
机器学习算法基础:层 次 聚 类 详 解
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
层次聚类
层次聚类假设类别之间存在层次结构,将样本聚到层次化的类中。所谓层次就是一层一层的进行聚类,可以采用自顶向下的聚类策略(分裂),也可以采用自下而上的策略(凝聚)。
聚合聚类:
开始将每个样本各分到一个类,之后将距离相近的两类合并,建立一个新的类,重复此操作直到满足停止条件,得到层次化的类别。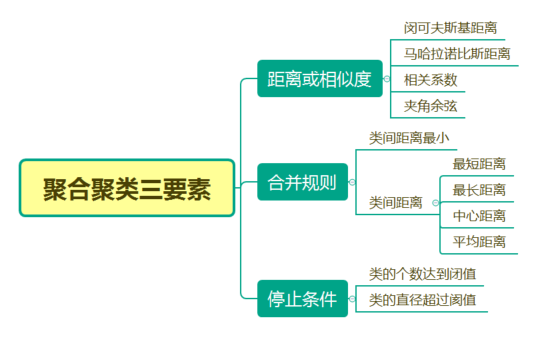
分裂聚类:
开始将所有的样本分到一个类,之后将已有类中相距最远的样本分到两个新的类,重复此操作直到满足停止条件,得到层次化的类别。
簇间的距离度量
合并或拆分层次聚类算法都是基于簇间相似度进行的,每个簇类包含了一个或多个样本点,通常用距离评价簇间或样本间的相似度,即距离越小相似度越高,距离越大相似度越低。1.最小距离法
最小距离法是指以所有簇间样本点距离的最小值作为簇间距离的度量,但是该方法非常容易受到极端值的影响。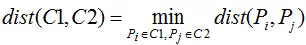 2.最大距离法
2.最大距离法
最大距离法是指以所有簇间样本点距离的最大值作为簇间距离的度量,同样,该方法也容易受到极端值的影响。
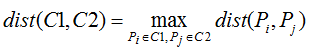
3.平均距离法
最小距离法和最大距离法都容易受到极端值的影响,可以使用平均距离法对如上两种方法做折中处理,即以所有簇间样本点距离的平均值作为簇间距离的度量。
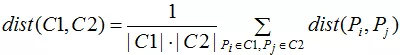
层次聚类的步骤
在理解有关点与点、点与簇和簇与簇之间的距离度量标准之后,就需要进一步掌握层次聚类算法是如何实现样本点聚类的。层次聚类的步骤如下:
(1)将数据集中的每个样本点当作一个类别。
(2)计算所有样本点之间的两两距离,并从中挑选出最小距离的两个点构成一个簇。
(3)继续计算剩余样本点之间的两两距离和点与簇之间的距离,然后将最小距离的点或簇合并到一起。
(4)重复步骤(2)和(3),直到满足聚类的个数或其他设定的条件,便结束算法的运行。
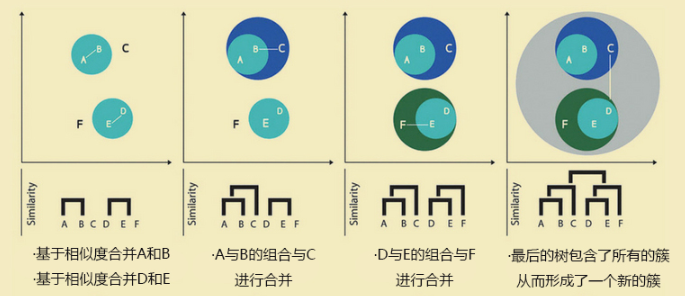
如上的4个步骤可能理解起来比较困难,下图的GIF比较形象: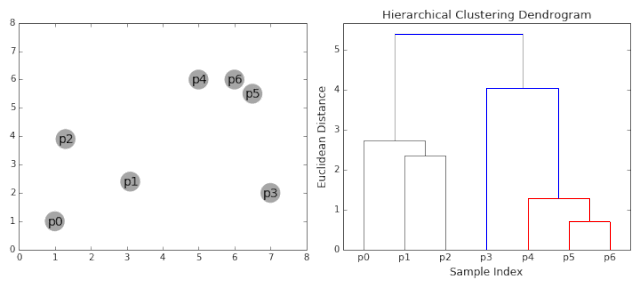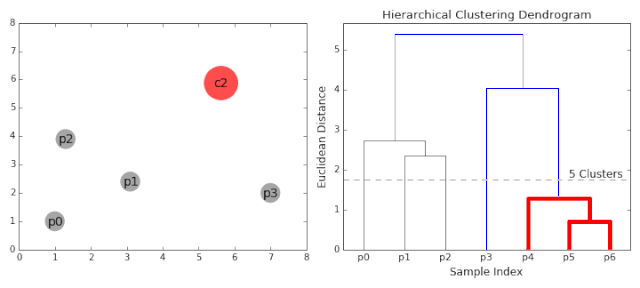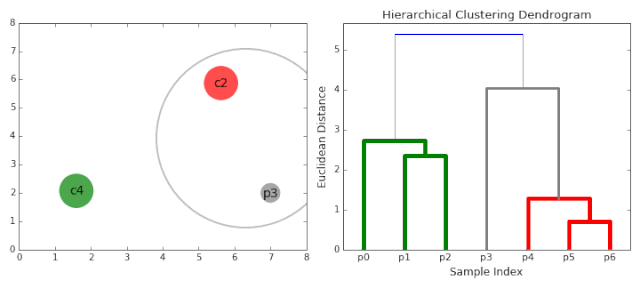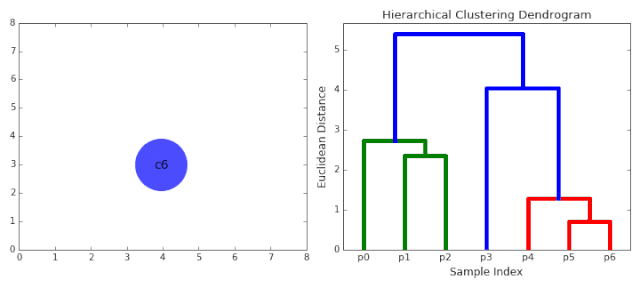
参数
sklearn.cluster.AgglomerativeClustering(n_clusters=2, affinity=’euclidean’, memory=None, connectivity=None, compute_full_tree=’auto’, linkage=’ward’, pooling_func= )
n_clusters:用于指定样本点聚类的个数,默认为2。
affinity:用于指定样本间距离的衡量指标,可以是欧氏距离、曼哈顿距离、余弦相似度等,默认为'euclidean';如果参数linkage为'ward',该参数只能设置为欧氏距离。
memory:是否指定缓存结果的输出,默认为否;如果该参数设置为一个路径,最终将把计算过程的缓存输出到指定的路径中。
connectivity:用于指定一个连接矩阵。
compute_full_tree:通常情况下,当聚类过程达到n_clusters时,算法就会停止,如果该参数设置为True,则表示算法将生成一棵完整的凝聚树。
linkage:用于指定簇间距离的衡量指标,默认为'ward',表示最小距离法;如果为'complete',则表示使用最大距离法;如果为'average',则表示使用平均距离法。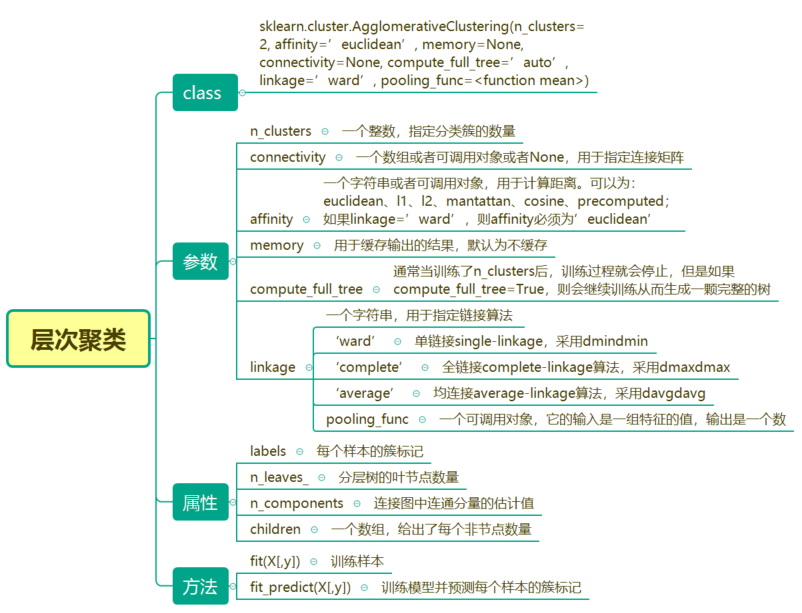
层次聚类案例
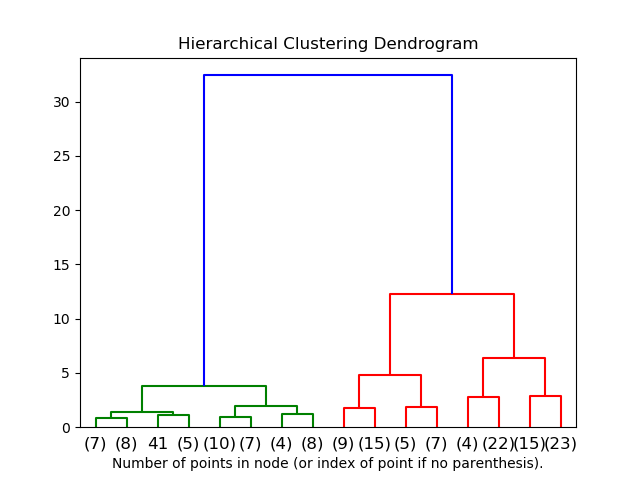
层次聚类还是比较简单易用的,下面是经典的鹫尾花数据集。每朵鸢尾花有4个数据,分别为萼片长(单位:厘米)、萼片宽(单位厘米)、花瓣长度(单位厘米)和花瓣宽(单位厘米)。我们希望能找到可行的方法可以按每朵花的4个数据的差异将这些鸢尾花分成若干类,让每一类尽可能的准确,以便帮助植物专家对这些花进行进一步的分析。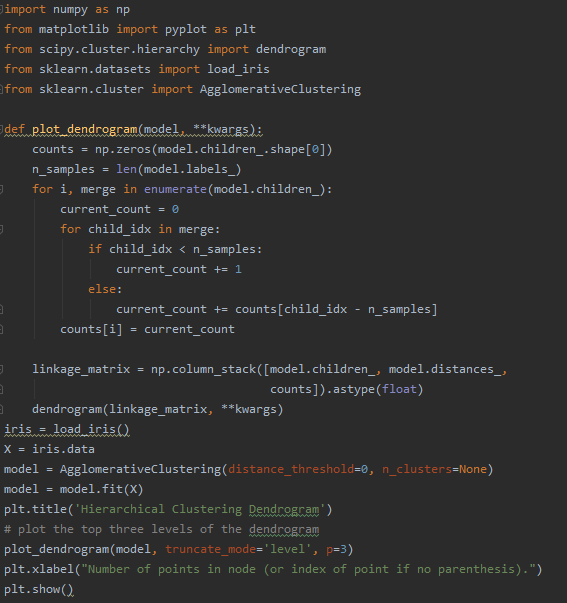 可视化输出结果如下:
可视化输出结果如下:
↓↓↓我的朋友圈更精彩↓ 推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓