect v1、Kinect v2 和 Azure Kinect。尽管 Azure Kinect 是前两代相机的继承者,但由于 Azure Kinect 在 2020 年 3 月才发布,Kinect v2 相机仍然是研究中使用最广泛的传感器。许多相关的实时重建系统都使用 Kinect v2 作为数据采集设备,因为它提供了可接受的分辨率和可承担的成本。
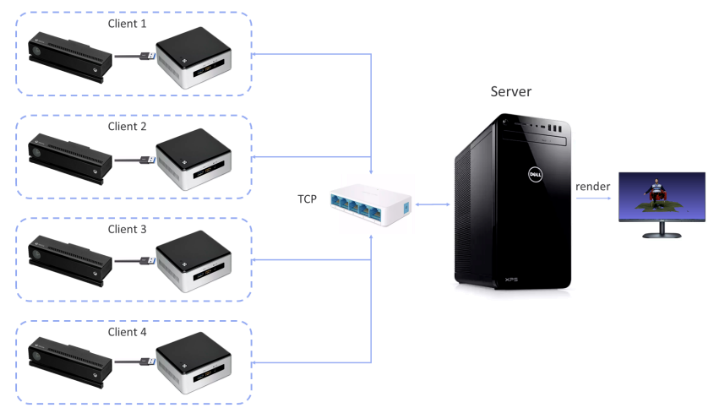
现有的基于 Kinect v2 的三维重建系统有很多缺点。首先,现有系统通常采用客户端-服务器结构,如图1所示,每个客户端驱动一台相机,所有的客户端连接到同一个服务器上,由于相机数量较多,通常需要多台计算机才能完成系统搭建,结构显得异常复杂。其次,在实时性能方面,现有系统采用顺序执行的算法设计,从相机采集一帧数据后,直到当前帧处理结束才会采集下一帧,因此,随着场景大小和相机的数量的增加,现有系统的帧率会相应下降。
主要工作
本文中,我们提出了基于 Kinect v2 相机的实时三维重建系统。针对动态场景的三维重建场景,通过流水化设计,集成多线程和 CUDA 加速等优化,实现了系统各组件复杂度和重建质量的平衡,使得重构运动物体变为现实。
本文的主要工作为:
一种简易的中心式 3D 重建系统,仅需要一台电脑和多个深度相机,可以实时重建动态场景。
集成多线程和 CUDA 加速等优化方案,在性能方面达到了相机固有帧率 30 fps。
开放式解决方案,将会在 https://github.com/sjtu-medialab/Kinect3D 持续发布并更新。
系统概述
硬件架构
如图 2 所示,系统主要由一台相机和多个 Kinect v2 相机组成,各相机面朝中心呈圆形分布。每个 Kinect v2 相机包含一个彩色相机和一个深度相机,以 30 fps 的帧率同步采集 1920 x 1080 的彩色图和 512 x 424 的深度图。
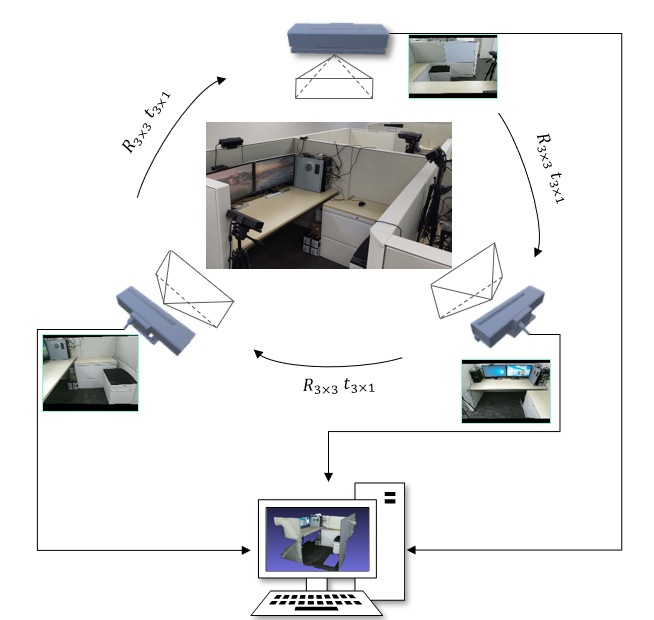
在相机 SDK 方面,由于官方驱动不支持多个相机同时连接,因此采用了第三方的开源驱动 libfreenect2[1],支持单台 PC 通过 USB 3.0 连接高达 5 台相机。
软件架构
图 3 展示了系统的软件流水线设计,它由多个模块组成,包括多路 RGB-D 流采集,帧同步,点云融合,后处理和 OpenGL 交互式渲染等。各个模块是并行的,彼此之间的数据通过队列进行分离。
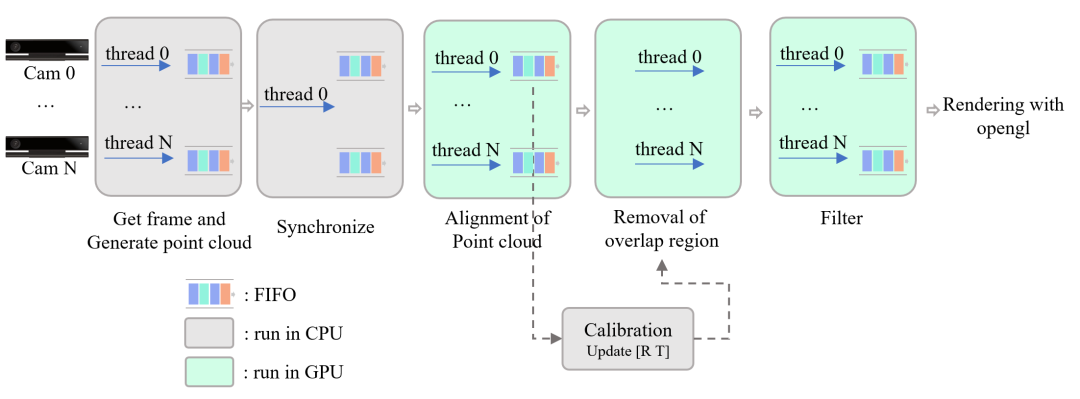
为了同时采集多路 RGB-D 数据流,我们为每个相机分配了一个单独的线程,并通过时间戳对来自各线程的帧进行同步,然后送到 GPU 上进行计算并最终渲染,这种并行化的设计是实现实时性能的重要基础。
主要算法
帧同步
尽管相机文档给出的帧率是 30 fps,但是在实际工作中,每个相机的帧率略有抖动。因此系统分配了一个单独的线程实现了基于时间戳的软件同步,对于某一个相机采集的帧,将来自其他相机且时间戳间隔在16ms以内的视为一组同步帧,从而将所有相机的帧同步在 16 ms以内。
外参标定
相机外参标定是获取相机在世界坐标系中姿态的过程,从而能够将点云从各自的相机坐标系融合到世界坐标系中。每个相机的姿态由旋转矩阵 和平移矩阵 组成。相机标定分为两步:基于 2D marker的粗略标定和基于 3D 匹配点的精细标定。
粗标定
在粗标定环节,我们使用了[2]中使用的 marker 进行标定。一个典型的 marker 如图 4 所示,由一个5边形和内部 3x3 的黑白方块组成。

在标定过程中,世界坐标系原点建立在marker的中心,每个相机会检测黑白交界处的角点,得到其在图像中的像素坐标,进一步根据深度图和相机内参得到角点在相机坐标系中的 3D 坐标,而角点在世界坐标系中的位置是已知的,从而能够得到相机坐标系和世界坐标系的转换关系,也即相机外参。
其中 是世界坐标系中的点, 是相机坐标系中的点。一个典型的标定过程如下图所示:
精细标定
粗标定的缺点是标定精度会受到平面关键点检测精度的影响。为了降低匹配误差,我们使用了迭代最近点算法(ICP)对相机初始姿态进行迭代优化,得到旋转矩阵 和 平移矩阵 。最终标定得到的转换关系为:
在精细标定步骤,由于ICP算法的高复杂度,系统部署了一个"离线"线程。每次按下 calibrate 按键,系统流水线会为 ICP 输出一个同步帧。标定完成后,将丢弃当前帧并更新系统中的相机外参。这种离线模式确保了在精细标定过程中不影响系统的性能。
点云重叠区域去除
不同相机产生的点云不可避免地存在很大一部分重叠区域,尤其是相邻两个相机之间,重叠区域中存在大量冗余和不匹配的数据。在本系统中,在每两个相邻传感器之间执行重叠区域的去除。该系统中应用的方法类似于[3],通过外部参数矩阵将一个传感器的点映射到另一个。在[3]中,由于其迭代策略,去除重叠区域是系统的性能瓶颈,通常需要数百毫秒,这迫使他们采用了粗到细的策略。在本系统中,我们考虑到每个像素的映射是独立的,因此可以在 GPU 中实现,从而大大减少了执行时间,只需几毫秒。
设 A 和 B 为两个相邻的相机,本系统实现的算法如下图所示,该算法可概括如下:
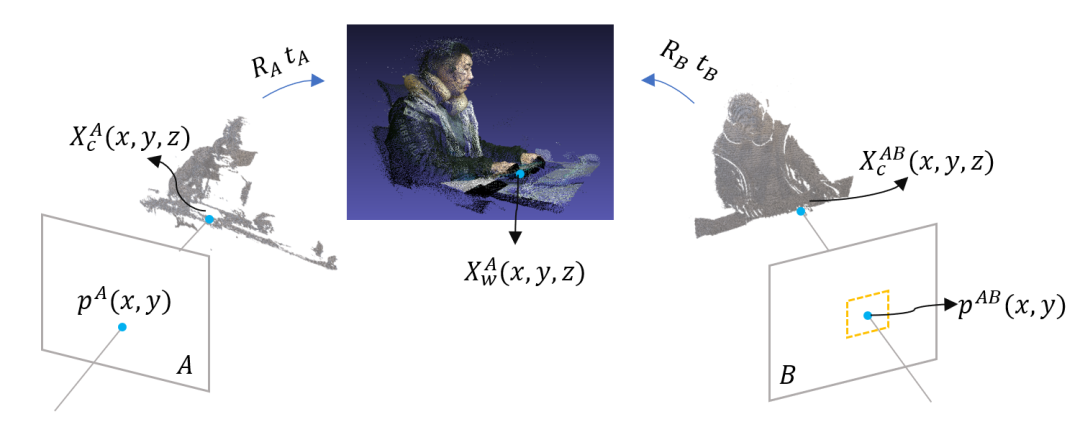
将相机 A 中的像素根据深度图和相机外参映射到世界坐标系,得到相机 A 的点云; 将 根据相机 B 的外参,映射到 B 的相机坐标系,进一步根据 B 的内参,映射到 B 的像素坐标; 与相机 B 的深度图进行比较,若深度值之间的差值小于给定的阈值,说明 A 和 B 在当前点是重叠的,从而去除 A 中的对应点。
后处理
后处理主要包括了点云的滤波,用于抑制点云的噪声。由于 TOF 相机的限制,Kinect v2 深度图中存在很多缺失和不稳定的像素,因此重建的模型包含大量噪声。考虑到点云过滤算法的高复杂度,这是实现实时帧率的主要困难之一。
受[4]中提出的重构算法“Step Discontinuity Constrained (SDC) triangulation”的启发,我们在系统中部署了步长不连续约束,并实现了一种名为“SDC filter”的算法。考虑到深度图的像素和3D点是一一对应的,深度像素之间的邻域关系代表了3D空间点的拓扑结构,因此对于深度像素中的每个点,在给定的邻域内比较其与周围像素的距离差异,只有满足一定的距离约束,才会将其保留,否则将其作为噪点去除。后续的实验部分证明了这种滤波算法的有效性。
实验结果
本部分,我们给出了系统的实验结果。整个系统由 C++ 和 CUDA C 编写,运行在一台 PC 上,系统配置为:i9-10900K, RTX2080Ti, 32GB RAM, Linux Manjaro 64bit。
性能
我们采集了连续的 1000 帧,并记录了系统各模块的延迟,如下图所示: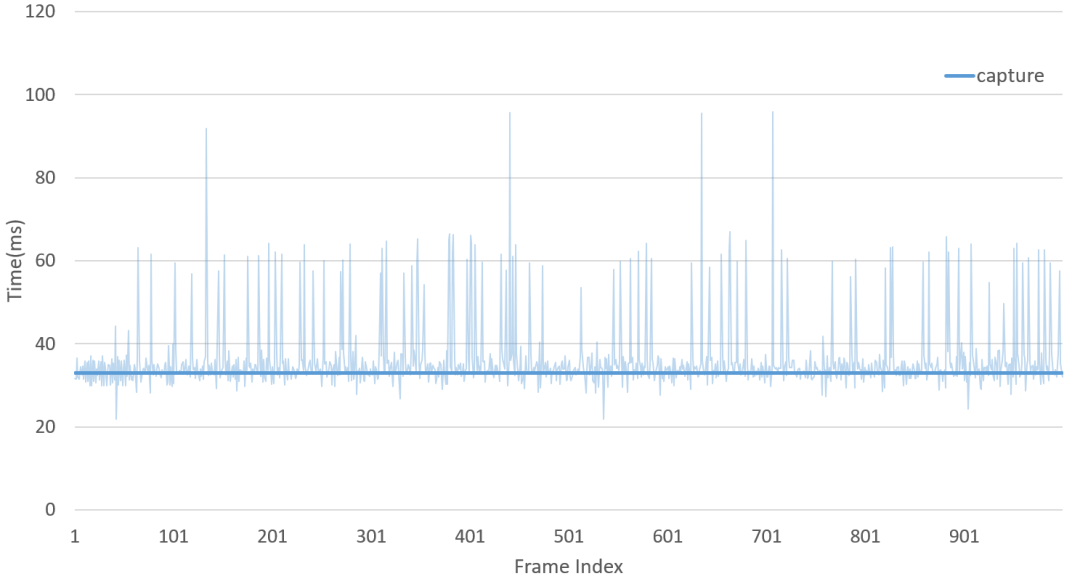
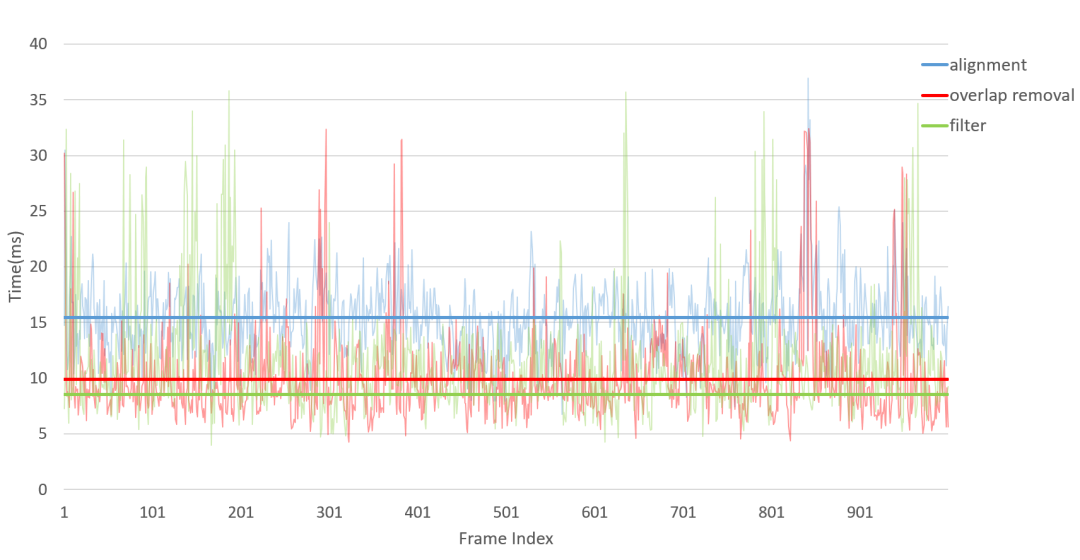
下方的表格给出了更加详细的数据:
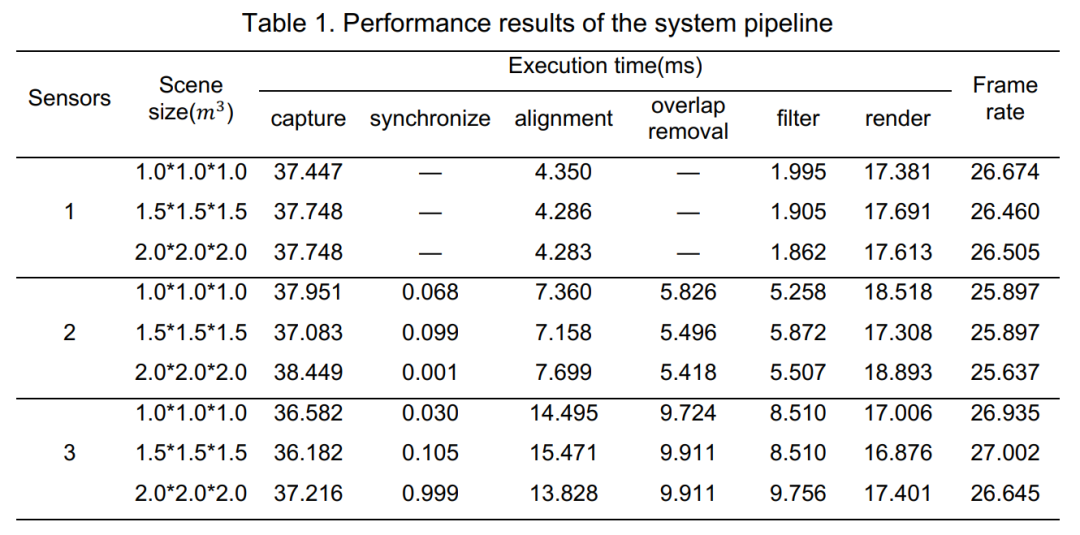
从表格中可以看出,系统帧率平均约为 26 fps,略低于相机给定的 30 fps。经过分析,这主要是由于相机采集过程中产生了丢帧,图7给出了丢帧的情况,在大多数情况下,采集一帧的时间为 33 ms,但在一些情况下由于未知的硬件原因,数据产生了丢失,从而导致系统最终的帧率略低于 30fps。
此外,我们的系统在相机数量增加时,系统性能表现差异不大,这主要得益于多线程并行的设计,确保了在动态场景中也能实现实时重建。
质量

上图给出了三个角度的重建质量。从左到右质量逐渐提高,分别是:原始点云,经过重叠区域去除,经过 SDC 滤波和最终重建结果。
附上三个角度的动态重建结果:



总结
在本文中,我们实现了一个低成本的实时系统,支持连接到一台计算机的多个 Kinect v2 传感器。系统的优点是高帧率和简洁的架构。这主要由两部分来保证。在实现层面,采用流水线设计模式,模块采用FIFO并行分离,集成CPU多线程和GPU并行加速。在算法层面,采用了基于深度连续性的点云过滤等轻量级算法。最后,如结果所示,整个系统都可以达到相机的固有帧率。
未来,我们计划集成更复杂的算法来提高点云的质量,并探索实时表面重建的可行性。
最后附上演讲视频:
参考文献
[1] Libfreenect2: Release 0.2, April 2016.
[2] Marek Kowalski, Jacek Naruniec, and Michal Daniluk. Livescan3d: A fast and inexpensive 3d data acquisition system for multiple kinect v2 sensors. In 2015 international conference on 3D vision, pages 318–325.IEEE, 2015.
[3] Dimitrios S Alexiadis, Dimitrios Zarpalas, and Petros Daras. Real-time, full 3-d reconstruction of moving foreground objects from multiple consumer depth cameras. IEEE Transactions on Multimedia,15(2):339–358, 2012.
[4] Adrian Hilton, Andrew J Stoddart, John Illingworth, and Terry Windeatt. Reliable surface reconstruction from multiple range images. In European conference on computer vision, pages 117–126. Springer,1996.