
荣登Nature,时隔15年NumPy论文终发表!

新智元报道
新智元报道
来源:Nature
编辑:小智、QJP
【新智元导读】在人工智能时代,NumPy可谓是家喻户晓。它是 Python 中最常用的数组编程库,在物理学、化学、工程学、金融和经济学等多个领域的研究分析中发挥着重要作用。近日,NumPy团队在Nature上发布了论文,回顾了NumPy的「前世今生」。「2020创新之源大会将于9月22日在中关村软件园召开,详细信息见文末海报,欢迎报名!」

NumPy的发展历程
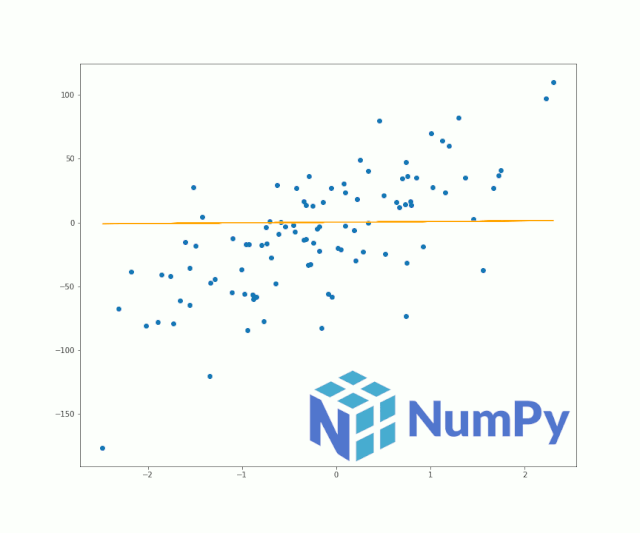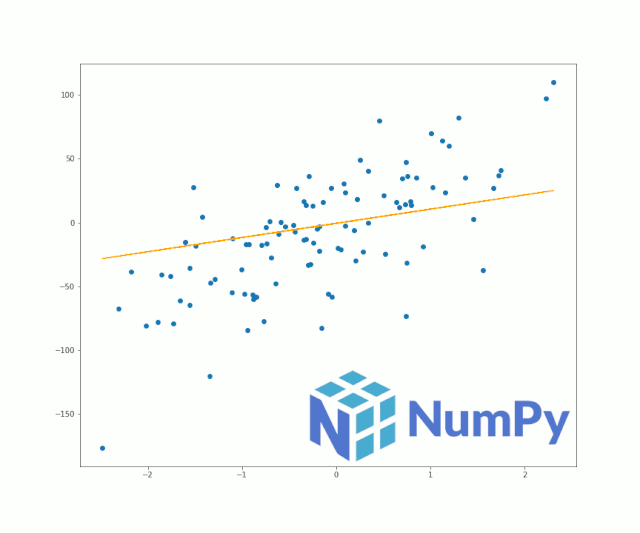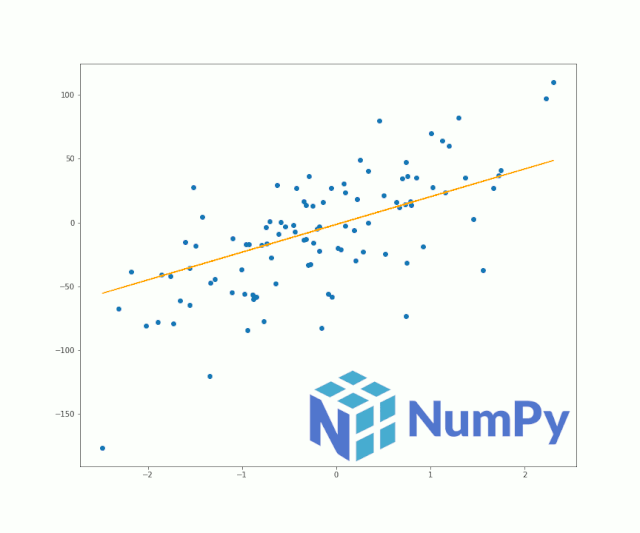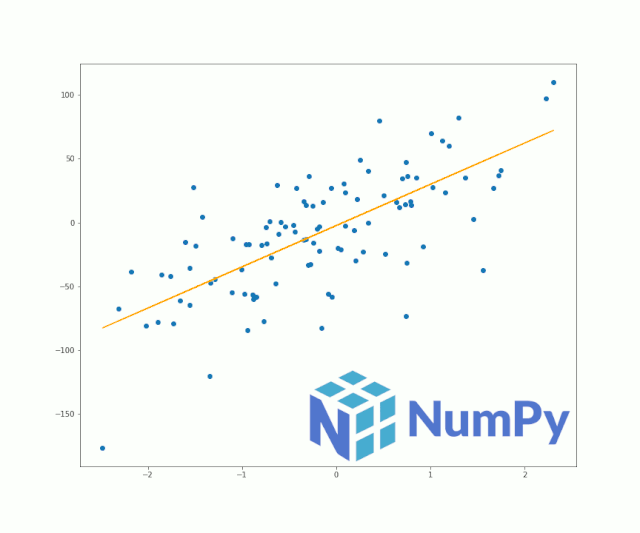
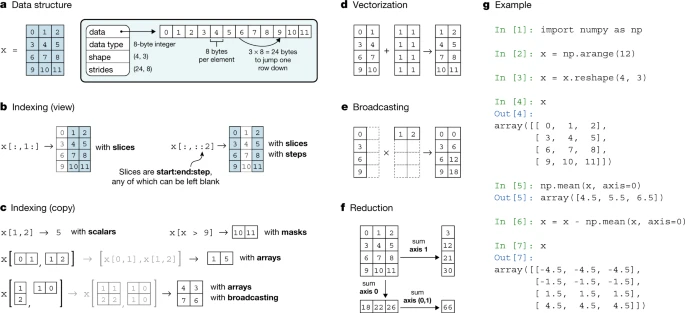
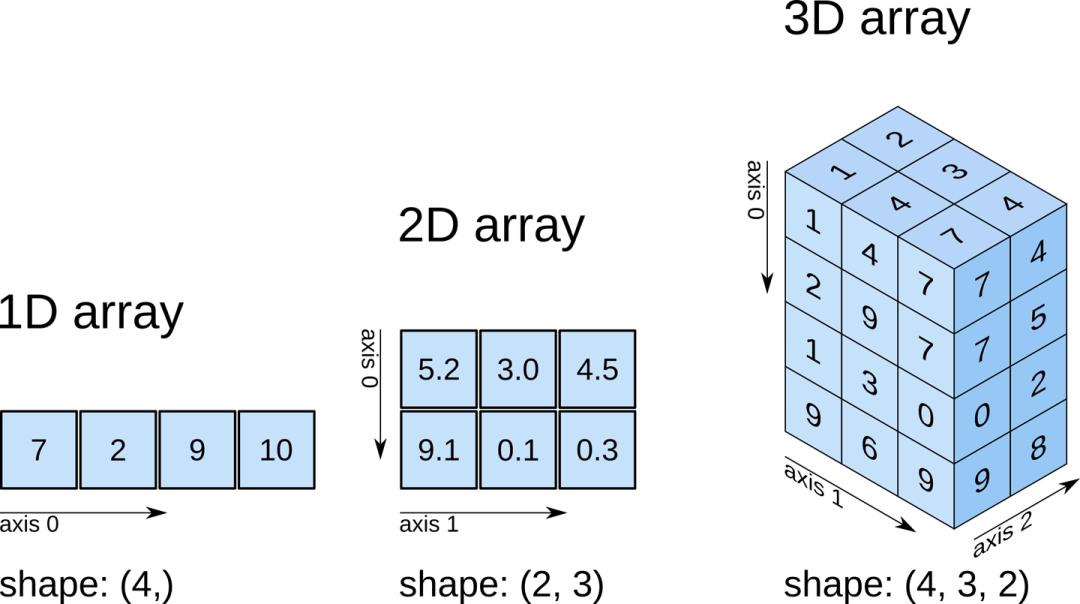
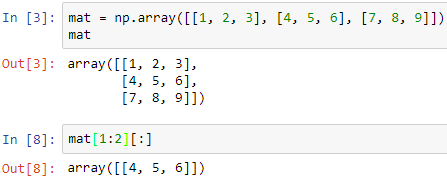
灵活的NumPy数组

科学的Python生态系统
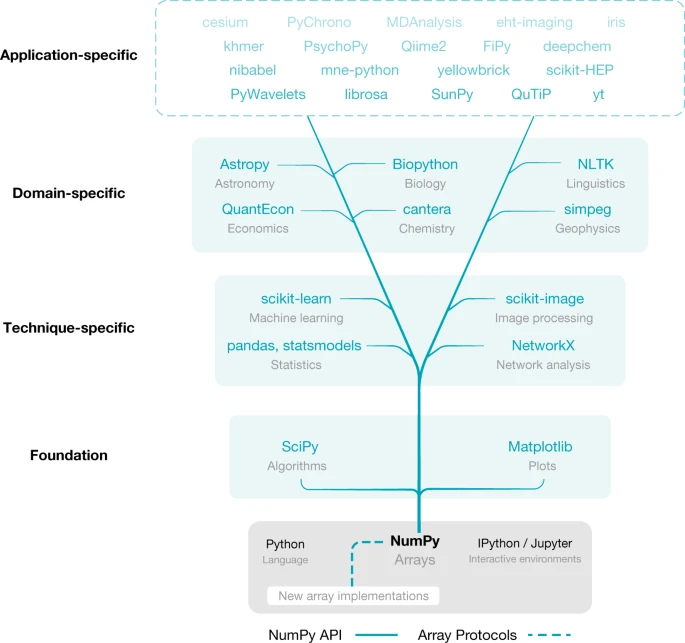

数组激增和互操作性

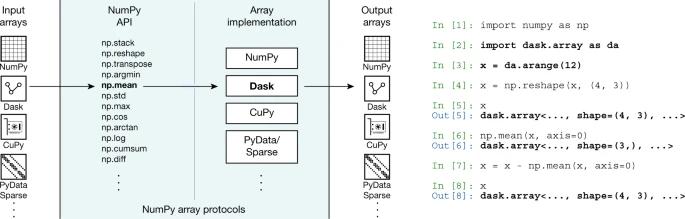 NumPy 的API和数组协议向生态系统提供了新的数组
NumPy 的API和数组协议向生态系统提供了新的数组讨论:NumPy也面临挑战
中关村软件园20周年,品牌活动“创新之源”大会再升级!
9月22日,2020创新之源大会 —“科技力量创变未来”在中关村软件园国际会议中心召开。大会由中关村软件园主办,中关村软件园孵化器、新智元、北京银行共同承办,邀请到清华大学副校长、北京量子信息科学研究院院长薛其坤院士,清华大学电子工程系主任、信息科学技术学院副院长汪玉,科大讯飞联合创始人、讯飞创投董事长徐景明,搜狗公司CEO王小川,网易集团副总裁、网易有道CEO周枫,达闼科技创始人兼CEO黄晓庆,浪潮信息副总裁、浪潮AI&HPC总经理刘军 ,腾讯自动驾驶业务中心总经理苏奎峰,新智元创始人兼CEO杨静等重磅嘉宾出席。
最新议程曝光,扫描二维码即刻报名,资格经审核后可免费参会!点击阅读原文,查看详细会议信息。

评论