来源:机器之心
NumPy 团队撰写了一篇综述文章,介绍 NumPy 的发展过程、主要特性和数组编程等。这篇文章现已发表在 Nature 上。
NumPy 是什么?它是大名鼎鼎的使用 Python 进行科学计算的基础软件包,是 Python 生态系统中数据分析、机器学习、科学计算的主力军,极大简化了向量与矩阵的操作处理。除了计算外,它还包括了:今日,NumPy 核心开发团队的论文终于在 Nature 上发表,详细介绍了使用 NumPy 的数组编程(Array programming)。这篇综述论文的发表距离 NumPy 诞生已经过去了 15 年。
论文地址:https://www.nature.com/articles/s41586-020-2649-2NumPy 官方团队在 Twitter 上简要概括了这篇论文的核心内容:NumPy 为数组编程提供了简明易懂、表达力强的高级 API,同时还考虑了维持快速运算的底层机制。NumPy 提供的数组编程基础和生态系统中的大量工具结合,形成了适合探索性数据分析的完美交互环境。NumPy 还包括增强与 PyTorch、Dask 和 JAX 等外部库互操作性的协议。基于这些特性,NumPy 为张量计算提供了标准的 API,成为 Python 中不同数组技术之间的核心协调机制。
接下来,我们来看这篇 NumPy 综述论文的详细内容。数组编程为访问、操纵和计算向量、矩阵和高维数组中的数据提供了功能强大、紧凑且表达力强的语法。NumPy 是 Python 语言的主要数组编程库,它在物理、化学、天文学、地球科学、生物学、心理学、材料科学、工程学、金融和经济学等领域的研究分析中都起着至关重要的作用。例如,在天文学中,NumPy 是发现引力波和黑洞首次成像的软件栈中的重要部分。这篇论文回顾了一些基本的数组概念,以及它们如何形成一种简单而强大的编程范式,使其能够用于组织、探索和分析科学数据。NumPy 是构建科学 Python 生态系统的基础。它的应用十分普遍,一些面向特殊需求受众的项目已经开发出自己的类 NumPy 接口和数组对象。由于其在 Python 生态系统中的核心地位,NumPy 越来越多地充当数组计算库之间的互操作层,并且和其 API 一起提供了灵活的框架,以支持未来十年的科学和工业分析。在 NumPy 之前,已经出现了两个 Python 数组包。Numeric 包开发于 20 世纪 90 年代中期,它提供了 Python 中的数组对象和 array-aware 函数。Numeric 是用 C 语言写的,并链接到线性代数的标准快速实现。其最早的应用之一是美国劳伦斯利弗莫尔国家实验室的惯性约束核聚变研究。为了处理来自哈勃太空望远镜的大型天文图像,Numeric 被重实现为 Numarray,它添加了对结构化数组、灵活 indexing、内存映射、字节序变体、更高效的内存使用以及更好的类型转换规则的支持。尽管 Numarray 与 Numeric 高度兼容,但这两个包之间的差异足以将社区开发者分为两类。而 2005 年,NumPy 的出现完美地统一了这两个包,它将 Numarray 的功能和 Numeric 的 small-array 性能及其丰富的 C API 结合起来。如今,15 年过去了,NumPy 几乎支持所有进行科学和数值计算的 Python 库(包括 SciPy、Matplotlib、pandas、scikit-learn 和 scikit-image)。NumPy 是一个社区开发的开源库,它提供了多维 Python 数组对象以及对其进行操作的 array-aware 函数。由于其固有的简洁性,事实上 NumPy 数组已经成为 Python 中数组数据的交换格式。NumPy 使用 CPU 对内存内(in-memory)数组进行操作。为了利用现代的专用存储和硬件,最近已经扩展出一系列 Python 数组包。与 Numarray–Numeric 之间存在较大差异的情况不同,现在的这些新库很难在社区开发者中引起分歧,因为它们都是建立在 NumPy 之上的。但是,为了使社区能够使用新的探索性技术,NumPy 正在过渡为核心协调机制,该机制规划了良好定义的数组编程 API,并在合适的时候将其分发给专门的数组实现。NumPy 数组是一种能够高效存储和访问多维数组的数据结构,支持广泛类型的科学计算。NumPy 数组包括指针和用于解释存储数据的元数据,即 data type(数据类型)、shape(形状)和 strides(步幅),参见下图 1a。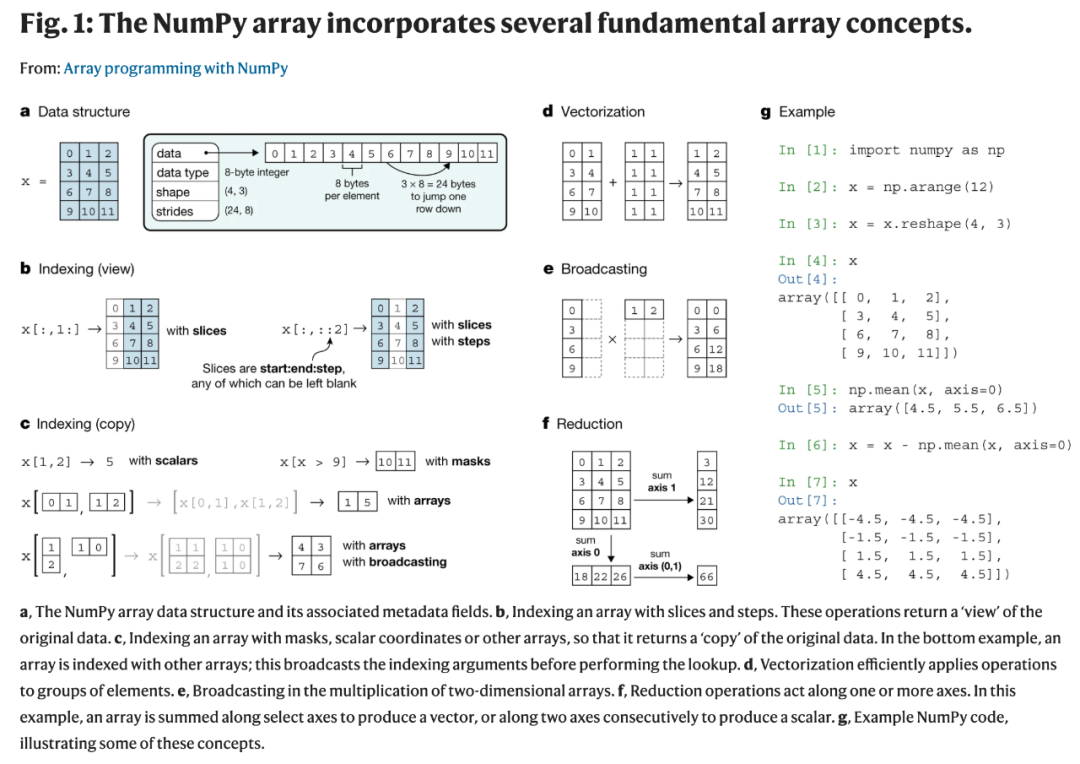
数据类型描述了数组中存储元素的本质。一个数组只有一个数据类型,数组中的每个元素在内存中占用的字节数是一样的。数据类型包括实数、复数、字符串、timestamp 和指针等。数组的形状决定了每个轴上的元素数量,轴的数量即为数组的维数。例如,数字向量可存储为形状为 N 的一维数组,而彩色视频是形状为 (T, M, N, 3) 的四维数组。步幅是解释计算机内存的必要组件,它可以线性地存储元素。步幅描述了在内存中逐行逐列移动时所需的字节数。例如,形状为 (4, 3) 的二维浮点数数组,它其中的每个元素均在内存中占用 8 个字节数。要想在连续列之间移动,我们需要在内存中前进 8 个字节数,要想到达下一行,则需要前进 3 × 8 = 24 个字节数。因此该数组的步幅为 (24, 8)。NumPy 可以用 C 或 Fortran 的内存顺序存储数组,沿着行或列遍历。这使得使用这些语言写的外部库可以直接访问内存中的 NumPy 数组数据。用户使用「indexing」(访问子数组或单个元素)、「operators」(各种运算符)和「array-aware function」与 NumPy 数组进行交互。它们为 NumPy 数组编程提供了简明易懂、表达力强的高级 API,同时还考虑了维持快速运算的底层机制。对数组执行 indexing 将返回单个元素、子数组或满足特定条件的元素(参见上图 1b)。数组甚至还可以用其他数组进行 indexing(参加图 1c)。返回子数组的 indexing 还可以返回原始数组的「view」,以便在两个数组之间共享数据。这就为内存有限的情况下基于数组数据子集进行运算提供了一种强大的方式。为了补充数组语法,NumPy 还包括对数组执行向量化计算的函数,包括 arithmetic、statistics 和 trigonometry(参见图 1d)。向量化计算基于整个数组运行而不是其中的单个元素,这对于数组编程而言是必要的。这意味着,在 C 等语言中需要几十行才能表达的运算在这里只需一个清晰的 Python 表达式即可实现。这就带来了简洁的代码,并使得用户不必关注分析细节,同时 NumPy 以接近最优的方式循环遍历数组元素。对两个形状相同的数组执行向量化计算(如加法)时,接下来会发生什么是很明确的。而「broadcasting」机制允许 NumPy 处理维度不同的数组之间的运算,例如向数组添加一个标量值。broadcasting 还能泛化至更复杂的示例,如缩放数组的每一列或生成坐标网格。在 broadcasting 中,单个或两个数组可以重叠(没有从内存中复制任何数据),使得 operands 的形状匹配(参见图 1d)。其他 array-aware function(如加、求平均值、求最大值)都是执行逐元素的「reduction」,累积单个数组的一个、多个或所有轴上的结果。例如,将一个 n 维数组与 d 个轴进行累加,得到维度为 n − d 的数组(参见图 1f)。NumPy 还包含可以创建、reshaping、concatenating 和 padding 数组,执行数据排序和计数,读取和写入文件的 array-aware function。这为生成伪随机数提供了大量支持,它还可以使用 OpenBLAS 或 Intel MKL 等后端执行加速线性代数。总之,内存内的数组表示、紧密贴近数学的语法和多种 array-aware function 共同构成了生产力强、表达力强的数组编程语言。Python 是一个开源、通用的解释型编程语言,非常适合数据清洗、与 web 资源交互和解析文本之类的标准编程任务。添加快速数组操作和线性代数能够让科学家在一种编程语言中完成所有的工作。尽管 NumPy 不是 Python 标准库的一部分,但它也从与 Python 开发者的良好关系中受益。在过去这些年中,Python 语言已经加入了一些新的功能和特殊的语法,以便 NumPy 具备更加简洁和易于阅读的数组表示法。但是,由于 NumPy 不是 Python 标准库的一部分,所以它能够规定自己的发布策略和开发模式。从发展史、开发和应用的角度来看,SciPy 和 Matplotlib 与 NumPy 联系紧密。SciPy 为科学计算提供了基础算法,包括数学、科学和工程程序。Matplotlib 生成可发表品质的图表和可视化文件。NumPy、SciPy 和 Matplotlib 的结合,再加上 IPython、Jupyter 这类高级交互环境,为 Python 中的数组编程提供了坚实的基础。如图 2 所示,科学 Python 生态系统建立在上述基础之上,它提供了多种广泛应用的专有技术库,而这又是众多领域特定项目的基础。NumPy 是这一 array-aware 库生态系统的基础,它设置了文档标准、提供了数组测试基础结构,并增加了对 Fortran 等编译器的构建支持。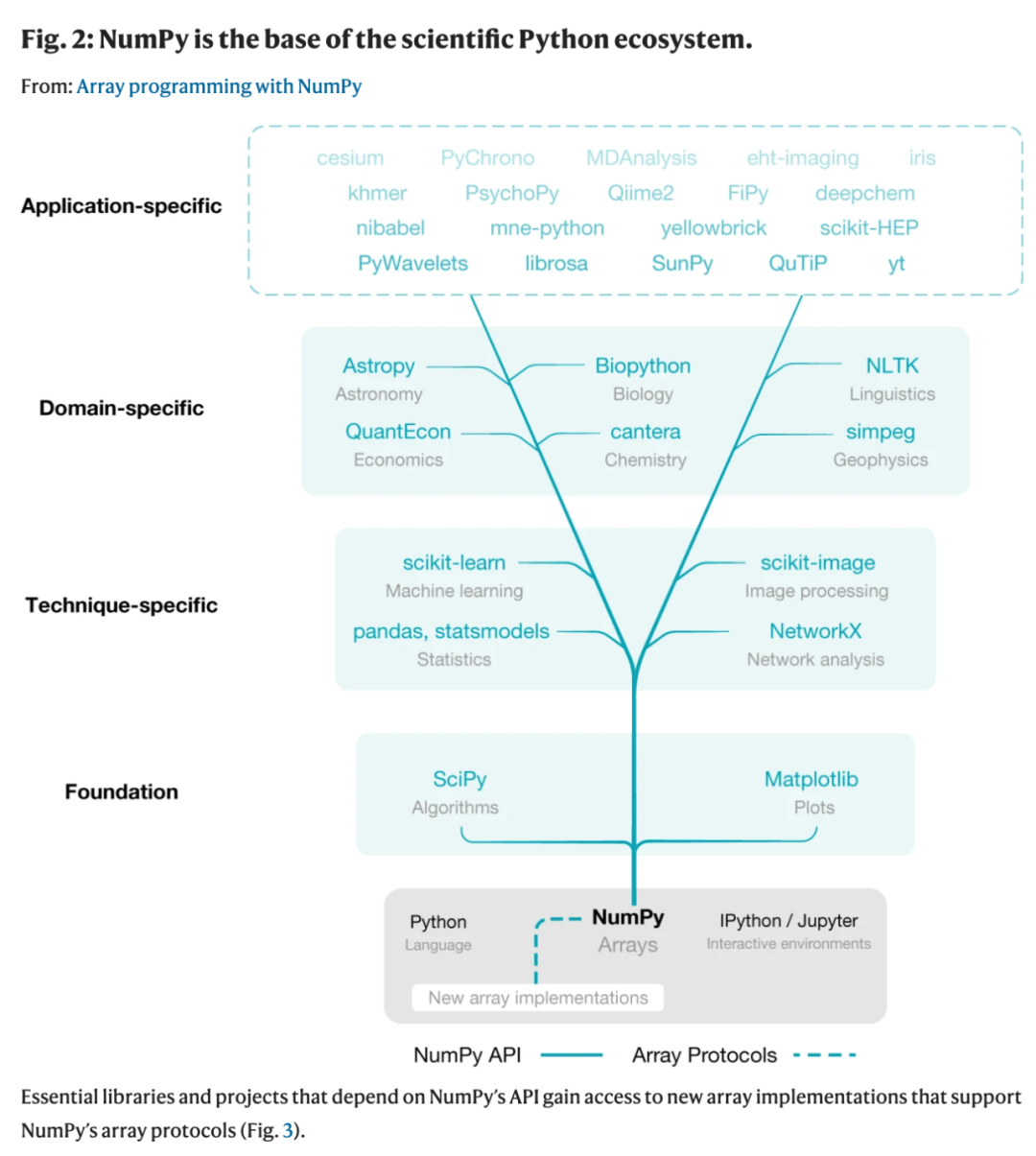
图 2:NumPy 是科学 Python 生态系统的基础。很多研究团队设计出大型、复杂的科学库,这些库为 Python 生态系统增添了特定于具体应用的功能。例如,由事件视界望远镜(Event Horizon Telescope, EHT)合作项目开发的 eht-imaging 库依赖科学 Python 生态系统的很多低级组件。而 EHT 合作项目利用该库捕获了黑洞的首张图像。在 eht-imaging 库中,NumPy 数组在流程链的每一步存储和操纵数值数据。基于数组编程创建的交互式环境及其周边的工具生态系统(IPython 或 Jupyter 内部)完美适用于探索性数据分析。用户可以流畅地检查、操纵和可视化他们的数据,并快速迭代以改善编程语句。然后,将这些语句拼接入命令式或函数式程序,或包含计算和叙述的 notebook。超出探索性研究的科学计算通常在文本编辑器或 Spyder 等集成开发环境(IDE)中完成。这一丰富和高产的环境使 Python 在科学研究界流行开来。为了给探索性研究和快速原型提供补充支持,NumPy 形成了使用经过时间检验的软件工程实践来提升协作、减少误差的文化。这种文化不仅获得了项目领导者的采纳,而且还被传授给初学者。NumPy 团队很早就采用分布式版本控制和代码审查机制来改善代码协同,并使用持续测试对 NumPy 的每个提议更改运行大量自动化测试。这种使用最佳实践来制作可信赖科学软件的文化已经被基于 NumPy 构建的生态系统所采用。例如,在近期英国皇家天文学会授予 Astropy 的一项奖项中表示:「Astropy 项目为数百名初级科学家提供了专业水平的软件开发实践,包括版本控制使用、单元测试、代码审查和问题追踪程序等。这对于现代研究人员而言是一项重要的技能组合,但物理或天文学专业的正规大学教育却常常忽略这一点。」社区成员通过课程和研讨会来弥补正规教育中的这一缺失。近来数据科学、机器学习和人工智能的快速发展进一步大幅提升了 Python 的科学使用。Python 的重要应用,如 eht-imaging 库,现已存在于自然和社会科学的几乎每个学科之中。这些工具已经成为很多领域主要的软件环境。大学课程、新手培训营和暑期班通常教授 NumPy 及其生态系统,它们也成为世界各地社区会议和研讨会的焦点。NumPy 和它的 API 已经无处不在了。NumPy 在 CPU 上提供了内存内、多维和均匀键入(即单一指向和跨步的)的数组。NumPy 可以在嵌入式设备和世界上最大的超级计算机等机器上运行,其性能接近编译语言。在大多数情况下,NumPy 解决了绝大部分的数组计算用例。但是现在,科学数据集通常超出单个机器的存储容量,并且可以在多个机器或云上存储。此外,近来深度学习和人工智能应用的加速需求已经促生了专用加速器硬件,包括 GPU、TPU 和 FPGA。目前,由于 NumPy 具有的内存内数据模型,它无法直接使用这类存储和专用硬件。然而,GPU、TPU 和 FPGA 的分布式数据和并行执行能够很好地映射到数组编程范式,所以可用的现代硬件架构与利用它们的计算能力所必需的工具之间存在着差距。社区为弥补这一差距做出的努力使得新的数组实现激增。例如,每个深度学习框架都创建了自己的数组。PyTorch、TensorFlow、Apache MXNet 和 JAX 数组都有能力以分布式方式在 CPU 和 GPU 上运行,其中使用惰性计算(lazy evaluation)实现额外性能优化。SciPy 和 PyData/Sparse 都提供有稀疏数组,这些数组通常包含很少的非零值,并只在内存中存储以提升效率。此外,还有一些项目在 NumPy 数组上构建作为数据容器,并扩展相应功能。Dask 通过这种方式使分布式数组成为可能,而标记数组是通过 xarray 实现的。这类库常常模仿 NumPy API,以降低初学者准入门槛,并为更广泛的社区提供稳定的数组编程接口。这反过来也会阻止一些破坏性分立(disruptive schism),如 Numeric 和 Numarray 之间的差异。但是探索使用数组的新方法从本质上讲是试验性的,事实上,Theano 和 Caffe 等一些有前途的库已经停止了开发。每当用户决定尝试一项新技术时,他们必须更改 import 语句,并确保新库能够实现他们当前使用的所有 NumPy API 部件。在理想状态下,用户可以通过 NumPy 函数或语义在专用数组上进行操作,这样他们可以编写一次代码,然后从 NumPy 数组、GPU 数组、分布式数组以及其他数组之间的切换中获益。为了支持外部数组对象之间的数组操作,NumPy 增加了一项充当核心协调机制的功能,并提供指定的 API,具体如上图 2 所示。为了促进这种互操作性,NumPy 提供了允许专用数组传递给 NumPy 函数的「协议」,具体如下图 3 所示。反过来,NumPy 根据需要将操作分派给原始库。超过 400 个最流行的 NumPy 函数得到了支持。该协议通过 Dask、CuPy、xarray 和 PyData/Sparse 等广泛使用的库来实现。得益于这些进展,用户现在可以使用 Dask 将自己的计算从单个机器扩展至多个系统。该协议允许用户通过 Dask 数组中嵌入的 CuPy 数组等,在分布式多 GPU 系统上大规模地重新部署 NumPy 代码。使用 NumPy 的高级 API,用户可以在具有数百万个核的多系统上利用高度并行化的代码执行,并且需要的代码更改最少。如下图 3 所示,NumPy 的 API 和数组协议向生态系统提供了新的数组: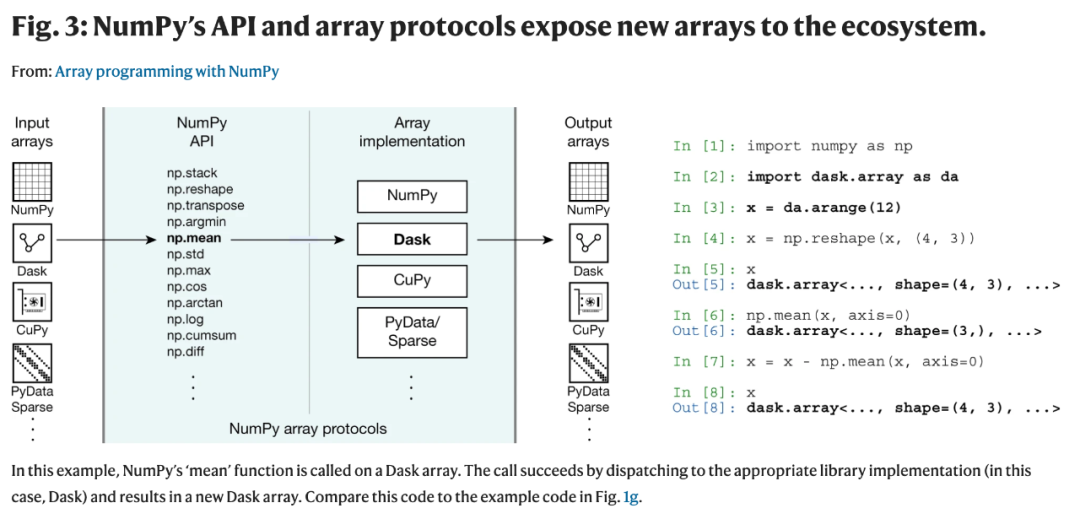
现在,这些数组协议是 NumPy 的主要特征,它们的重要性预计也会越来越大。NumPy 开发者(很多也是这篇文章的作者)迭代地改善和增加协议设计,以改进实用性和简化应用方式。论文最后对 NumPy 的现状和未来进行了总结和展望:在未来十年中,NumPy 开发者将面临多项挑战。新设备将出现,现有的专用硬件将面临摩尔定律的收益递减,数据科学从业者将越来越多,类型也更加广泛。而他们中的大部分将使用 NumPy。随着光片显微镜和大型综合巡天望远镜(LSST)等设备和仪器的采用,科学数据的规模将持续扩大。新一代语言、解释器和编译器,如 Rust、Julia 和 LLVM,将创造出新的概念和数据结构。
-END-
推荐语
向大家推荐一个特别入门的零基础Python人工智能公开课
Python入门、零基础搞定毕业设计、最简单的人工智能大数据经典算法,极其简单好懂,每节课程都有干货案例。
课程大纲
观看地址
https://www.icourse163.org/course/CUEB-1450000234
https://www.bilibili.com/video/BV12p4y1X7JS/
课件下载
恋习Python关注恋习Python,Python都好练
好文章,我在看❤️
