
NumPy 论文登上了 Nature!

剧照 | 《小妇人》
机器之心报道
NumPy 团队撰写了一篇综述文章,介绍 NumPy 的发展过程、主要特性和数组编程等。这篇文章现已发表在 Nature 上。
功能强大的 N 维数组对象。
精密广播功能函数。
集成 C/C++ 和 Fortran 代码的工具。
强大的线性代数、傅立叶变换和随机数功能
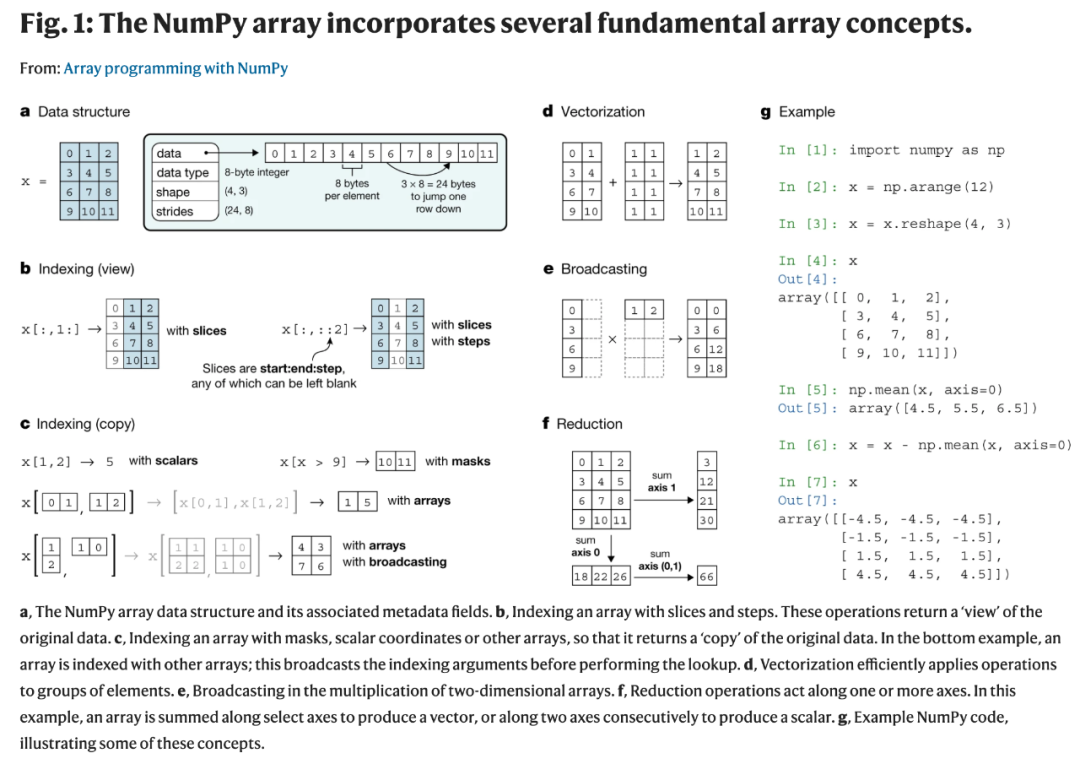
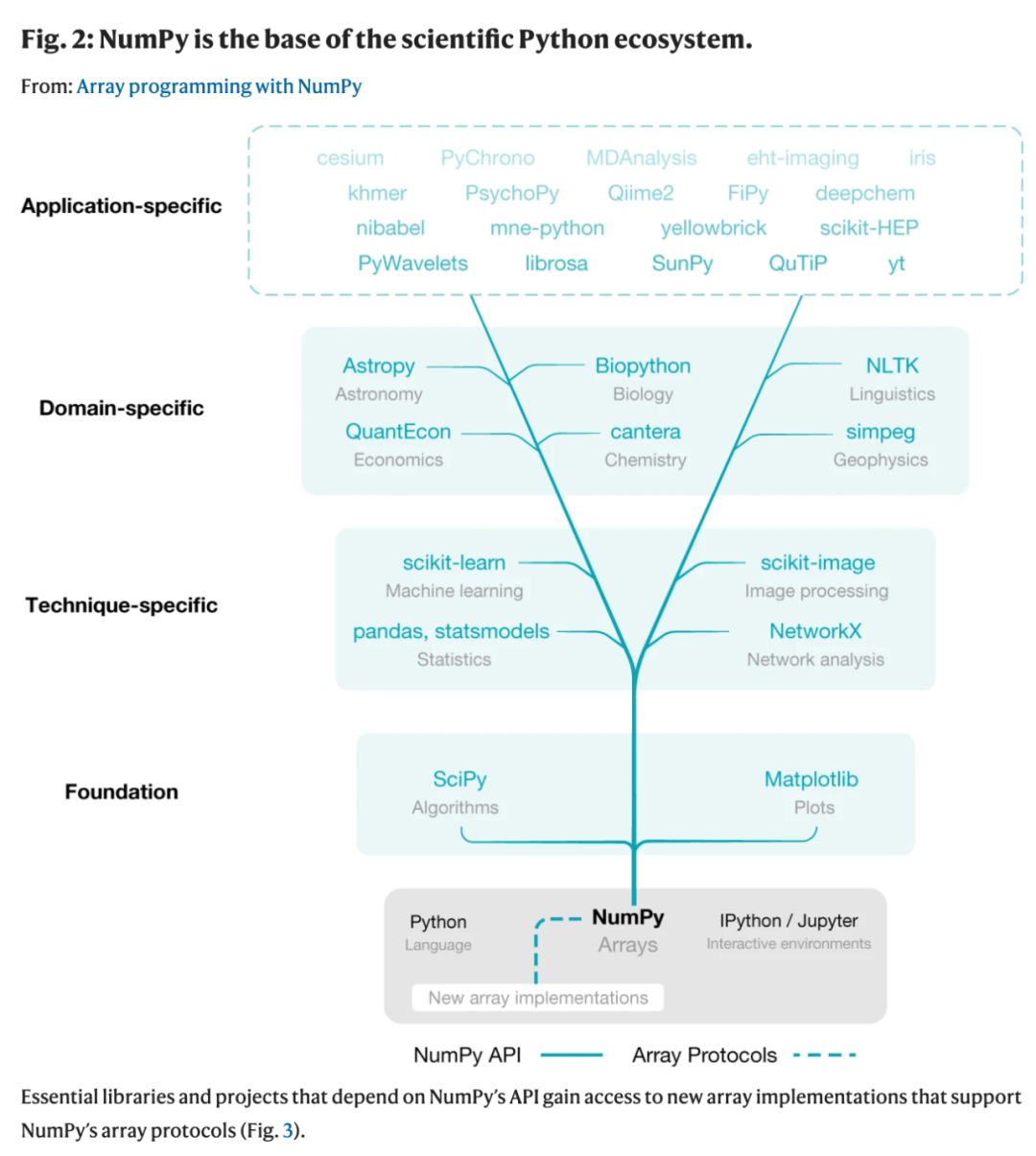
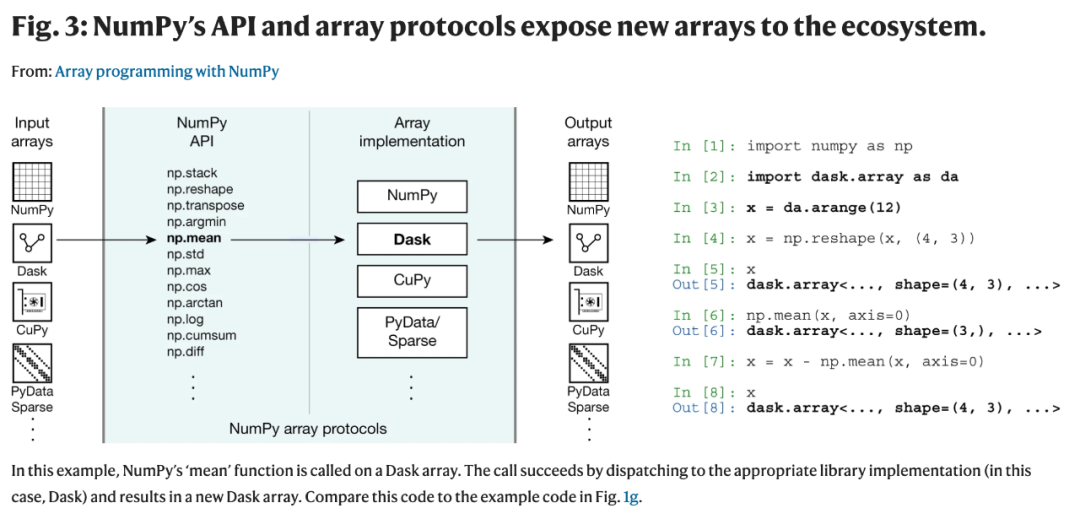
NumPy 为数组编程提供了简明易懂、表达力强的高级 API,同时还考虑了维持快速运算的底层机制。 NumPy 提供的数组编程基础和生态系统中的大量工具结合,形成了适合探索性数据分析的完美交互环境。NumPy 还包括增强与 PyTorch、Dask 和 JAX 等外部库互操作性的协议。 基于这些特性,NumPy 为张量计算提供了标准的 API,成为 Python 中不同数组技术之间的核心协调机制。

优质文章,推荐阅读:

评论