
在手机上实现实时的单眼3D重建
点击左上方蓝字关注我们

转载自 | 计算机视觉工坊
一、背景与贡献
本文提出了以中多视图关键帧深度估计方法,该方法即使在具有一定姿态误差的无纹理区域中也可以鲁棒地估计密集深度,消除由姿势误差或无纹理区域引起的不可靠深度,并通过深度神经网络进一步优化了噪声深度。
本文提出了以中有效的增量网格生成方法,该方法可以融合估计的关键帧深度图以在线重建场景的表面网格,并逐步更新局部网格三角。这种增量网格方法不仅可以为前端的AR效果提供在线密集的3D表面重建,还可以确保将网格生成在后端CPU模块上的实时性能。这对于以前的在线3D重建系统来说是有难度的。
本文提出了带有单眼相机的实时密集表面网格重建管线,在手机上实现了单眼关键帧深度估计和增量网格更新的执行速度不超过后端的125ms/关键帧,在跟踪前端6DoF上快速到足以超过每秒25帧(FPS)。
二、算法流程
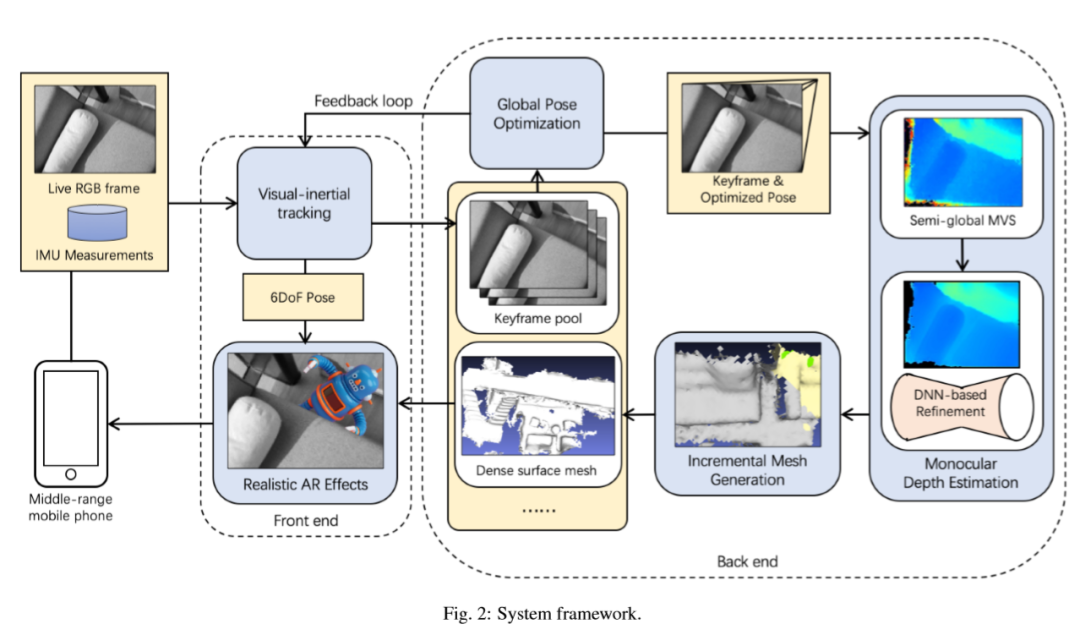
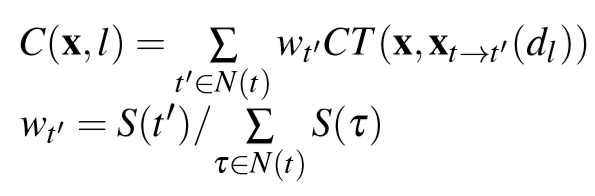
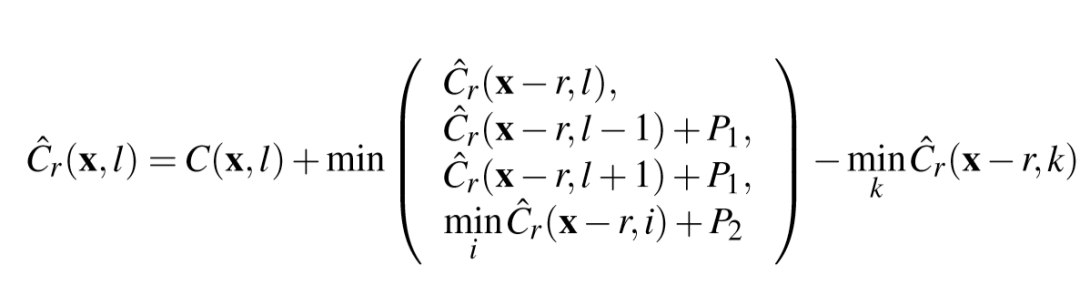
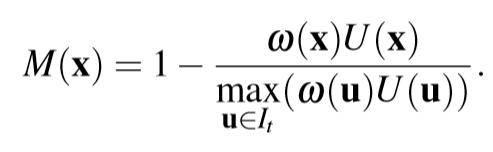
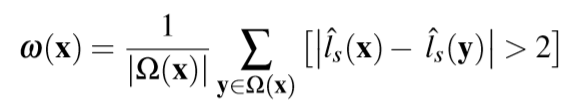
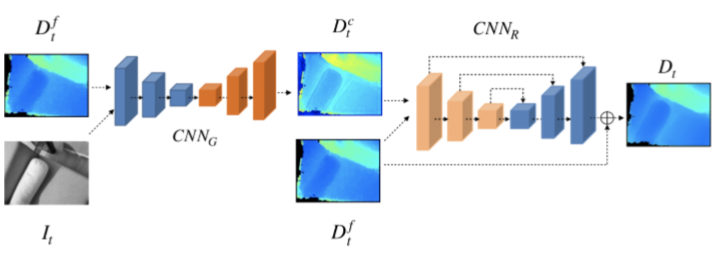
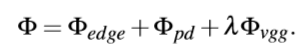
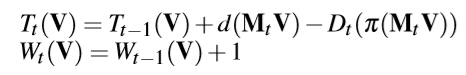
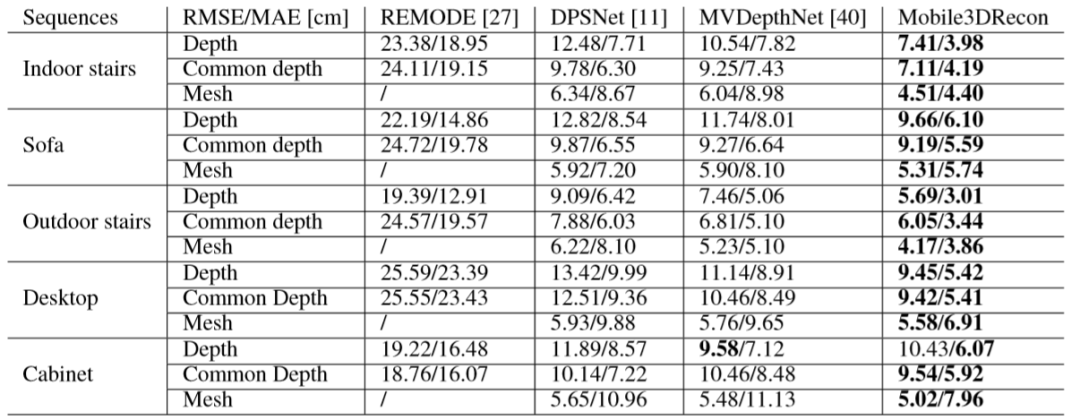
三、主要结果

原关键帧图像及其两个选定的参考关键帧图像;“室内楼梯”参考帧中的两个代表性像素及其极线绘制出从前端的6DoF跟踪来证明某些相机姿态误差的数据。
通过反投影进行的多视图SGM和相应点云的深度估计结果。
基于置信度的深度滤波后的结果及其对应的结果
在基于DNN的参考及其相应的点云之后的最终深度估计结果。


END
整理不易,点赞三连↓
评论