
汇总 | 深度学习中图像语义分割基准数据集详解
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

汇总图像语义分割那些质量最好的数据集与常用benchmark数据集
图像语义分割是计算机视觉最经典的任务之一,早期的图像分割主要有以下几种实现方法。
基于像素分布的分割算法:KMeans、Fuzzy C Means、 GMM、MeanShift
基于图像拓扑结构的分割算法:分水岭填充、轮廓边缘分析
基于能量最大化的分割方法:图割
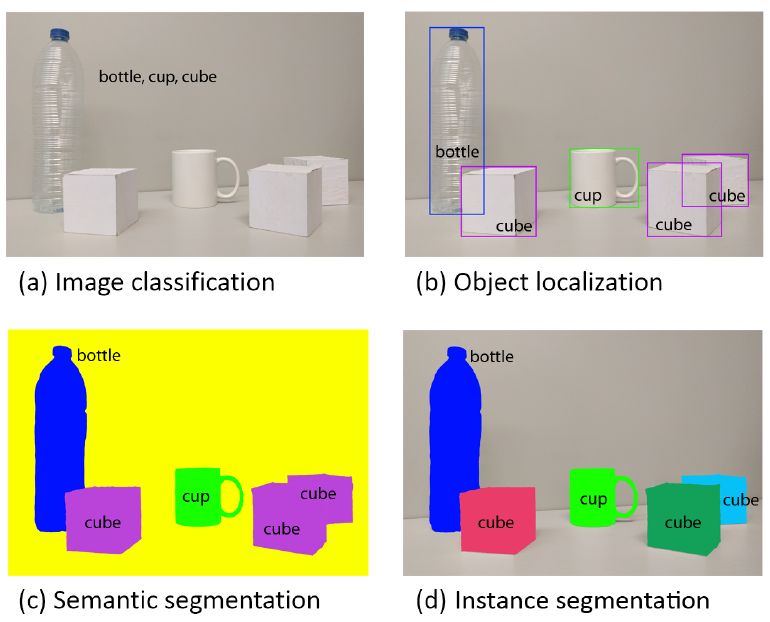
但是随着深度学习的兴趣,最近几年传统的图像分割方法已经很少被人提起,现在开始学习图像分割的都是基于深度学习的各种模型实现,这其中模型的训练需要大量的数据,所以想要了解图像分割,首先需要了解图像分割那些质量最好的各种数据集。这些数据集有的作为benchmark 可以很公平的比较各种语义分割模型的性能与精度,评价一个模型的好坏。
这些数据集的标注多数都是基于像素级别的标签,也有的是基于点级别的标签。语义分割针对不同的任务,数据集分为如下三类:
2D RGB图像数据集
2.5D或者RGB-D的深度图像数据集
纯立体或者3D图像数据集
这些数据集总的列表如下:
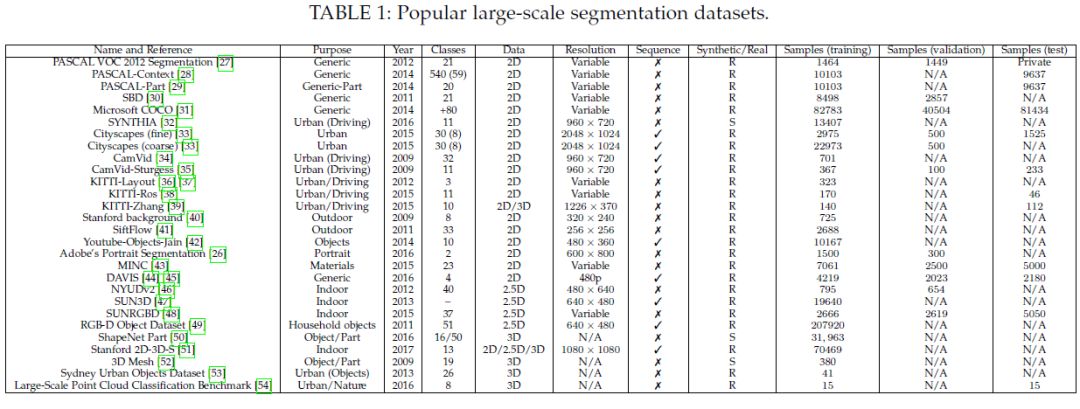
图像语义分割多数都是针对二维的图像进行过,所以2D 数据集是数据集类别最多的,这里2D包括RGB彩色与灰度图像。
PASCAL Visual Object Classes(VOC)数据集
PASCAL VOC数据集支持五种不同的视觉任务训练包括图像分类、对象检测、图像分割、行为分类、人体Layout。分割是预测图像种每个像素属于哪个类别的任务,VOC数据集总计有21个类别(包括背景)。分割数据集被分为训练与测试两个子集,分别有1464与1449张图像。
PASCAL Context数据集
它是PASCAL VOC 2010数据集的扩展,包含10103张基于像素级别标注的训练图像,它包含总数540个类别,其中59个类别是常见类别,被大量标注,整个类别图像的数据符合幂次法则分布。
SBD (Semantic Boundaries Dataset)数据集
它的数据来自那些在PASCAL VOC中没有被语义分割标注的图像数据,总计有11355张图像来自PASCAL VOC 2011,实现了两个层级的标注分布是种类/类别与实例对象分割,其中8498张为训练集,2857张为测试集。
COCO(Microsoft Common Objects in Context)数据集
是微软发布的图像分类、对象检测、实例分割、图像语义的大规模数据集,其中图像分割部分有80分类,82783张训练图像、40504张验证图像,测试集好感80000张图像,而且测试集本身被分为四种不同测试数据,分别应对开发测试、标准测试、评估挑战、过拟合测试。
Cityscapes
一个大规模的城市道路与交通语义分割数据集,8大类别30种类的像素级别标注,数据集包含5000张精准标注的图像,20000张标注图像。数据收集来自50多个城市,前后花了几个月的时间,对这个时间线与天气下的场景都进行图像采集,最初原始的数据是视频方式,通过人工选择视频帧,得到最终的数据。整个数据集支持三个级别的分割性能评估
像素级别分割
实例级别分割
全景级别分割
其中数据采集的城市地图如下:

精准标注的图像

粗糙标注的图像

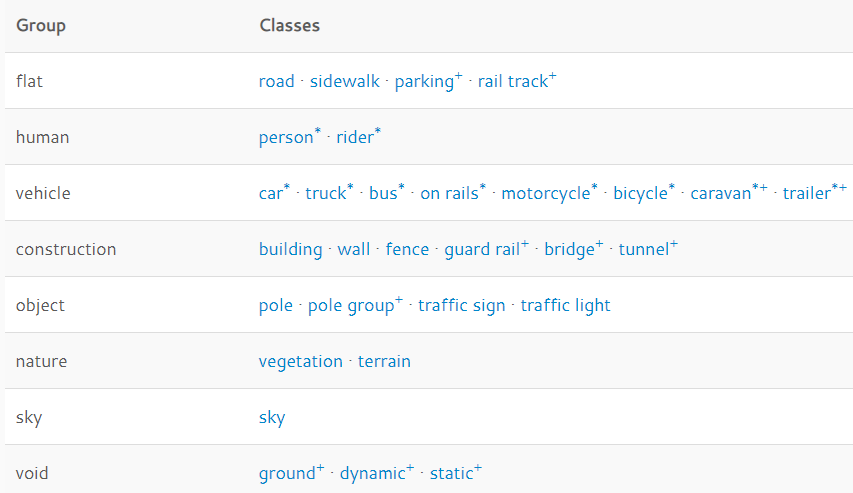
所有数据组与类别列表如下
CamVid
是来自剑桥的道路与驾驶场景图像分割数据集,图像数据来自视频帧提取,原始分辨率大小为960x720,包括32个类别。分为367张训练图像,100张验证图像,233张测试图像。
KITTI
自动驾驶最常用的一个数据集,数据采集来自高分辨RGB、灰度立体相机,3D激光扫描等。但是数据集本身不包括标注的ground truth分割(一般人用不起),网上有很多研究机构部分标注的数据集可以下载!
Youtube-Objects
数据收集来自Youtube视频网站,分类是PASCAL VOC其中10个子分类包括(aeroplane, bird, boat, car, cat, cow, dog, horse, motorbike, and train) ,数据集没有被标注,但是有个好人手动标注了一些,他对视频序列每十帧标注一帧,总计对480x360视频数据的10167帧数据进行了标注。
Adobe’s Portrait Segmentation

它是一个人体肖像分割数据集,图像分辨率为800x600数据来自Flickr,多数数据是来自手机前置相机拍照的生成。数据集包含1500张训练图像,300张测试图像,全部被标注了,人与背景的分类,图像标注的时候采用了半自动的标注方式。先通过程序进行人脸检测,然后人工手动PS生成。
Materials in Context (MINC)
全场景的物体识别数据集,包含23个类别,7061张标记训练图像,5000张作为测试,2500张作为验证。这些图像主要来自OpenSur face数据集。整个数据集的图像分辨率分布从800x500到500x800之间。
Densely-Annotated VIdeo Segmentation (DAVIS)
该数据集主要是视频中对象分割数据,目的是适应实时动态视频语义分割挑战。主要有50段视频序列构成,其中4219帧是训练数据,2013帧是验证数据,所有的视频数据都下采样至480P大小,像素级别的对每帧数据标注四个类别,分别是人、动物、车辆、对象。视频的另外一个特征是每帧至少有一个前景目标对象在视频帧中出现。
Stanford background
该数据集是室外场景数据集,主要数据来自LabelMe、MSRC、PASCAL VOC、Geometric Context公开数据集。数据集包含715张至少有一个前景对象图像,进行了像素级别的图像标注。主要用于评估分割模型的语义场景理解。
SiftFlow
包含2688完全标注的图像,是LabelMe数据集的子集。绝大数图像是室外八种场景,33个类别,256x256大小。
ADE20K

该数据集是全尺寸的图像语义分割标注数据集,其中训练图像201210张,验证图像2000张,该数据集格式如下:
*.jpg表示RGB图像
*_seg.png表示对象分割mask图像,既包括实例mask也包括类别mask信息,其中通道R与G被编码成对象mask,通道B被编码成实例mask。
*_seg_parts_N.png 表示部分分割mask
*.txt表述每个分割图像的对象与parts的冗余信息文本文件
上述的这些图像语义分割数据集都是2D图像语义分割模型训练、评估、测试经常是使用的一些基准数据集。大家觉得有用请不要忘记分享给更多需要的人 ,赠人玫瑰、手有余香!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~