
深度学习入门教程:分类猫和狗
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


想建立和训练一个深度学习模型,以达到分类猫和狗吗?你来对地方了!
你不需要任何数学知识就可以跟着我。只要高中数学和一点python编程经验就足够了!我会带你走过每一步,制作和训练你的第一个模型。
1.安装程序
为了简单起见,我们将在云GPU(什么是GPU)上运行我们的模型。你可以看看下面的博客,了解GPU在深度学习中的重要性。
https://towardsdatascience.com/what-is-a-gpu-and-do-you-need-one-in-deep-learning-718b9597aa0d
有很多服务提供免费和付费的云GPU实例。我们将使用Gradient,它提供免费的GPU和CPU实例层。我们也将使用fast.ai的vision库来创建我们的模型。
首先,点击这里创建一个Gradient帐户:https://console.paperspace.com/signup?gradient=true
登录你的帐户并选择“Gradient”
单击“Notebook”
为实例命名(可选)
选择Paperspace + Fast.AI基本容器

选择任意一个免费的GPU实例
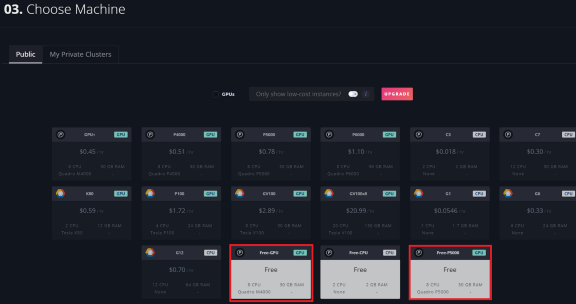
单击“Create Notebook”

你的Notebook 将从挂起→设置→运行!
单击“OPEN V1(CLASSIC)”按钮
对于这个模型,我们将从Bing和DuckDuckGo上获取图像,它们将作为我们的数据集。我们将安装Joe Dockrill编写的jmd_imagescraper库,这将为我们完成任务。
单击 New →Terminal.
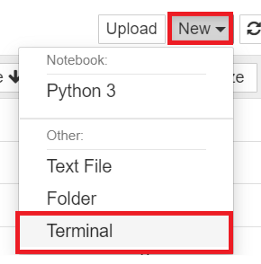
键入并单击enter:
!pip install -q jmd_imagescraper
有关库的更多信息,请访问其官方页面::https://joedockrill.github.io/blog/2020/09/18/jmd-imagescraper-library/
这就把我们带到了设置的最后。关闭终端,再次打开Notebook。编码时间到了!
Jupyter Notebook
Jupyter Notebook是一个web应用程序,允许你创建包含实时代码、公式和文本的文档。你可以做任何事情,从编写代码到发布,以及使用Voilá构建独立的web应用程序!我们将在Gradient提供的Jupyter Notebook上编写和执行我们的代码。
Jupyter Notebook由许多单元组成。你可以通过确定执行单元格的顺序来控制工作流。
单击New→Python3打开一个新的Notebook。
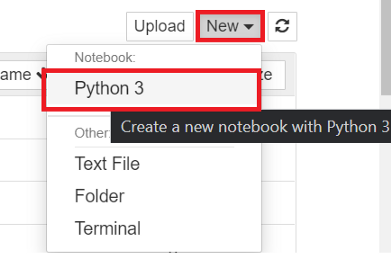
你可以编写文本(在标记单元格中)或编写python代码(在代码单元格中)并按如下方式执行:

一直玩到你觉得舒服为止。使用Run和add cells选项分别执行代码和添加更多单元格。

2.代码
让我们开始有趣的事情,好吗?你可以把每个代码块复制到不同的单元上,然后和我一起运行它们。
让我们先导入fast.ai的vision库和jmd_imagescraper。
!pip install -Uqq fastbook
import fastbook # 导入fast.ai库
from fastbook import * # 别担心,它被设计成与import *一起工作
fastbook.setup_book()
from fastai.vision.widgets import *
# 导入图片爬取器, website: https://joedockrill.github.io/blog/2020/09/18/jmd-imagescraper-library/
from jmd_imagescraper.core import *
from pathlib import Path
from jmd_imagescraper.imagecleaner import *
因为我们的目标是对猫和狗的图像进行分类,所以我们可以制作一个名为“animals”的文件夹,我们可以下载并保存我们的图像。
最后一行将path变量设置为当前工作目录中的“animals”文件夹。
animals=['cat','dog']
path = Path().cwd()/"animals"# 指定当前工作目录的路径
从jmd_imagescraper库调用duckduckgo_search()函数,该函数接受以下内容作为输入:
下载目录(上面指定的路径变量)
文件夹名称(cat)
搜索DuckDuckGo(“猫”)的关键字
要下载的图像数(100)
duckduckgo_search(path,"cat","cats",max_results=100) # 下载100张“猫”图片并保存到path/cat中
等到它搜索图像,下载并直接保存到“animals”中名为“cat”的文件夹中。结果应该如下所示:
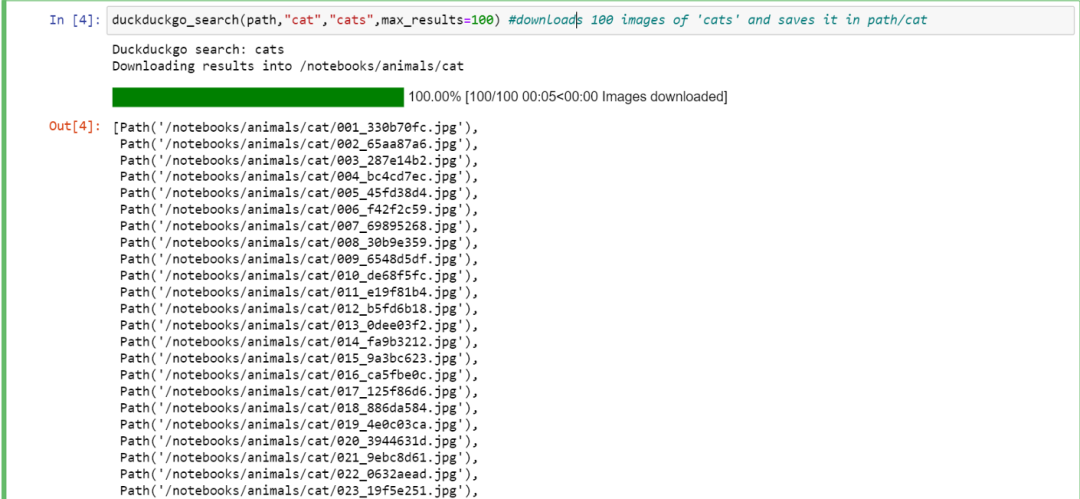
现在让我们对狗的图像做同样的处理。
duckduckgo_search(path,"dog","dogs",max_results=100)# 下载100张“狗”图片并保存到path/dog中
通常会有一些不相关的图像,这会妨碍我们的训练,所以我们删除个别文件。Jupyter提供了一个与删除无关图像的交互式GUI。
display_image_cleaner(path)
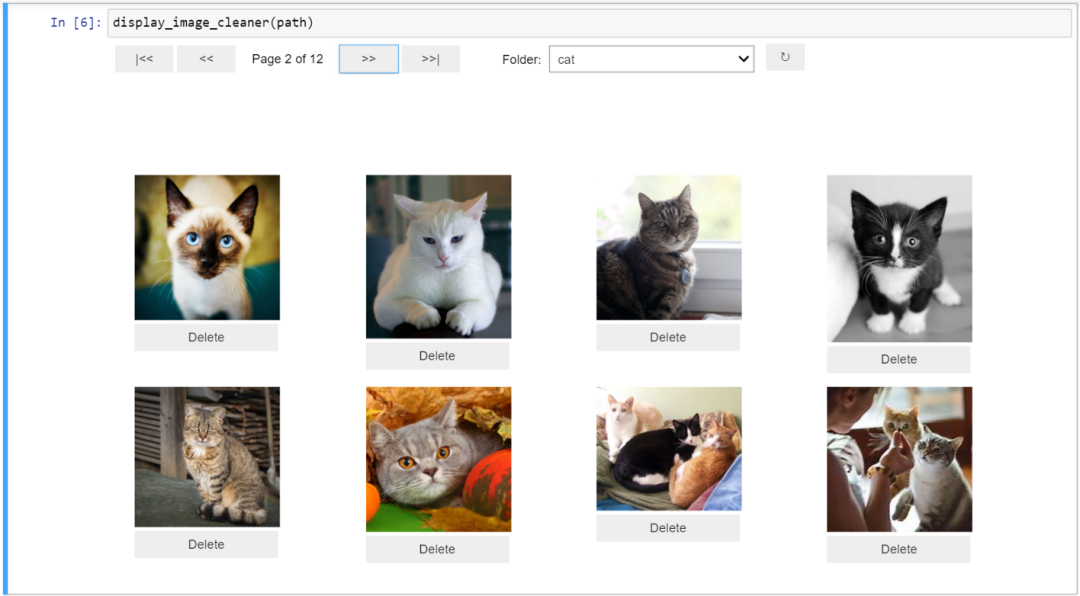
在文件夹之间切换并删除不相关的图像。我发现了一些像这样的图片偷偷地进入了猫和狗。
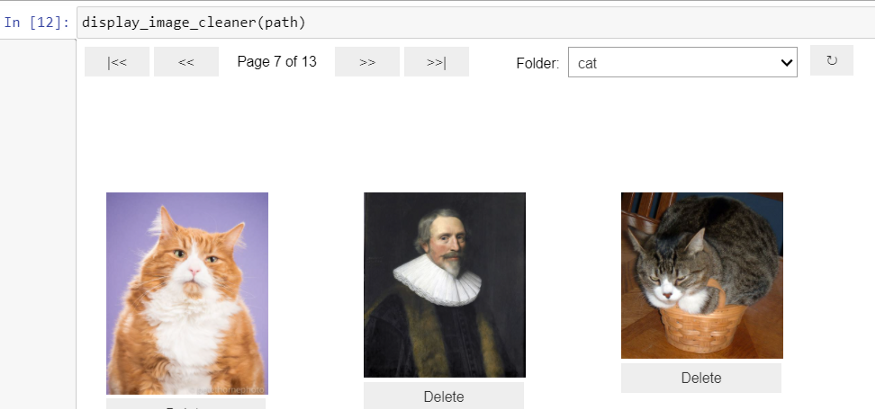
fns=get_image_files(path)
fns
查找失败的下载并从文件夹中取消链接
failed=verify_images(fns)# 寻找非图像文件
failed
failed.map(Path.unlink);# 从文件夹中取消失败文件的链接
现在让我们创建一个Datablock对象,它将图像发送到DataLoaders类。DataLoaders类将给定的数据转换为学习者可以解释的信息。
直觉上,学习者是一个观察所有给定图像并找到模式的人。如果遇到复杂的关键字,不要担心。一旦你运行模型,一切都会变得有意义。
animals=DataBlock(
blocks=(ImageBlock,CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2,seed=42),# 将数据集拆分为训练集和验证集
get_y=parent_label,
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
需要注意的是,在第4行中,我们保留了20%的数据,以便在每个称为epoch训练结束时检查我们的模型。
创建一个名为dls的DataLoaders对象。
dls=animals.dataloaders(path)
看看dls对象中单个批处理中的几个图像。
dls.valid.show_batch(max_n=4,nrows=1)

要求一个学习者在4个不同的训练迭代或时期中根据输入图像进行学习。这需要一些时间,这取决于你的网络速度。
learn = cnn_learner(dls, resnet18, metrics=error_rate)# 训练我们的模型
learn.fine_tune(4)
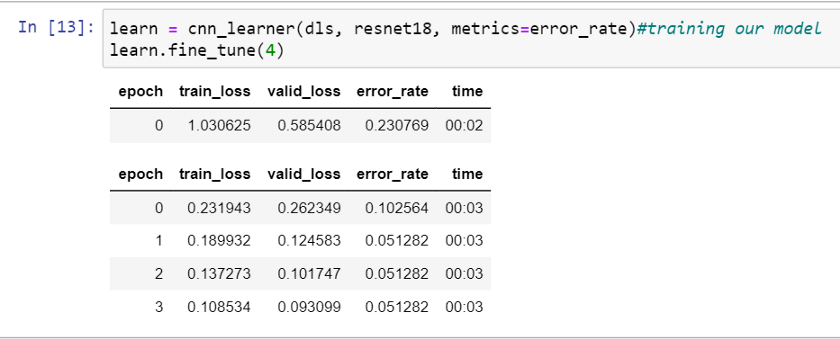
你可能不会看到与图像中相同的结果,但是错误率应该小于0.05。
现在,让我们为验证集绘制一个混淆矩阵。混淆矩阵告诉我们验证集中有多少图像被正确或错误地分类。
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()# 绘制混淆矩阵
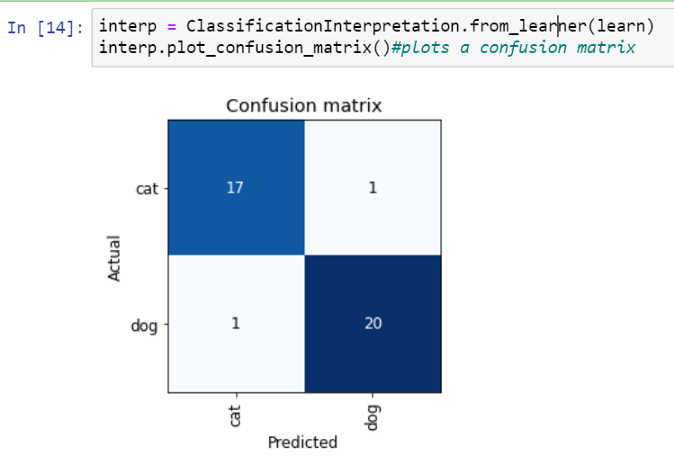
混淆矩阵说明我们的分类器有多好。深蓝色对角线上显示的数字告诉我们正确预测图像的数量。因此我们的分类器做得很好!
我们将在下一行代码中看到两幅错误预测的图片。
interp.plot_top_losses(5, nrows=1)
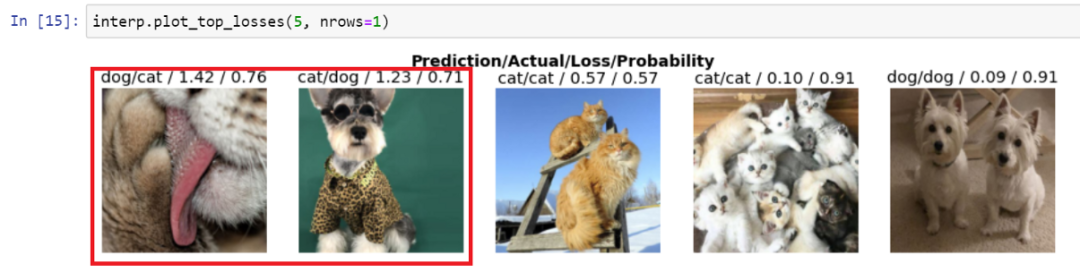
现在让我们对我们的模型进行真正的测试,好吗?下载你选择的猫或狗图像并保存在本地。
learn.export()
path = Path()
path.ls(file_exts='.pkl')
learn_inf = load_learner(path/'export.pkl')
btn_upload = widgets.FileUpload()# 显示可用于从系统上传图像的小部件
btn_upload
这将在你的Jupyter Notebook中创建一个小部件,如下所示:

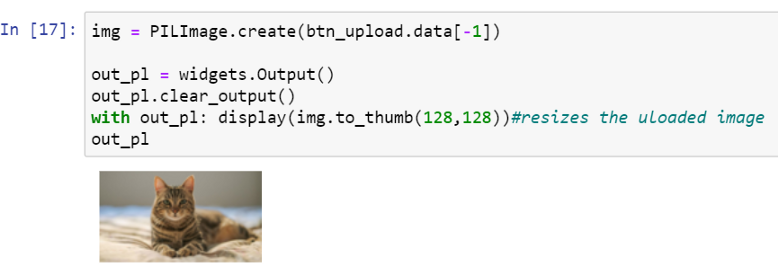
点击上传并选择你的图片。
现在,让我们调整图像大小,以便我们的模型可以预测。最后一行显示调整大小的图像。
img = PILImage.create(btn_upload.data[-1])
out_pl = widgets.Output()
out_pl.clear_output()
with out_pl: display(img.to_thumb(128,128))# 调整图像的大小
out_pl
下面的代码预测图像中的动物,并以我们可以理解的格式显示它。
pred,pred_idx,probs = learn_inf.predict(img)# 要求模型预测图像中的动物!
lbl_pred = widgets.Label()
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'# 以可读格式显示输出
lbl_pred
……………….

不错!!!
我们只用了大约200张图片,就可以创建一个可以对猫和狗进行分类的模型。现在你可以继续进行更改以创建分类器!你也可以使用三个或更多类别。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~