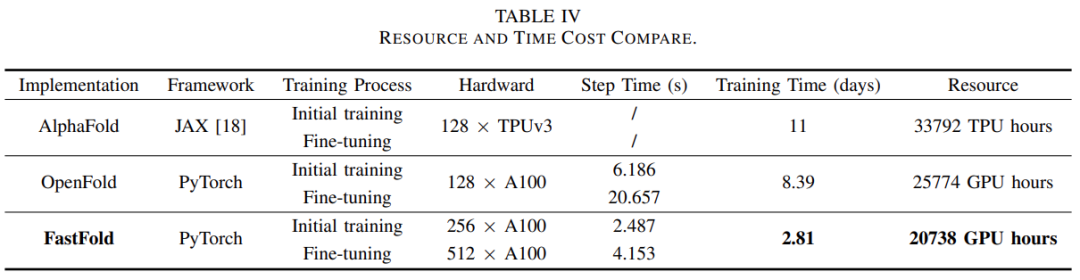
512块A100,AlphaFold训练时间从11天压缩至67小时
视学算法报道
编辑:小舟、蛋酱
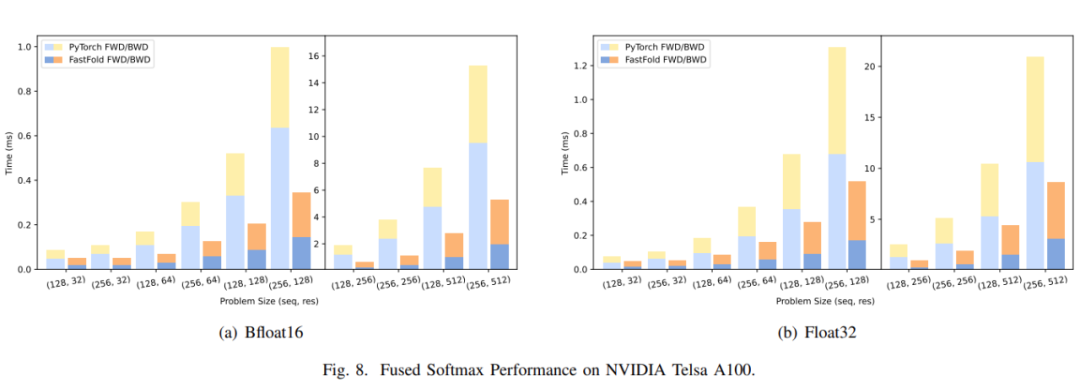
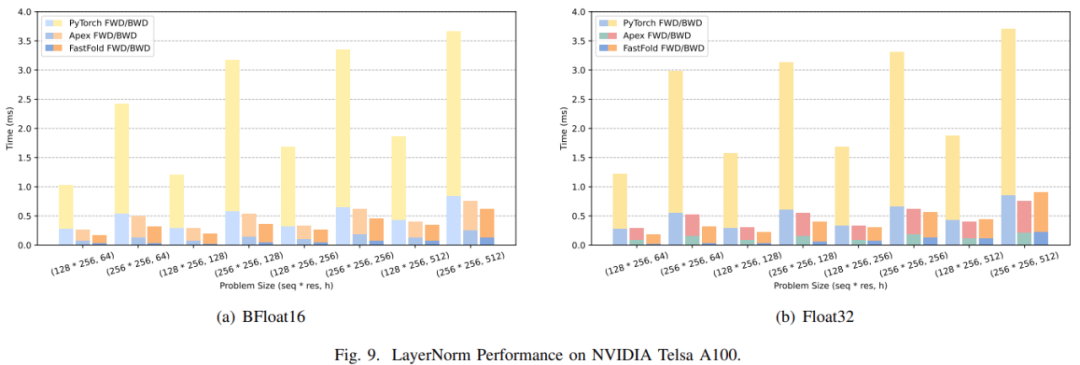
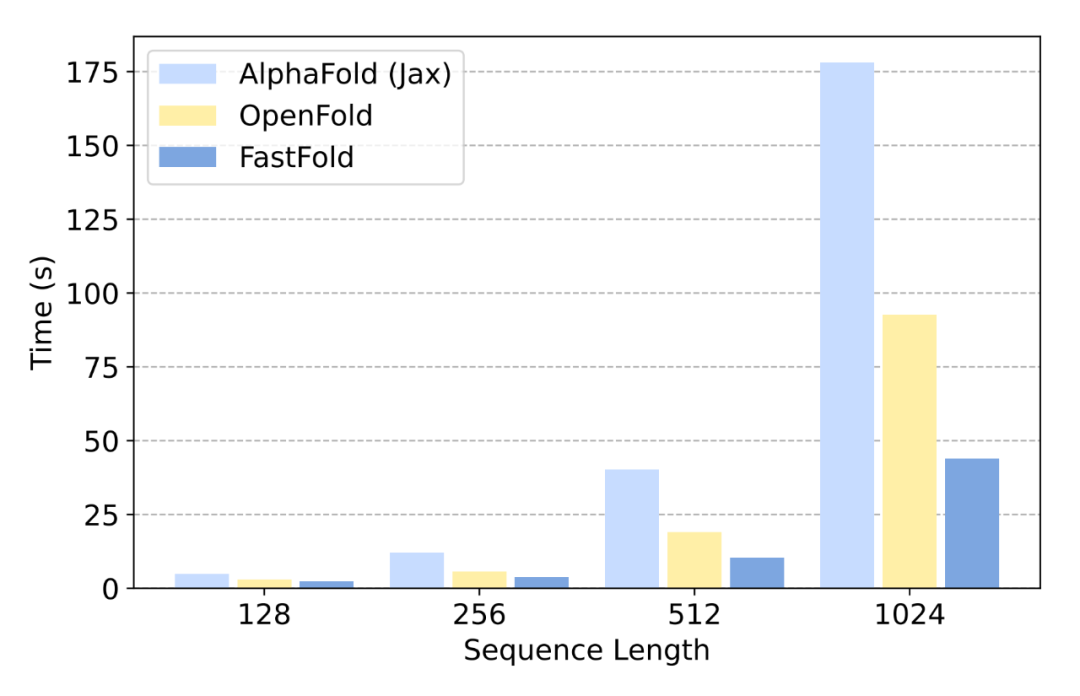
AlphaFold 虽好,但耗时且成本高,现在首个用于蛋白质结构预测模型的性能优化方案来了。

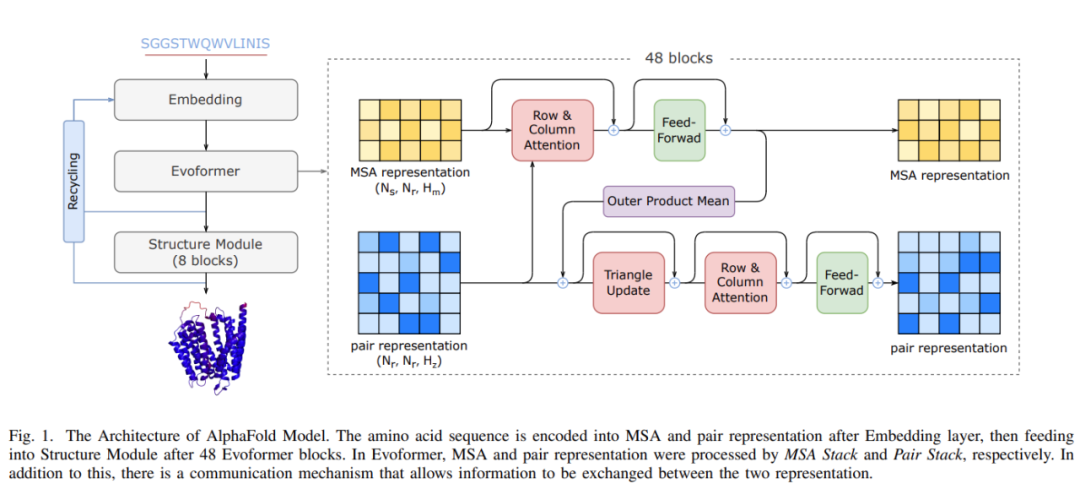
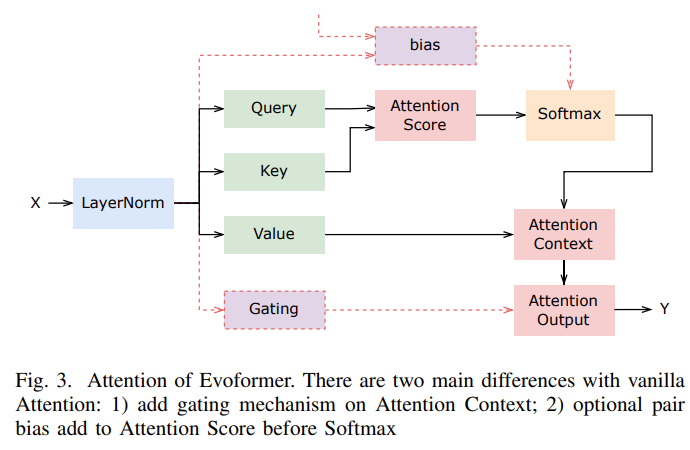
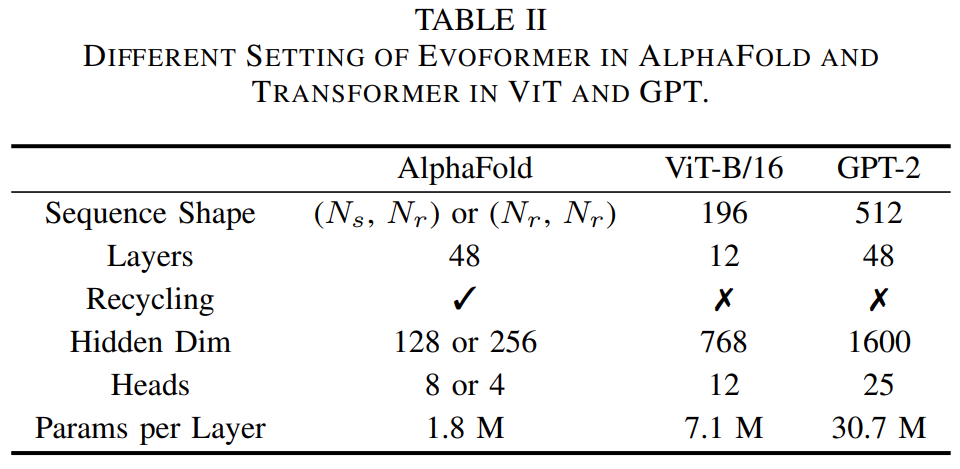
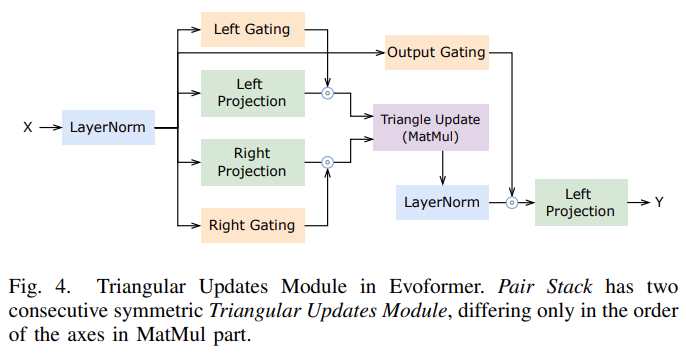
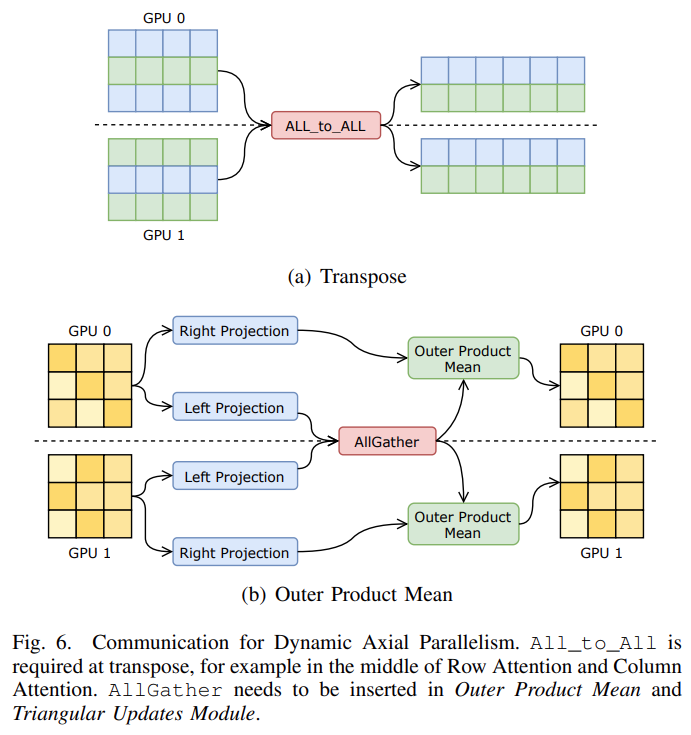
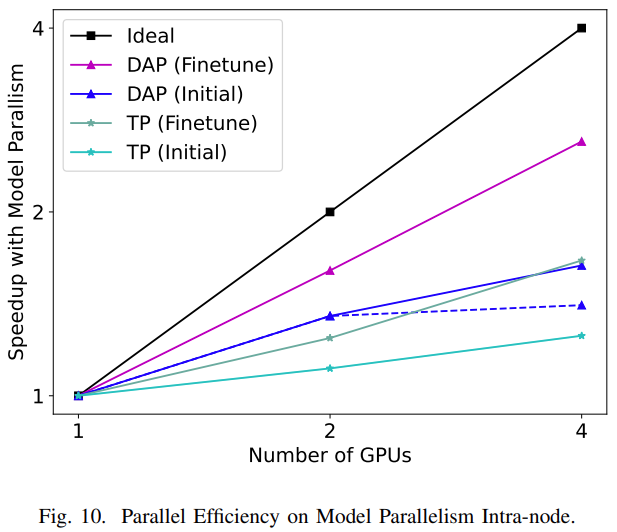
支持 Evoformer 中的所有计算模块;
所需的通信量比张量并行小得多;
显存消耗比张量并行低;
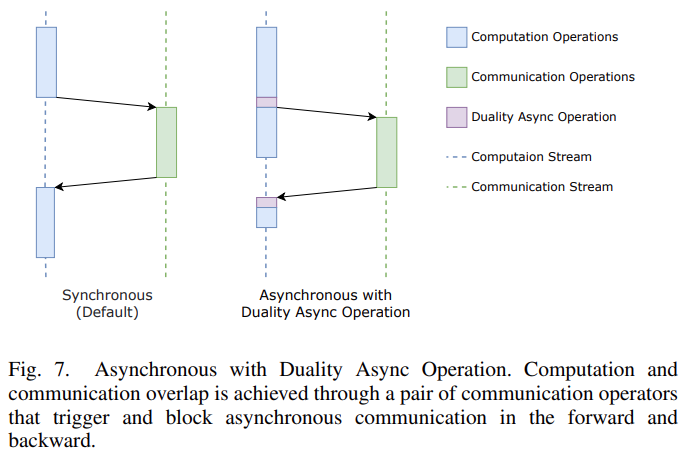
给通信优化提供了更多的空间,如计算通信重叠。

© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP视学算法报道
编辑:小舟、蛋酱
AlphaFold 虽好,但耗时且成本高,现在首个用于蛋白质结构预测模型的性能优化方案来了。
支持 Evoformer 中的所有计算模块;
所需的通信量比张量并行小得多;
显存消耗比张量并行低;
给通信优化提供了更多的空间,如计算通信重叠。
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!