
开辟新视野之高层训练框架 PyTorch-Ignite
1 前言
https://github.com/open-mmlab/mmcv
本文介绍另一个高层封装训练框架 Ignite, 其官方介绍是:PyTorch-Ignite 是一个可帮助在 PyTorch 中灵活透明地训练和评估神经网络的高级库。可以发现 Ignite 对标的是 MMCV 和 Pytorch-Lighting,但是相比 Pytorch-Lighting 更加简单。本文对 Ignite 进行整体性分析希望大家能够开辟新视野,换个姿势了解其他训练框架的封装方式,而不要拘泥于某一种固定的开发模式,阻碍自身成长。
由于 Ignite 内容比较多,本文分析会有侧重于整体分析,无法顾全所有内容。如果想了解的非常透彻,建议和我交流或者留言。
Github 地址:
https://github.com/pytorch/ignite
官方地址:
https://pytorch-ignite.ai/
Docs 地址:
Ignite Your Networks! — PyTorch-Ignite v0.4.7 Documentation
Guides 地址:
https://pytorch-ignite.ai/how-to-guides/
本文代码比较多,手机端阅读体验不佳,建议采用电脑端查看或者后续移步知乎社区,知乎 ID: 深度眸
2 Ignite 特性分析
当前分析版本是 V0.4.7。
2.1 核心特性
其核心特性是:
比纯 PyTorch 更少的代码,同时确保最大程度的控制和简单性
库方法和没有程序控制反转 - 在需要的地方和时间使用 Ignite
用于指标、实验管理器和其他组件的可扩展 API
这里解释下控制反转 (Inversion of control) 。IoC 是一种设计思想,用于解决对象与对象实例化耦合问题,在 Spring 等大型应用程序框架中有着非常多的应用。控制反转是指把传统模式中需要自己通过实例化构造函数,或者通过工厂模式实例化的任务交给容器来避免强耦合。这种做法其实非常常见,和我们常说的依赖抽象而不是依赖实体非常类似。举个最简单的例子:
# 沙丁鱼class SardineFish:pass# 石斑鱼class GrouperFish:pass# 吃饭class Dining:def __init__(self):self.fish=SardineFish()def eat(self):return self.fishdining=Dining()dining.eat()
今天想吃沙丁鱼,因此直接在 Dining 类中实例化了 SardineFish 类,这是一种非常强的耦合关系,一旦我明天想吃石斑鱼就麻烦了。控制反转可以解决上述问题,将鱼类具体实例化交给容器实例化,Dining 内部只是被动的获取类对象即可,不负责创建实例,而是交给容器类。自己需要主动实例化对象变为被动获取,依赖对象控制权被反转,不需要再考虑如何实例化其他依赖的类。
class SardineFish:def name(self):return 'SardineFish'class GrouperFish:def name(self):return 'GrouperFish'class Container:def __init__(self):self.fish_dict={}def bind(self,fish):self.fish_dict[fish.name]=fishdef get(self,name):return self.fish_dict[name]class Dining:def __init__(self,container):self.container= containerdef eat(self,name):return self.container.get(name)container= Container()container.bind(SardineFish())container.bind(GrouperFish())dining= Dining(container)dining.eat('GrouperFish')
Ignite 没有程序控制反转,是因为他都是基于方法或者函数进行扩展开发,不存在对象和对象自己的实例化耦合问题。
作者指出其功能上主要特点是:
极其简单的训练引擎和事件系统
开箱即用的指标,可轻松评估模型
用于组成训练 pipeline、保存以及记录参数和指标的内置处理程序
事件是什么?可以简单理解为一个动作 action,例如保存权重就是一个事件, 通过丰富的事件系统可以实现灵活的无侵入的扩展功能。
需要指出的是,Ignite 文档非常多也非常全面,包括 Getting Started、Documentation、Additional Materials、Examples、Tutorials 和 Projects using Ignite 等等,如果你非常有兴趣,可以阅读相关 project,有非常多的实例。
2.2 主要特性
2.2.1 简化训练和验证循环
不再需要为 epoch 和 iterations 手动设置 for/while 循环,用户初始化的实例化引擎会自动处理和运行。这算是作为一个高层训练框架包装器的最基本要求了吧。
2.2.2 强大的 Event 事件和 Handler 处理器
Ignite 处理程序很酷的地方在于它们提供了无与伦比的灵活性(例如与回调相比)。处理程序可以是任何函数:例如 lambda、简单函数、类方法等。因此我们不需要从接口继承并覆盖其抽象方法,这可能会不必要地增加您的代码及其复杂性。
作为一个框架,最需要考虑的是扩展性,MMCV 和 Pytorch-Lighting 都提出了自己的扩展方式,ignite 扩展方式非常简洁,不需要继承并覆写某些抽象方法,而是可以传入任意函数。这也是 ignite 不同于其他两个框架的特点,后面会重点介绍。
(1) 随时执行任意数量的你想要的扩展功能
# 1 注入自定义的事件处理器trainer.add_event_handler(Events.STARTED, lambda _: print("Start training"))# attach handler with args, kwargsmydata = [1, 2, 3, 4]logger = ...def on_training_ended(data):print(f"Training is ended. mydata={data}")# User can use variables from another scopelogger.info("Training is ended")# 2 注入自定义的事件处理器trainer.add_event_handler(Events.COMPLETED, on_training_ended, mydata)# call any number of functions on a single event# 3 注入自定义的事件处理器trainer.add_event_handler(Events.COMPLETED, lambda engine: print(engine.state.times))# 4 注入自定义的事件处理器def log_something(engine):print(engine.state.output)
上面例子写了几种 Ignite 支持的扩展开发方式,如果你已经熟悉了 MMCV 的 Hook 开发模式,那么上面例子含义非常容易理解。
(2) 内置事件过滤器
# run the validation every 5 epochsdef run_validation():# run validation# change some training variable once on 20th epochdef change_training_variable():# ...# Trigger handler with customly defined frequencydef log_gradients():# ...
事件过滤器是指基于过滤规则运行指定事件,例如每隔 20 个 epoch 验证一次,跳过前 n 次迭代等等。
(3) 一个事件并集操作共享多个 action
def run_validation():# ...
这是一种非常好的特性。
(4) 支持标准事件外的自定义事件
from ignite.engine import EventEnumclass BackpropEvents(EventEnum):BACKWARD_STARTED = 'backward_started'BACKWARD_COMPLETED = 'backward_completed'OPTIM_STEP_COMPLETED = 'optim_step_completed'def update(engine, batch):# ...loss = criterion(y_pred, y)engine.fire_event(BackpropEvents.BACKWARD_STARTED)loss.backward()engine.fire_event(BackpropEvents.BACKWARD_COMPLETED)optimizer.step()engine.fire_event(BackpropEvents.OPTIM_STEP_COMPLETED)# ...trainer = Engine(update)trainer.register_events(*BackpropEvents)def function_before_backprop(engine):# ...
2.2.3 开箱即用的评估指标
假设 Ignite 内置的事件无法满足我的需求则可以自定义事件,如上所示用户自定义了反向传播相关的事件,然后可以通过 register_events 注册从而生效。
目前已经支持了非常多评估指标,例如 Precision, Recall, Accuracy, Confusion Matrix, IoU 等等,当然用户也可以组合或者自定义新的评估指标
precision = Precision(average=False)recall = Recall(average=False)F1_per_class = (precision * recall * 2 / (precision + recall))F1_mean = F1_per_class.mean() # torch mean methodF1_mean.attach(engine, "F1")
3 从一个典型而简单的例子说起
如果直接讲 Ignite 整体设计原则,可能很多人依然觉得难以理解,故先以一个非常简单的分类任务例子说明常用用法,从这个用法中可以说明 Ignite 的大部分特性和设计巧妙之处。
完整代码来自:https://pytorch-ignite.ai/tutorials/beginner/01-getting-started/#complete-code
3.1 初始化必备对象实例
model = Net().to(device)data_transform = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])train_loader = DataLoader(MNIST(download=True, root=".", transform=data_transform, train=True), batch_size=128, shuffle=True)val_loader = DataLoader(MNIST(download=True, root=".", transform=data_transform, train=False), batch_size=256, shuffle=False)optimizer = torch.optim.RMSprop(model.parameters(), lr=0.005)criterion = nn.CrossEntropyLoss()
初始化模型、train loader、val loader、optimizer 和 loss 计算类等。
3.2 初始化训练引擎
trainer = create_supervised_trainer(model, optimizer, criterion, device)create_supervised_trainer 只是只是一个简单的帮助函数,内部实际上是初始化了一个训练 Engine,核心代码为:
def _update(engine: Engine, batch: Sequence[torch.Tensor]) -> Union[Any, Tuple[torch.Tensor]]:model.train()y = prepare_batch(batch, device=device, non_blocking=non_blocking)y_pred = model(x)loss = loss_fn(y_pred, y)if gradient_accumulation_steps > 1:loss = loss / gradient_accumulation_stepsloss.backward()if engine.state.iteration % gradient_accumulation_steps == 0:optimizer.step()optimizer.zero_grad()return output_transform(x, y, y_pred, loss)trainer = Engine(_update)
训练引擎在每一 step 时候都会调用 _update 函数进行推理、loss 计算和参数优化
3.3 定义评估流程
1 定义评估指标val_metrics = {"accuracy": Accuracy(),"loss": Loss(criterion)}# 2. 实例化两个新的 engine# 一个负责训练过程中的评估,一个负责验证过程中的评估train_evaluator = create_supervised_evaluator(model, metrics=val_metrics, device=device)val_evaluator = create_supervised_evaluator(model, metrics=val_metrics, device=device)log_interval = 100# 3 自定义 handler,并通过 on 装饰器注入到 enginedef log_training_loss(engine):print(f"Epoch[{engine.state.epoch}], Iter[{engine.state.iteration}] Loss: {engine.state.output:.2f}")def log_training_results(trainer):train_evaluator.run(train_loader)metrics = train_evaluator.state.metricsprint(f"Training Results - Epoch[{trainer.state.epoch}] Avg accuracy: {metrics['accuracy']:.2f} Avg loss: {metrics['loss']:.2f}")def log_validation_results(trainer):val_evaluator.run(val_loader)metrics = val_evaluator.state.metricsprint(f"Validation Results - Epoch[{trainer.state.epoch}] Avg accuracy: {metrics['accuracy']:.2f} Avg loss: {metrics['loss']:.2f}")def score_function(engine):return engine.state.metrics["accuracy"]# 4 模型保存 handlermodel_checkpoint = ModelCheckpoint("checkpoint",n_saved=2,filename_prefix="best",score_function=score_function,score_name="accuracy",global_step_transform=global_step_from_engine(trainer),)# 将模型保存 handler 注入到验证评估引擎中val_evaluator.add_event_handler(Events.COMPLETED, model_checkpoint, {"model": model})
不同于我们常规的理解,其 Engine 不是一个,而是 3 个,每个 Engine 负责一个流程,分别是训练 Engine、训练中评估的 Engine 和验证中评估 Engine。训练 Engine 是用于控制训练的循环过程,train_evaluator 是对 train dataloader 进行评估,评估的指标就是前面定义的 val_metrics,val_evaluator 是对 val dataloader 进行评估。三个 engine 相互独立,但是实际上是通过 train engine 组织起来的。
3.4 插入 logger handler
tb_logger = TensorboardLogger(log_dir="tb-logger")tb_logger.attach_output_handler(trainer,event_name=Events.ITERATION_COMPLETED(every=100),tag="training",output_transform=lambda loss: {"batch_loss": loss},)for tag, evaluator in [("training", train_evaluator), ("validation", val_evaluator)]:tb_logger.attach_output_handler(evaluator,event_name=Events.EPOCH_COMPLETED,tag=tag,metric_names="all",global_step_transform=global_step_from_engine(trainer),)
tensorboard 非常重要,可以将 tb_logger 插入到任意一个或者多个 Engine 中,例如上面代码是插入到了每个 Engine,插入过程是通过 attach_output_handler 实现的,而 event_name 表示触发时机。
3.5 开启训练
trainer.run(train_loader, max_epochs=5)tb_logger.close()
开启训练后,在特定时候会触发注入的事件 Handler,例如在每个 epoch 完成后,会进行训练集的评估和验证集的评估,并将所有评估指标保存到 Tensorboard 中。
通过上述的完整例子,大家应该有了第一直观感受,其将函数作为一等公民这一宗旨发挥到了最大化,除了 Engine 类外,其他功能都可以通过函数形式注册进去,实现丰富的扩展功能。
4 Ignite 整体分析
Ignite 主要要理解 Engine、State、Event 和 Handler 这 4 个概念,核心代码位于 ignite/engine/engine.py、ignite/engine/events.py,其关系如下所示:
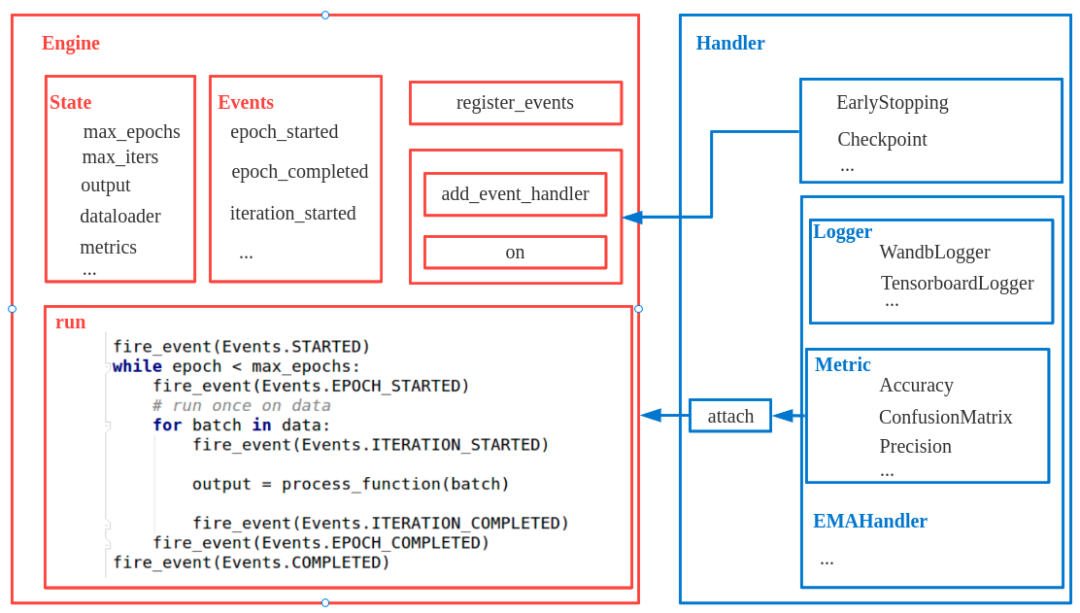
Engine 负责一个完整的循环流程,可以是一个训练流程,也可以是一个验证流程,整个流程的状态都是通过 State 对象统一维护,而 Events 管理了所有支持的触发事件,如果有自定义事件可以通过 register_events 接口实现,事件触发后具体的任务执行是通过 Handler 对象负责,Handler 可以认为是 Hook 的升级版本,其更加灵活好用,各种扩展功能都可以 Handler 实现,例如 logger、checkpoint、metric 等等。Engine 运行流程本质就是 for 循环,然后在特定点位触发事件,执行 Handler 任务。
4.1 Engine
Engine 是运行流程的核心,但是又非常简单,其核心流程如下:
while epoch < max_epochs:# run an epoch on datadata_iter = iter(data)while True:try:batch = next(data_iter)output = process_function(batch)iter_counter += 1except StopIteration:data_iter = iter(data)if iter_counter == epoch_length:break
可以看出就是一个典型的 for 循环,process_function 负责处理一个 epoch 的数据。一个典型的例子是:
def train_step(trainer, batch):model.train()optimizer.zero_grad()y = prepare_batch(batch)y_pred = model(x)loss = loss_fn(y_pred, y)loss.backward()optimizer.step()return loss.item()trainer = Engine(train_step) # process_functionmax_epochs=100)
用户自定义 train_step 函数,返回啥无所谓,都会直接存储到 trainer.state.output中,后续自己可以针对性处理,这也体现去其灵活的地方了。
def update(engine, batch):x, y = batchy_pred = model(inputs)loss = loss_fn(y_pred, y)optimizer.zero_grad()loss.backward()optimizer.step()return {'loss': loss.item(),'y_pred': y_pred,'y': y}trainer = Engine(update)def print_loss(engine):epoch = engine.state.epochloss = engine.state.output['loss']print (f'Epoch {epoch}: train_loss = {loss}')accuracy = Accuracy(output_transform=lambda x: [x['y_pred'], x['y']])accuracy.attach(trainer, 'acc')trainer.run(data, max_epochs=10)
同时允许用户手动设置 max_epoch 和 epoch_length,epoch_length 的应用场景可以是 debug 阶段,数据集过大,可以设置 epoch_length 来取其中一小部分,也可用于 dataset 是无限长的场景。
trainer.run(data, max_epochs=100, epoch_length=200)如果是 GAN 这种复杂场景,支持也非常容易:
model_1 = ...model_2 = ...# ...optimizer_1 = ...optimizer_2 = ...# ...criterion_1 = ...criterion_2 = ...# ...def train_step(trainer, batch):data_1 = batch["data_1"]data_2 = batch["data_2"]# ...model_1.train()optimizer_1.zero_grad()loss_1 = forward_pass(data_1, model_1, criterion_1)loss_1.backward()optimizer_1.step()# ...model_2.train()optimizer_2.zero_grad()loss_2 = forward_pass(data_2, model_2, criterion_2)loss_2.backward()optimizer_2.step()# ...# User can return any type of structure.return {"loss_1": loss_1,"loss_2": loss_2,# ...}trainer = Engine(train_step)trainer.run(data, max_epochs=100)
如果对 MMCV 比较了解,你可以认为一个 Engine 就是对应一个 Runner。
4.2 State
State 对象比较好理解,专门用于存储训练中所需的所有状态,实现训练过程和训练状态分离,便于管理。默认情况下有如下状态:
def __init__(self, **kwargs: Any) -> None:self.iteration = 0self.epoch = 0self.epoch_length = None # type: Optional[int]self.max_epochs = None # type: Optional[int]self.max_iters = None # type: Optional[int]self.output = None # type: Optional[int]self.batch = None # type: Optional[int]self.metrics = {} # type: Dict[str, Any]self.dataloader = None # type: Optional[Union[DataLoader, Iterable[Any]]]self.seed = None # type: Optional[int]self.times = {Events.EPOCH_COMPLETED.name: None,Events.COMPLETED.name: None,} # type: Dict[str, Optional[float]]for k, v in kwargs.items():setattr(self, k, v)
如果你自定义的事件中也有状态要保存,也可以通过 event_to_attr 实现。self.output 保存的就是 update 函数返回值。
4.3 Event
Event 和 Handler 是 Ignite 的核心,要掌握这个框架就必须理解这两个对象。Event 用于记录事件的触发时机,例如每个 epoch 后,每隔 2 个 epoch等等,Handler 是在事件触发后具体的执行器。
因为事件也分成很多类型,故作者也进行了区分:
Events,这个是最基本的事件记录器,典型的是 STARTED、EPOCH_STARTED、ITERATION_STARTED、ITERATION_COMPLETED 等
EventsList,这个是并集操作事件记录器,用于将多个事件堆叠
CallableEventWithFilter,这个是基类,用于提供基于过滤规则触发的事件
其触发的核心伪代码为:
fire_event(Events.STARTED)while epoch < max_epochs:fire_event(Events.EPOCH_STARTED)# run once on datafor batch in data:fire_event(Events.ITERATION_STARTED)output = process_function(batch)fire_event(Events.ITERATION_COMPLETED)fire_event(Events.EPOCH_COMPLETED)fire_event(Events.COMPLETED)
虽然有三种类型,但是对用户而言不要操心,因为内部会基于事件类型来确定应该用哪个。
@engine.on(Events.EPOCH_COMPLETED)events = Events.STARTED | Events.COMPLETED@engine.on(events)@engine.on(Events.ITERATION_COMPLETED(every=log_interval))
4.4 Handler
任何一个处理函数都必然要和对应的 Event 事件绑定,不然不知道何时触发。当然用户也可以自定义事件。
Handler 对应一个具体处理事件的 API,其可以是一个函数,可以是一个类方法,可以通过 on 装饰器或者 add_evevnt_hander 注册到引擎中,也可以自身的通过 attach 接口接入 Engine 中。Handler非常类似 Hook,但是这里更加宽泛,不像 Hook 必须是指定的方法名和固定的输入参数,其可以随意设置。
下面是一个最简单的 Handler 函数 log_training_loss
# 每隔 log_interval 且是迭代完成后触发,打印训练 lossdef log_training_loss(engine):print(f"Epoch[{engine.state.epoch}], Iter[{engine.state.iteration}] Loss: {engine.state.output:.2f}")
这个 Handler 通过装饰器 on 函数注入到 trainer 中。
# 保存模型val_evaluator.add_event_handler(Events.COMPLETED, model_checkpoint)
这个 Handler 是通过 Engine 自身的 add_event_handler 函数注入到 Engine 中。
# tb_logger 通过 attach 方法注入到 trainer 中tb_logger = TensorboardLogger(log_dir="tb-logger")tb_logger.attach_output_handler(trainer,event_name=Events.ITERATION_COMPLETED(every=100),tag="training",output_transform=lambda loss: {"batch_loss": loss},)
engine.add_event_handler(name, log_handler, self, name) 方法的。这个 Handler 是通过类本身的 attach 方法注入到 Engine 中,实际上 attach 方法内部也是调用了
除了上面这些比较简单的 Handler,作者还实现了各种各样的 Handler,都可以通过 on、add_event_handler 或者 attach 方式注入到 Engine 中,这种设计解耦性很好,容易维护和扩展。
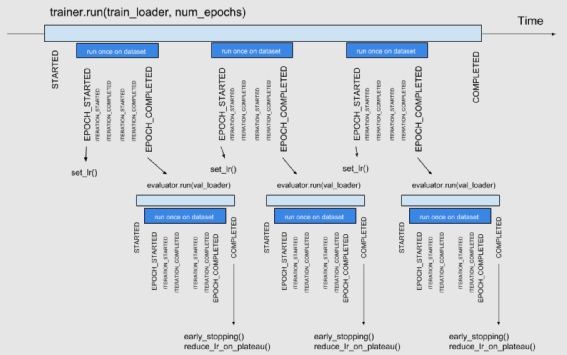
下面是一个典型的带有 EarlyStopping 和 reduce_lr_plateau handler 的训练流程图:
5 总结
整体来说,Ignite 属于一个小而精的框架,代码量非常少,实现优雅,学习起来非常顺畅。总之其优点可以归纳为:
代码简洁优雅,容易理解
设计了一套独特的扩展模式,解耦合性非常好
但是从目前来看缺点也比较明显:
Engine 做的事情过少,导致很大一部分功能都需要自定义 Handler 实现,自身要维护的代码比较多
整体功能过弱,暂时还无法和 Pytorch-Iighting 这种量级的功能相比,社区活跃度也相差很大,后面可以对 Pytorch-Iighting 这种大型复杂的框架进行整体性分析
写这篇文章的目的正如题目所言,主要是开阔下大家的视野,在设计自身代码的时候可以参考人家开源的高质量代码。当然如果你是重头写一个训练任务,那么尝试 Ignite 也是一种不错的选择。由于内容较多,时间匆忙,如果有不对的地方,可以联系我。
最后,如果你觉得本文对你有帮助,请给 MMCV 点赞
https://github.com/open-mmlab/mmcv
如果有任何疑问,可以直接知乎联系,知乎账号:深度眸
推荐阅读
超实用半监督目标检测 Soft Teacher 及 MMDetection 最强代码实践