
不做跟风党,LiveData,StateFlow,SharedFlow 的使用场景对比
Android 常用的分层架构
Android 中加载 UI 数据不是一件轻松的事,开发者经常需要处理各种边界情况。如各种生命周期和因为「配置更改」导致的 Activity 的销毁与重建。
「配置更改」的场景有很多:屏幕旋转,切换至多窗口模式,调整窗口大小,浅色模式与暗黑模式的切换,更改默认语言,更改字体大小等等
因此普遍处理方式是使用分层的架构。这样开发者就可以编写独立于 UI 的代码,而无需过多考虑生命周期,配置更改等场景。例如,我们可以在表现层(Presentation Layer)的基础上添加一个领域层(Domain Layer) 来保存业务逻辑,使用数据层(Data Layer)对上层屏蔽数据来源(数据可能来自远程服务,可能是本地数据库)。
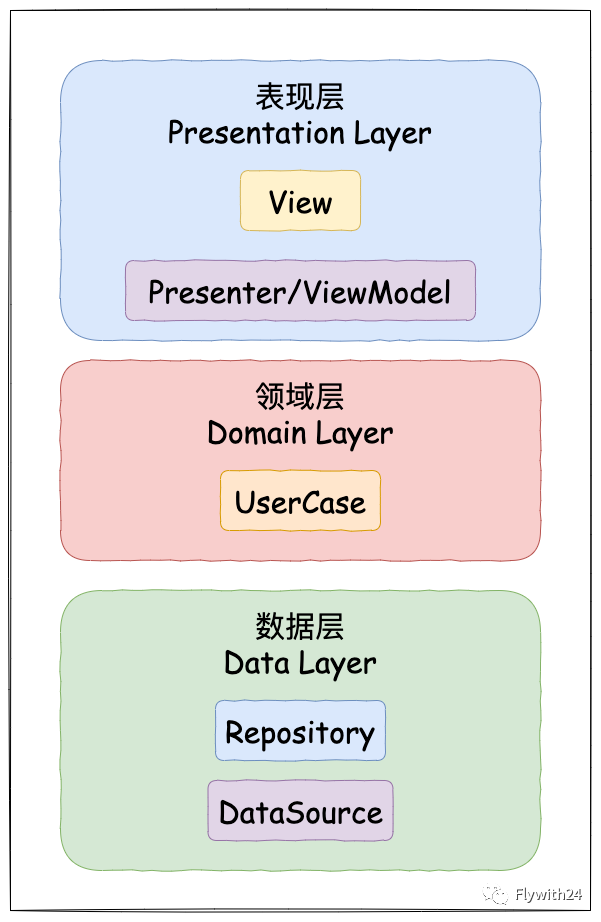
表现层可以分成具有不同职责的组件:
View:处理生命周期回调,用户事件和页面跳转,Android 中主要是 Activity 和 Fragment Presenter 或 ViewModel:向 View 提供数据,并不了解 View 所处的生命周期,通常生命周期比 View 长
Presenter 和 ViewModel 向 View 提供数据的机制是不同的,简单来说:
Presenter 通过持有 View 的引用并直接调用操作 View,以此向 View 提供数据 ViewModel 通过将可观察的数据暴露给观察者来向 View 提供数据
官方提供的可观察的数据 组件是 LiveData。Kotlin 1.4.0 正式版发布之后,开发者有了新的选择:StateFlow 和 SharedFlow。
最近网上流传出「LiveData 被弃用,应该使用 Flow 替代 LiveData」的声音。
LiveData 真的有那么不堪吗?Flow 真的适合你使用吗?
不人云亦云,只求接近真相。我们今天来讨论一下这两种组件。
ViewModel + LiveData
为了实现高效地加载 UI 数据,获得最佳的用户体验,应实现以下目标:
目标 1:已经加载的数据无需在「配置更改」的场景下再次加载 目标 2:避免在非活跃状态(不是 STARTED或RESUMED)下加载数据和刷新 UI目标 3:「配置更改」时不会中断的工作
Google 官方在 2017 年发布了架构组件库:使用 ViewModel + LiveData 帮助开发者实现上述目标。
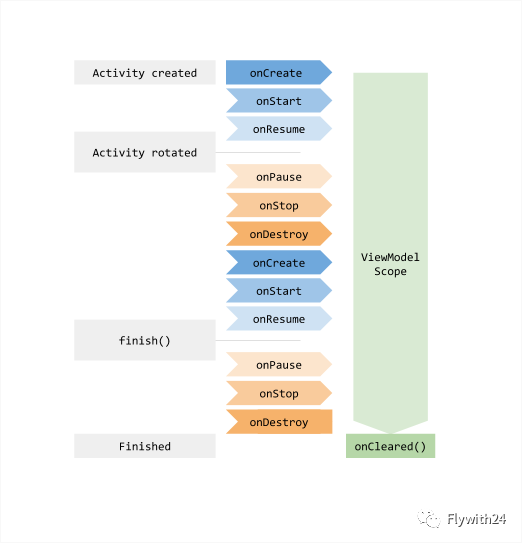
相信很多人在官方文档中见过这个图,ViewModel 比 Activity/Fragment 的生命周期更长,不受「配置更改」导致 Activity/Fragment 重建的影响。刚好满足了目标 1 和目标 3。
LiveData 是可生命周期感知的。新值仅在生命周期处于 STARTED 或 RESUMED 状态时才会分配给观察者,并且观察者会自动取消注册,避免了内存泄漏。LiveData 对实现目标 1 和 目标 2 很有用:它缓存其持有的数据的最新值,并将该值自动分派给新的观察者。
LiveData 的特性
既然有声音说「LiveData 要被弃用了」,那么我们先对 LiveData 进行一个全面的了解。聊聊它能做什么,不能做什么,以及使用过程中有哪些要注意的地方。
LiveData 是 Android Jetpack Lifecycle 组件中的内容。属于官方库的一部分,Kotlin/Java 均可使用。
一句话概括 LiveData:LiveData 是可感知生命周期的,可观察的,数据持有者。
它的能力和作用很简单:更新 UI。
它有一些可以被认为是优点的特性:
观察者的回调永远发生在主线程 仅持有单个且最新的数据 自动取消订阅 提供「可读可写」和「仅可读」两个版本收缩权限 配合 DataBinding实现「双向绑定」
观察者的回调永远发生在主线程
这个很好理解,LiveData 被用来更新 UI,因此 Observer 的 onChanged() 方法在主线程回调。

背后的原理也很简单,LiveData 的 setValue() 发生在主线程(非主线程调用会抛异常,postValue() 内部会切换到主线程调用 setValue())。之后遍历所有观察者的 onChanged() 方法。
仅持有单个且最新的数据
作为数据持有者(data holder),LiveData 仅持有 单个 且 最新 的数据。
单个且最新,意味着 LiveData 每次持有一个数据,并且新数据会覆盖上一个。
这个设计很好理解,数据决定了 UI 的展示,绘制 UI 时肯定要使用最新的数据,「过时的数据」应该被忽略。
配合
Lifecycle,观察者只会在活跃状态下(STARTED到RESUMED)接收到LiveData持有的最新的数据。在非活跃状态下绘制 UI 没有意义,是一种资源的浪费。
自动取消订阅
这是 LiveData 可感知生命周期的重要表现,自动取消订阅意味着开发者无需手动写那些取消订阅的模板代码,降低了内存泄漏的可能性。
背后原理是在生命周期处于 DESTROYED 时,移除观察者。

提供「可读可写」和「仅可读」两个版本
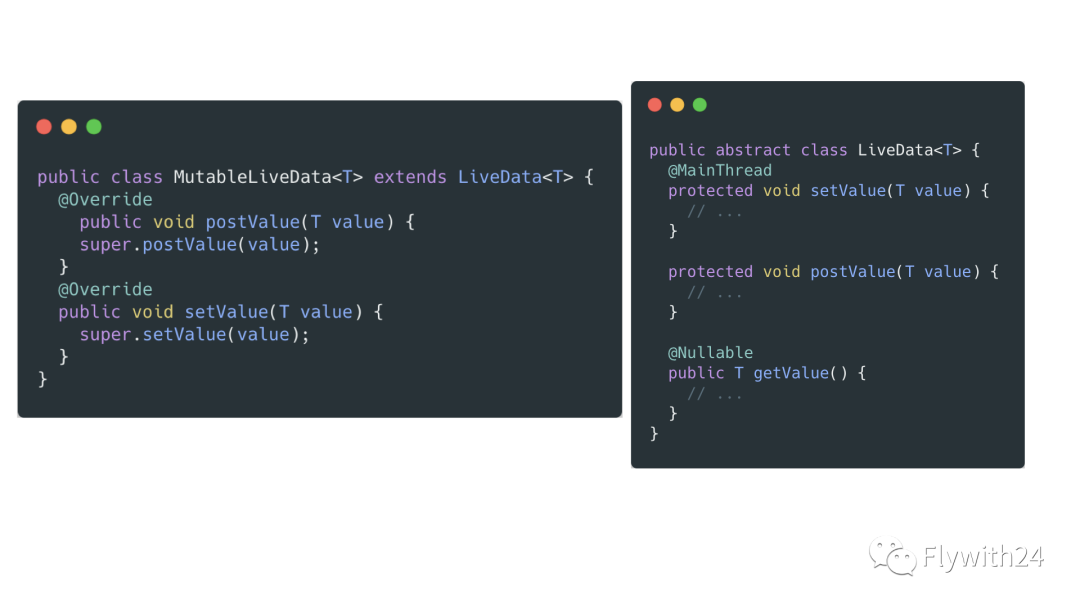
抽象类
LiveData的setValue()和postValue()是 protected,而其实现类MutableLiveData均为 public。
LiveData 提供了 mutable(MutableLiveData) 和 immutable(LiveData) 两个类,前者「可读可写」,后者「仅可读」。通过权限的细化,让使用者各取所需,避免由于权限泛滥导致的数据异常。

配合 DataBinding 实现「双向绑定」
LiveData 配合 DataBinding 可以实现 更新数据自动驱动 UI 变化,如果使用「双向绑定」还能实现 UI 变化影响数据的变化。
以下也是 LiveData 的特性,但我不会将其归类为「设计缺陷」或「LiveData 的缺点」。作为开发者应了解这些特性并在使用过程中正确处理它们。
value 是 nullable 的 在 fragment 订阅时需要传入正确的 lifecycleOwner当 LiveData持有的数据是「事件」时,可能会遇到「粘性事件」LiveData是不防抖的LiveData的transformation工作在主线程
value 是 nullable 的

LiveData#getValue() 是可空的,使用时应该注意判空。
使用正确的 lifecycleOwner
fragment 调用 LiveData#observe() 方法时传入 this 和 viewLifecycleOwner 是不一样的。
原因之前写过,此处不再赘述。感兴趣的小伙伴可以移步查看[1]。
AS 在 lint 检查时会避免开发者犯此类错误。

粘性事件
官方在 [译] 在 SnackBar,Navigation 和其他事件中使用 LiveData(SingleLiveEvent 案例)[2] 一文中描述了一种「数据只会消费一次」的场景。如展示 Snackbar,页面跳转事件或弹出 Dialog。
由于 LiveData 会在观察者活跃时将最新的数据通知给观察者,则会产生「粘性事件」的情况。
如点击 button 弹出一个 Snackbar,在屏幕旋转时,lifecycleOwner 重建,新的观察者会再次调用 Livedata#observe(),因此 Snackbar 会再次弹出。
解决办法是:将事件作为状态的一部分,在事件被消费后,不再通知观察者。这里推荐两种解决方案:
KunMinX/UnPeek-LiveData[3]
巧用 kotlin 扩展函数和 typealias 封装解决「粘性」事件的 LiveData[4]
默认不防抖
setValue()/postValue() 传入相同的值多次调用,观察者的 onChanged() 会被多次调用。
严格讲这不算一个问题,看具体的业务场景,处理也很容易,调用 setValue()/postValue() 前判断一下 vlaue 与之前是否相同即可。

transformation 工作在主线程
有些时候我们从 repository 层拿到的数据需要进行处理,例如从数据库获得 User List,我们想根据 id 获取某个 User。
此时我们可以借助 MediatorLiveData 和 Transformatoins 来实现:
Transformations.map[5]) Transformations.switchMap[6]

map 和 switchMap 内部均是使用 MediatorLiveData#addSource() 方法实现的,而该方法会在主线程调用,使用不当会有性能问题。

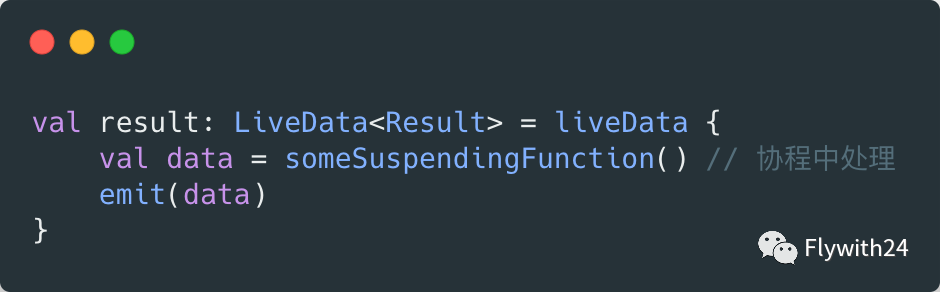
我们可以借助 Kotlin 协程和 RxJava 实现异步任务,最后在主线程上返回 LiveData。如 androidx.lifecycle:lifecycle-livedata-ktx 提供了这样的写法
LiveData 小结
LiveData作为一个 可感知生命周期的,可观察的,数据持有者,被设计用来更新 UILiveData很轻,功能十分克制,克制到需要配合ViewModel使用才能显示其价值由于
LiveData专注单一功能,因此它的一些方法使用上是有局限性的,即通过设计来强制开发者按正确的方式编码(如观察者仅在主线程回调,避免了开发者在子线程更新 UI 的错误操作)由于
LiveData专注单一功能,如果想在表现层之外使用它,MediatorLiveData的操作数据的能力有限,仅有的map和switchMap发生在主线程。可以在switchMap中使用协程或RxJava处理异步任务,最后在主线程返回LiveData。如果项目中使用了RxJava的 AutoDispose[7],甚至可以不使用LiveData,关于Kotlin协程的Flow,我们后文介绍。笔者不喜欢将
LiveData改造成 bus 使用,让组件做其分内的事(此条属于个人观点)
Flow
Flow 是 Kotlin 语言提供的功能,属于 Kotlin 协程的一部分,仅 Kotlin 使用。
Kotlin 协程被用来处理异步任务,而 Flow 则是处理异步数据流。
那么 suspend 方法和 Flow 的区别是什么?各自的使用场景是哪些?
一次性调用(One-shot Call)与数据流(data stream)
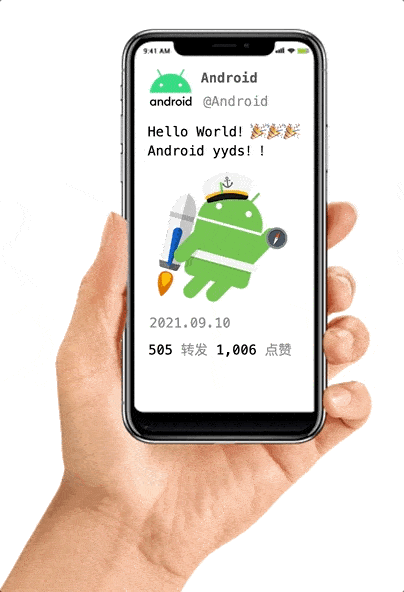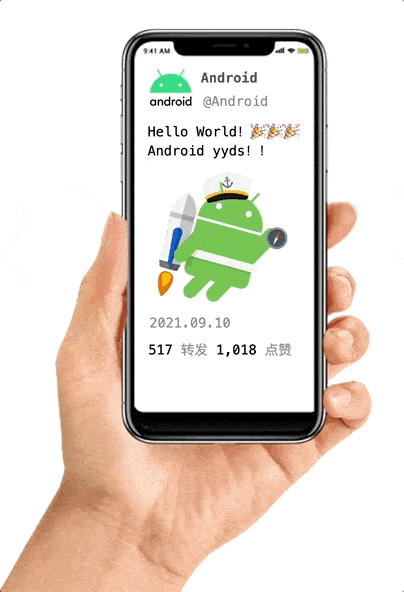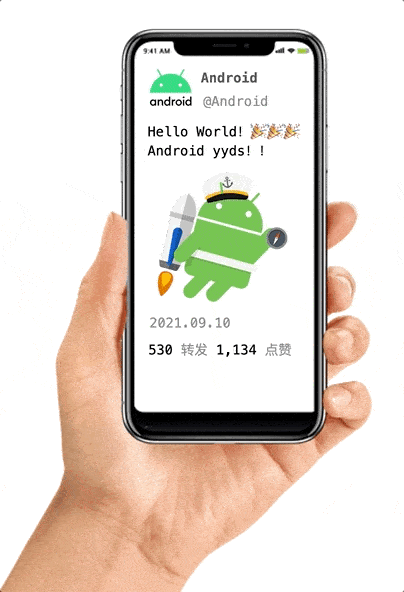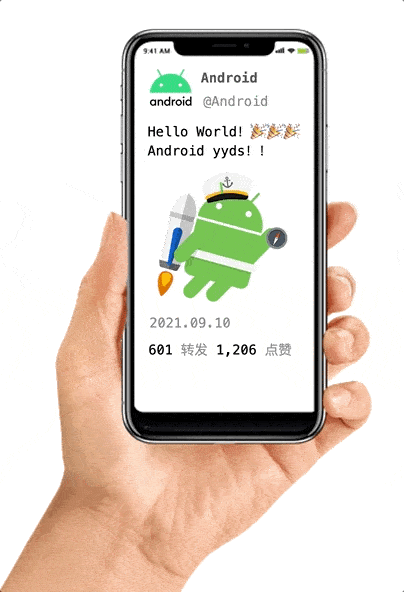
假如我们的 app 的某一屏里显示以下元素,其中红框部分实时性不高,不必很频繁的刷新,转发和点赞属于实时性很高的数据,需要定时刷新。
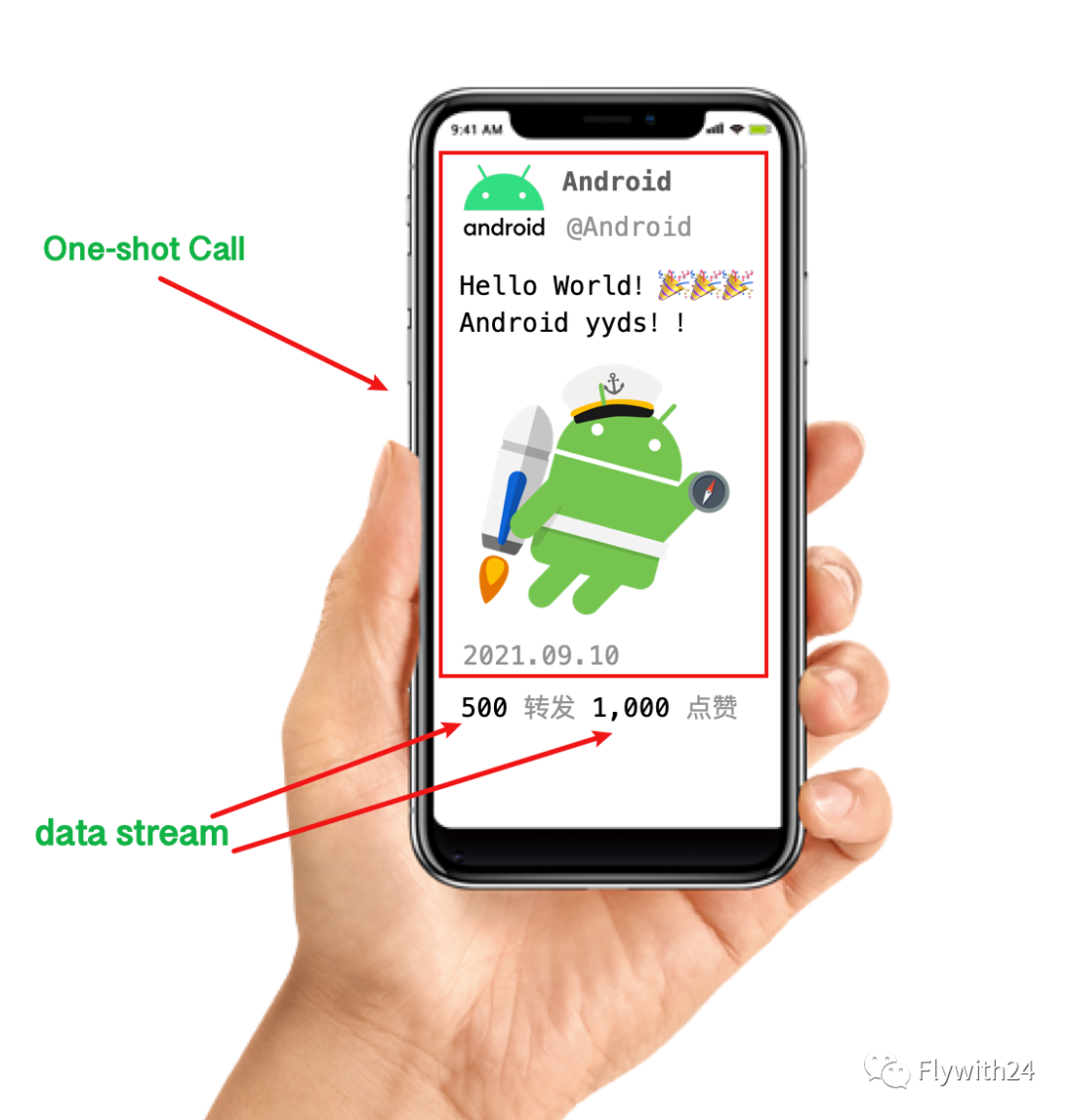
对于实时性不高的数据,我们可以使用 Kotlin 协程处理(此处数据的请求是异步任务):
suspend fun loadData(): Data
uiScope.launch {
val data = loadData()
updateUI(data)
}
而对于实时性较高的数据,挂起函数就无能为力了。有的小伙伴可能会说:「返回个 List 不就行了嘛」。其实无论返回什么类型,这种操作都是 One-shot Call,一次性的请求,有了结果就结束。
示例中的点赞和转发,需要一个 数据是异步计算的,能够 按顺序 提供 多个值
的结构,在 Kotlin 协程中我们有 Flow。
fun dataStream(): Flow<Data>uiScope.launch { dataStream().collect { data -> updateUI(data) }}
当点赞或转发数发生变化时,
updateUI()会被执行,UI 根据最新的数据更新
Flow 的三驾马车
FLow 中有三个重要的概念:
生产者(Producer) 消费者(Consumer) 中介(Intermediaries)
生产者提供数据流中的数据,得益于 Kotlin 协程,Flow 可以 异步地生产数据。
消费者消费数据流内的数据,上面的示例中,updateUI() 方法是消费者。
中介可以对数据流中的数据进行更改,甚至可以更改数据流本身,我们可以借助官方视频中的动画来理解:

在 Android 中,数据层的 DataSource/Repository 是 UI 数据的生产者;而 view/ViewModel 是消费者;换一个角度,在表现层中,view 是用户输入事件的生产者(例如按钮的点击),其它层是消费者。
「冷流」与「热流」
你可能见过这样的描述:「流是冷的」

简单来说,冷流指数据流只有在有消费者消费时才会生产数据。
val dataFlow = flow { // 代码块只有在有消费者 collect 后才会被调用 val data = dataSource.fetchData() emit(data)}...dataFlow.collect { ... }
有一种特殊的 Flow,如 StateFlow/SharedFlow ,它们是热流。这些流可以在没有活跃消费者的情况下存活,换句话说,数据在流之外生成然后传递到流。
BroadcastChannel未来会在 Kotlin 1.6.0 中弃用,在 Kotlin 1.7.0 中删除。它的替代者是StateFlow和SharedFlow
StateFlow
StateFlow 也提供「可读可写」和「仅可读」两个版本。
SateFlow 实现了 SharedFlow,MutableStateFlow 实现 MutableSharedFlow

StateFlow 与 LiveData 十分像,或者说它们的定位类似。
StateFlow 与 LiveData 有一些相同点:
提供「可读可写」和「仅可读」两个版本(
StateFlow,MutableStateFlow)它的值是唯一的
它允许被多个观察者共用 (因此是共享的数据流)
它永远只会把最新的值重现给订阅者,这与活跃观察者的数量是无关的
支持
DataBinding
它们也有些不同点:
必须配置初始值 value 空安全 防抖
MutableStateFlow 构造方法强制赋值一个非空的数据,而且 value 也是非空的。这意味着 StateFlow 永远有值

StateFlow 的
emit()和tryEmit()方法内部实现是一样的,都是调用setValue()
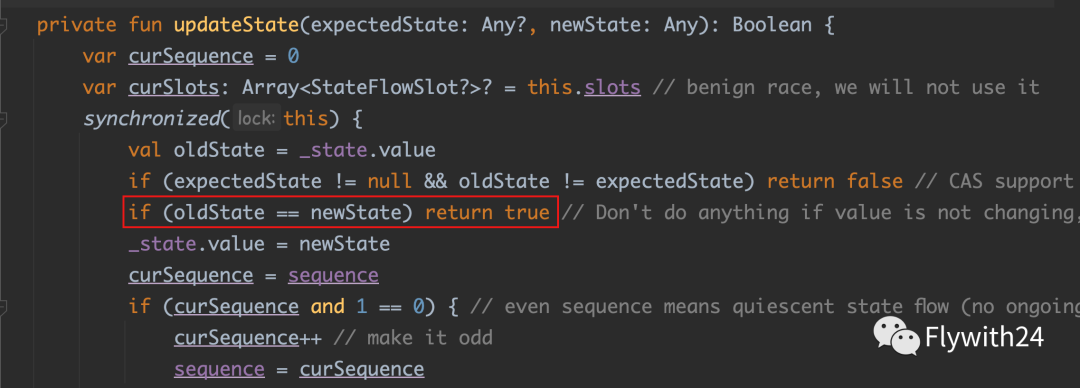
StateFlow 默认是防抖的,在更新数据时,会判断当前值与新值是否相同,如果相同则不更新数据。
SharedFlow
与 SateFlow 一样,SharedFlow 也有两个版本:SharedFlow 与 MutableSharedFlow。

那么它们有什么不同?
MutableSharedFlow没有起始值SharedFlow可以保留历史数据MutableSharedFlow发射值需要调用emit()/tryEmit()方法,没有setValue()方法

与 MutableSharedFlow 不同,MutableSharedFlow 构造器中是不能传入默认值的,这意味着 MutableSharedFlow 没有默认值。
val mySharedFlow = MutableSharedFlow<Int>()val myStateFlow = MutableStateFlow<Int>(0)...mySharedFlow.emit(1)myStateFlow.emit(1)
SateFlow 与 SharedFlow 还有一个区别是SateFlow只保留最新值,即新的订阅者只会获得最新的和之后的数据。
而 SharedFlow 根据配置可以保留历史数据,新的订阅者可以获取之前发射过的一系列数据。
后文会介绍背后的原理
它们被用来应对不同的场景:UI 数据是状态还是事件。
状态(State)与事件(Event)
状态可以是的 UI 组件的可见性,它始终具有一个值(显示/隐藏)
而事件只有在满足一个或多个前提条件时才会触发,不需要也不应该有默认值
为了更好地理解 SateFlow 和 SharedFlow 的使用场景,我们来看下面的示例:
用户点击登录按钮 调用服务端验证登录合法性 登录成功后跳转首页
我们先将步骤 3 视为 状态 来处理:

使用状态管理还有与 LiveData 一样的「粘性事件」问题,如果在 ViewNavigationState 中我们的操作是弹出 snackbar,而且已经弹出一次。在旋转屏幕后,snackbar 会再次弹出。
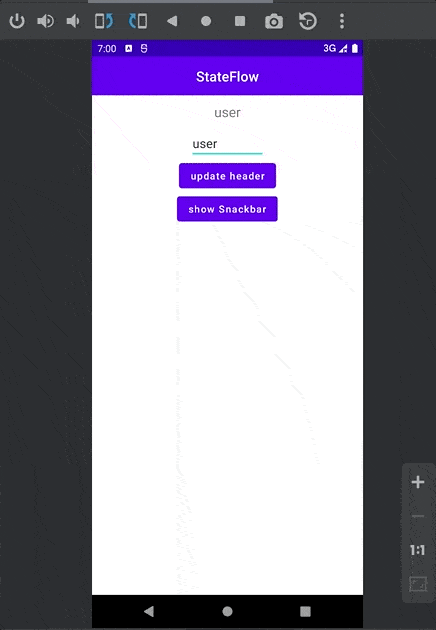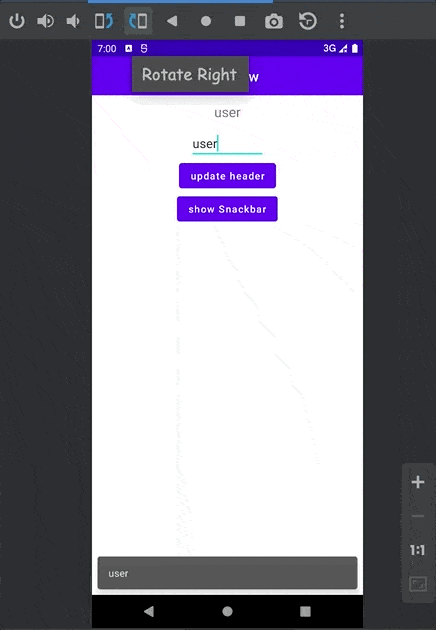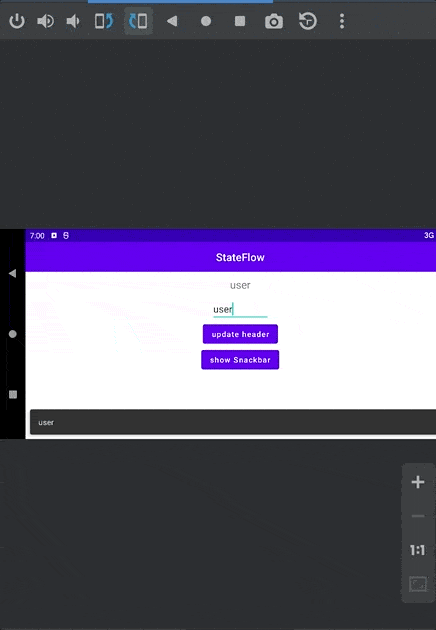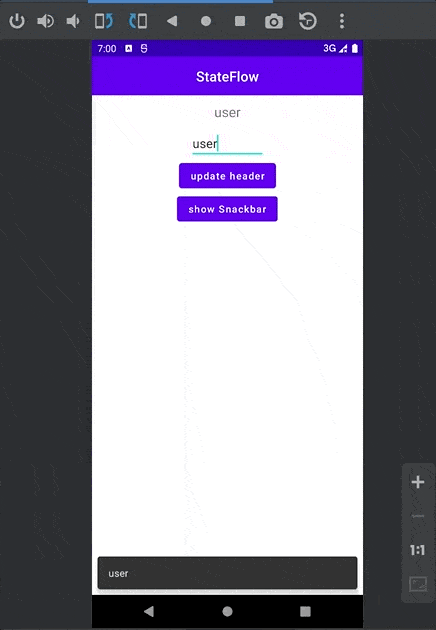
如果我们将步骤 3 作为 事件 处理:

使用 SharedFlow 不会有「粘性事件」的问题,MutableSharedFlow 构造函数里有一个 replay 的参数,它代表着可以对新订阅者重新发送多个之前已发出的值,默认值为 0。

SharedFlow 在其 replayCache 中保留特定数量的最新值。每个新订阅者首先从 replayCache 中取值,然后获取新发射的值。replayCache 的最大容量是在创建 SharedFlow 时通过 replay 参数指定的。replayCache 可以使用 MutableSharedFlow.resetReplayCache 方法重置。
当 replay 为 0 时,replayCache size 为 0,新的订阅者获取不到之前的数据,因此不存在「粘性事件」的问题。
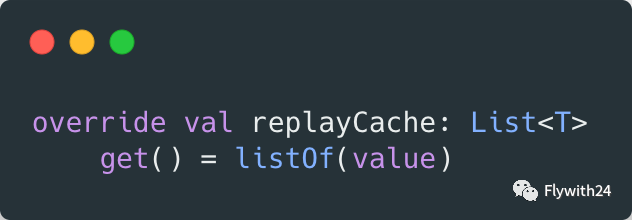
StateFlow 的 replayCache 始终有当前最新的数据:
至此, StateFlow 与 SharedFlow 的使用场景就很清晰了:
状态(State)用 StateFlow ;事件(Event)用 SharedFlow
StateFlow,SharedFlow 与 LiveData 的使用对比

上图分别展示了
LiveData,StateFlow,SharedFlow在ViewModel中的使用。其中
LiveDataViewModel中使用LiveEventLiveData处理「粘性事件」
FlowViewModel中使用SharedFlow处理「粘性事件」
emit()方法是挂起函数,也可以使用tryEmit()

注意:Flow 的 collect 方法不能写在同一个
lifecycleScope中
flowWithLifecycle是lifecycle-runtime-ktx:2.4.0-alpha01后提供的扩展方法
Flow 在 fragment 中的使用要比 LiveData 繁琐很多,我们可以封装一个扩展方法来简化:

关于 repeatOnLifecycle 的设计问题,可以移步 设计 repeatOnLifecycle API 背后的故事[8]。
使用 collect 方法时要注意一个问题。

这种写法是错误的!
viewModel.headerText.collect 在协程被取消前会一直挂起,这样后面的代码便不会执行。
Flow 与 RxJava
Flow 和 RxJava 的定位很接近,限于篇幅原因,此处不展开讲,本节只罗列一下它们的对应关系:
Flow= (cold)Flowable/Observable/SingleChannel=SubjectsStateFlow=BehaviorSubjects(永远有值)SharedFlow=PublishSubjects(无初始值)suspend function=Single/Maybe/Completable
参考文档与推荐资源
LiveData:还没普及就让我去世?我去你的 Kotlin 协程[9] 协程 Flow 最佳实践 | 基于 Android 开发者峰会应用[10] 使用更为安全的方式收集 Android UI 数据流[11] 从 LiveData 迁移到 Kotlin 数据流[12] 设计 repeatOnLifecycle API 背后的故事[13] LiveData with Coroutines and Flow — Part I: Reactive UIs[14] LiveData with Coroutines and Flow — Part II: Launching coroutines with Architecture Components[15] LiveData beyond the ViewModel — Reactive patterns using Transformations and MediatorLiveData[16] The Benefits of StateFlow and SharedFlow over LiveData - Andrey Liashuk[17] Going with the flow - Kotlin Vocabulary[18] LiveData with Coroutines and Flow (Android Dev Summit '19)[19] DevFest South Africa - Migrating from LiveData to Coroutines and Flow - Jossi Wolf[20]
总结
LiveData的主要职责是更新 UI,要充分了解其特性,合理使用Flow可分为生产者,消费者,中介三个角色冷流和热流最大的区别是前者依赖消费者
collect存在,而热流一直存在,直到被取消StateFlow与LiveData定位相似,前者必须配置初始值,value 空安全并且默认防抖StateFlow与SharedFlow的使用场景不同,前者适用于「状态」,后者适用于「事件」
回到文章开头的话题,LiveData 并没有那么不堪,由于其作用单一,功能简单,简单便意味着不易出错。所以在表现层中 ViewModel 向 view 暴露 LiveData 是一个不错的选择。而在 Repository 或 DataSource 中,我们可以利用 LiveData + 协程来处理数据的转换。当然,我们也可以使用功能更强大的 Flow。
LiveData,StateFLow,SharedFlow,它们都有着各自的使用场景。并且如果使用不当,都会或多或少地遇到一些所谓的「坑」。因此在使用某个组件时,要充分了解其设计缘由以及相关特性,否则就会掉进陷阱,收到不符合预期的行为。
关于我
人总是喜欢做能够获得正反馈(成就感)的事情,如果感觉本文内容对你有帮助的话,麻烦点亮一下 👍,这对我很重要哦~
我是 Flywith24[21],人只有通过和别人的讨论,才能知道我们自己的经验是否是真实的,加我微信交流,让我们共同进步。
参考资料
移步查看: https://juejin.cn/post/6844904111112978439#heading-14
[2][译] 在 SnackBar,Navigation 和其他事件中使用 LiveData(SingleLiveEvent 案例): https://juejin.cn/post/6844903623252508685
[3]KunMinX/UnPeek-LiveData: https://github.com/KunMinX/UnPeek-LiveData
[4]巧用 kotlin 扩展函数和 typealias 封装解决「粘性」事件的 LiveData: https://juejin.cn/post/6844904176527343630
[5]Transformations.map: https://developer.android.com/reference/androidx/lifecycle/Transformations#public-methods
[6]Transformations.switchMap: https://developer.android.com/reference/androidx/lifecycle/Transformations#public-methods
[7]AutoDispose: https://github.com/uber/AutoDispose
[8]设计 repeatOnLifecycle API 背后的故事: https://juejin.cn/post/7001371050202103838
[9]LiveData:还没普及就让我去世?我去你的 Kotlin 协程: https://juejin.cn/post/6994550224303685640
[10]协程 Flow 最佳实践 | 基于 Android 开发者峰会应用: https://juejin.cn/post/6844904153181847566
[11]使用更为安全的方式收集 Android UI 数据流: https://juejin.cn/post/6984258307293151239
[12]从 LiveData 迁移到 Kotlin 数据流: https://juejin.cn/post/6979008878029570055
[13]设计 repeatOnLifecycle API 背后的故事: https://juejin.cn/post/7001371050202103838
[14]LiveData with Coroutines and Flow — Part I: Reactive UIs: https://medium.com/androiddevelopers/livedata-with-coroutines-and-flow-part-i-reactive-uis-b20f676d25d7
[15]LiveData with Coroutines and Flow — Part II: Launching coroutines with Architecture Components: https://medium.com/androiddevelopers/livedata-with-coroutines-and-flow-part-ii-launching-coroutines-with-architecture-components-337909f37ae7
[16]LiveData beyond the ViewModel — Reactive patterns using Transformations and MediatorLiveData: https://medium.com/androiddevelopers/livedata-beyond-the-viewmodel-reactive-patterns-using-transformations-and-mediatorlivedata-fda520ba00b7
[17]The Benefits of StateFlow and SharedFlow over LiveData - Andrey Liashuk: https://www.youtube.com/watch?v=JnN6EFZ6DO8&t=889s
[18]Going with the flow - Kotlin Vocabulary: https://www.youtube.com/watch?v=emk9_tVVLcc
[19]LiveData with Coroutines and Flow (Android Dev Summit '19): https://www.youtube.com/watch?v=B8ppnjGPAGE
[20]DevFest South Africa - Migrating from LiveData to Coroutines and Flow - Jossi Wolf: https://www.youtube.com/watch?v=j91fz33v_iM
[21]Flywith24: https://flywith24.gitee.io/