
谁能取代Android的LiveData- StateFlow or SharedFlow?

点击上方蓝字关注我,知识会给你力量

这个系列我做了协程和Flow开发者的一系列文章的翻译,旨在了解当前协程、Flow、LiveData这样设计的原因,从设计者的角度,发现他们的问题,以及如何解决这些问题,pls enjoy it。
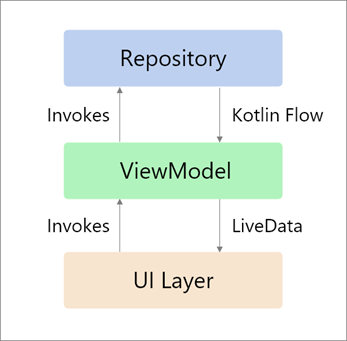
Kotlin Coroutines最近引入了两种Flow类型,即SharedFlow和StateFlow,Android的社区开始思考用这些新类型中的一种或两种来替代LiveData的可能性和意义。这方面的两个主要原因是:
- LiveData与UI紧密相连
- LiveData与Android平台紧密相连
我们可以从这两个事实中得出结论,从Clean Architecture的角度来看,虽然LiveData在表现层中运行良好,但它并不适合领域层,因为领域层最好是独立于平台的(指纯Kotlin/Java模块);而且它也不太适合数据层(Repositories实现和数据源),因为我们通常应该将数据访问工作交给工作线程。
 img
img不过,我们不能只是用纯Flow来替代LiveData。在所有应用层上使用纯Flow作为LiveData的替代品的主要问题是:
- Flow是无状态的(不能通过.value访问)
- Flow是声明性的(冷的):一个Flow构建器仅仅描述了Flow是什么,并且只有在Collect时才会被物化。然而,一个新的Flow是为每个收集器有效地运行(物化)的,这意味着上游(昂贵的)数据库访问是为每个收集器重复地运行。
- Flow本身并不了解Android的生命周期,也不提供Android生命周期状态变化时收集器的自动暂停和恢复。
❝
这些都不能被看作是纯粹的Flow的内在缺陷:这些只是使它不能很好地替代LiveData的特点,但在其他情况下却可以很强大。对于(3),我们已经可以使用LifecycleCoroutineScope的扩展,如 launchWhenStarted来启动coroutine来收集我们的Flow--这些收集器将自动暂停,并与组件的Lifecycle同步恢复。
❞
注意:在本文中,我们把Collect和观察作为同义概念。Collect是Kotlin Flow的首选术语(我们Collect一个Flow),观察是Android的LiveData的首选术语(我们观察一个LiveData)。
但是,(1)--获取当前状态,以及(2)--对于N>=1个收集器只物化一次,对于0个收集器不物化,又是怎么回事?
现在,SharedFlow和StateFlow为这两个问题提供了一个解决方案。
A practical example
让我们用一个实际的用例来说明。我们的用例是获取附近的位置。我们假设Firebase实时数据库和GeoFire库一起使用,它允许查询附近的地点。
Using LiveData end-to-end
 img
img让我们首先展示一下从数据源一直到视图的LiveData的使用。数据源负责通过GeoQuery连接到Firebase实时数据库。当我们收到onGeoQueryReady()或onGeoQueryError()时,我们用自上次onGeoQueryReady()以来进入、退出或移动的地点的总数来更新LiveData值。
@Singleton
class NearbyUsersDataSource @Inject constructor() {
// Ideally, those should be constructor-injected.
val geoFire = GeoFire(FirebaseDatabase.getInstance().getReference("geofire"))
val geoLocation = GeoLocation(0.0, 0.0)
val radius = 100.0
val geoQuery = geoFire.queryAtLocation(geoLocation, radius)
// Listener for receiving GeoLocations
val listener: GeoQueryEventListener = object : GeoQueryEventListener {
val map = mutableMapOf<Key, GeoLocation>()
override fun onKeyEntered(key: String, location: GeoLocation) {
map[key] = location
}
override fun onKeyExited(key: String) {
map.remove(key)
}
override fun onKeyMoved(key: String, location: GeoLocation) {
map[key] = location
}
override fun onGeoQueryReady() {
_locations.value = State.Ready(map.toMap())
}
override fun onGeoQueryError(e: DatabaseError) {
_locations.value = State.Error(map.toMap(), e.toException())
}
}
// Listen for changes only while observed
private val _locations = object : MutableLiveData<State>() {
override fun onActive() {
geoQuery.addGeoQueryEventListener(listener)
}
override fun onInactive() {
geoQuery.removeGeoQueryEventListener(listener)
}
}
// Expose read-only LiveData
val locations: LiveData<State> by this::_locations
sealed class State(open val value: Map<Key, GeoLocation>) {
data class Ready(
override val value: Map<Key, GeoLocation>
) : State(value)
data class Error(
override val value: Map<Key, GeoLocation>,
val exception: Exception
) : State(value)
}
}
我们的Repository、ViewModel和Activity就应该像这样简单。
@Singleton
class NearbyUsersRepository @Inject constructor(
nearbyUsersDataSource: NearbyUsersDataSource
) {
val locations get() = nearbyUsersDataSource.locations
}
class NearbyUsersViewModel @ViewModelInject constructor(
nearbyUsersRepository: NearbyUsersRepository
) : ViewModel() {
val locations get() = nearbyUsersRepository.locations
}
@AndroidEntryPoint
class NearbyUsersActivity : AppCompatActivity() {
private val viewModel: NearbyUsersViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
viewModel.locations.observe(this) { state: State ->
// Update views with the data.
}
}
}
这种方法可能很好用,直到你决定让包含存储库接口的域层独立于平台(因为它应该是)。另外,一旦你需要将工作卸载到数据源的工作线程上,你会发现使用LiveData并不容易,也没有成文的方法。
Using flows on Data Source and Repository
 img
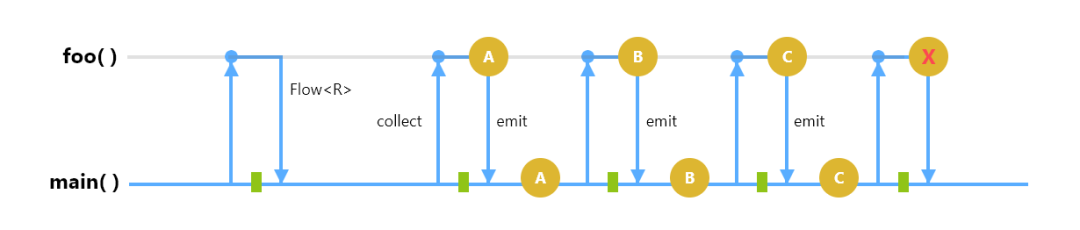
img让我们把我们的数据源转换为使用Flow。我们有一个流构建器,callbackFlow {},它将一个回调转换为一个冷流。当这个Flow被收集时,它运行传递给flow builder的代码块,添加GeoQuery监听器并到达awaitClose {},在那里它暂停运行,直到Flow被关闭(也就是说,直到没有人在收集,或者直到它因任何未捕获的异常而被取消)。当关闭时,它就会删除监听器,并且流量被取消。
@Singleton
class NearbyUsersDataSource @Inject constructor() {
// Ideally, those should be constructor-injected.
val geoFire = GeoFire(FirebaseDatabase.getInstance().getReference("geofire"))
val geoLocation = GeoLocation(0.0, 0.0)
val radius = 100.0
val geoQuery = geoFire.queryAtLocation(geoLocation, radius)
private fun GeoQuery.asFlow() = callbackFlow {
val listener: GeoQueryEventListener = object : GeoQueryEventListener {
val map = mutableMapOf<Key, GeoLocation>()
override fun onKeyEntered(key: String, location: GeoLocation) {
map[key] = location
}
override fun onKeyExited(key: String) {
map.remove(key)
}
override fun onKeyMoved(key: String, location: GeoLocation) {
map[key] = location
}
override fun onGeoQueryReady() {
emit(State.Ready(map.toMap()))
}
override fun onGeoQueryError(e: DatabaseError) {
emit(State.Error(map.toMap(), e.toException()))
}
}
addGeoQueryEventListener(listener)
awaitClose { removeGeoQueryEventListener(listener) }
}
val locations: Flow<State> = geoQuery.asFlow()
sealed class State(open val value: Map<Key, GeoLocation>) {
data class Ready(
override val value: Map<Key, GeoLocation>
) : State(value)
data class Error(
override val value: Map<Key, GeoLocation>,
val exception: Exception
) : State(value)
}
}
我们的Repository和ViewModel没有任何变化,但是我们的Activity现在接收的是Flow而不是LiveData,所以它需要进行调整:不是观察LiveData,而是收集Flow。
@AndroidEntryPoint
class NearbyUsersActivity : AppCompatActivity() {
private val viewModel: NearbyUsersViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
lifecycleScope.launchWhenStarted {
viewModel.locations.collect {
// Update views with the data.
}
}
}
}
我们使用 launchWhenStarted {} 来收集Flow,所以只有当Activity到达onStart() 生命周期状态时,coroutine才会自动启动,而当它到达onStop() 生命周期状态时则会自动暂停。这类似于LiveData给我们提供的自动处理Lifecycle的方式。
注意:你可能会选择在你的表现层(活动)中继续使用LiveData。在这种情况下,你可以通过使用Flow.asLiveData()扩展函数在ViewModel中轻松地从Flow转换为LiveData。这个决定会带来一些后果,我们将在下一节课中讨论,我们将展示使用SharedFlow和StateFlow端到端的通用性更强,可能更适合你的架构。
 img
img「What are the issues with using Flow in the View Layer?」
这种方法的第一个问题是对生命周期的处理,LiveData会自动为我们处理。我们在上面的例子中通过使用 launchWhenStarted {}实现了类似的行为。
但还有一个问题:因为Flow是声明性的,并且只在收集时运行(物化),如果我们有多个收集器,那么每个收集器都会运行一个新的Flow,彼此之间完全独立。根据所做的操作,如数据库或网络操作,这可能是非常无效的。如果我们期望操作只做一次,以保证正确性,它甚至可能导致错误的状态。在我们的实际例子中,我们将为每个采集器添加一个新的GeoQuery监听器--可能不是一个关键问题,但肯定是在浪费内存和CPU周期。
❝
注意:如果你通过在ViewModel中使用Flow.asLiveData()将你的Repository Flow转换为LiveData,LiveData就会成为Flow的唯一收集器,无论表现层中有多少个观察者,都只有一个Flow被收集。然而,为了使这种架构顺利运行,你需要保证你的每个其他组件都从ViewModel访问你的LiveData,而不是直接从Repository访问Flow。这可能会证明自己是一个挑战,这取决于你的应用程序的解耦程度:所有需要存储库的组件,如交互器(用例)的实现,现在将依赖于活动实例来获得ViewModel实例,这些组件的范围需要相应地限制。
我们只想要一个GeoQuery监听器,不管我们在视图层有多少个采集器。我们可以通过在所有采集器之间共享流程来实现这一点。
❞
SharedFlow to the rescue
SharedFlow是一个允许在多个Collecter之间共享自身的流,因此对于所有同时进行的收集器来说,只有一个流被有效运行(物化)。如果你定义了一个访问数据库的SharedFlow,并且它被多个收集器收集,那么数据库访问将只运行一次,并且产生的数据将被共享给所有收集器。
StateFlow也可以用来实现同样的行为:它是一个专门的SharedFlow,具有.值(它的当前状态)和特定的SharedFlow配置(约束)。我们将在后面讨论这些约束。
我们有一个操作符,用于将任何Flow转换为SharedFlow。
fun <T> Flow<T>.shareIn(
scope: CoroutineScope,
started: SharingStarted,
replay: Int = 0
): SharedFlow<T> (source)
让我们将其应用于我们的数据源。
该范围是所有用于物化Flow的计算将被完成的地方。由于我们的数据源是一个@Singleton,我们可以使用应用程序进程的LifecycleScope,它是一个LifecycleCoroutineScope,在进程创建时被创建,只有在进程销毁时才被销毁。
对于开始参数,我们可以使用SharingStarted.WhileSubscribed(),这使得我们的Flow只有在订阅者的数量从0变成1时才开始共享(具体化),而当订阅者的数量从1变成0时就停止共享。这类似于我们之前通过在onActive()回调中添加GeoQuery监听器和在onInactive()回调中删除监听器来实现的LiveData行为。我们也可以将其配置为急切地启动(立即物化,永不去物化)或懒惰地启动(首次收集时物化,永不去物化),但我们确实希望它在不被下游收集时停止上游的数据库收集。
关于术语的注意:就像我们对LiveData使用观察者这个术语,对冷流使用收集者这个术语一样,我们对SharedFlow使用订阅者这个术语。对于重放参数,我们可以使用1:新的订阅者将在订阅后立即获得最后一个发出的值。
@Singleton
class NearbyUsersDataSource @Inject constructor() {
// Ideally, those should be constructor-injected.
val geoFire = GeoFire(FirebaseDatabase.getInstance().getReference("geofire"))
val geoLocation = GeoLocation(0.0, 0.0)
val radius = 100.0
val geoQuery = geoFire.queryAtLocation(geoLocation, radius)
private fun GeoQuery.asFlow() = callbackFlow {
val listener: GeoQueryEventListener = object : GeoQueryEventListener {
val map = mutableMapOf<Key, GeoLocation>()
override fun onKeyEntered(key: String, location: GeoLocation) {
map[key] = location
}
override fun onKeyExited(key: String) {
map.remove(key)
}
override fun onKeyMoved(key: String, location: GeoLocation) {
map[key] = location
}
override fun onGeoQueryReady() {
emit(State.Ready(map.toMap())
}
override fun onGeoQueryError(e: DatabaseError) {
emit(State.Error(map.toMap(), e.toException())
}
}
addGeoQueryEventListener(listener)
awaitClose { removeGeoQueryEventListener(listener) }
}.shareIn(
ProcessLifecycleOwner.get().lifecycleScope,
SharingStarted.WhileSubscribed(),
1
)
val locations: Flow<State> = geoQuery.asFlow()
sealed class State(open val value: Map<Key, GeoLocation>) {
data class Ready(
override val value: Map<Key, GeoLocation>
) : State(value)
data class Error(
override val value: Map<Key, GeoLocation>,
val exception: Exception
) : State(value)
}
}
把SharedFlow想象成一个流量收集器本身可能会有帮助,它把我们上游的冷流量具体化为热流量,并在下游的许多收集器之间分享收集的值。在上游的冷流和下游的多个收集器之间有一个中间人。
现在,我们可能会认为我们的活动不需要调整。错了! 有一个问题:当在一个用 launchWhenStarted {} 启动的 coroutine 中收集流量时,coroutine 将会暂停。时,该循环程序将在onStop()时暂停,并在onStart()时恢复,但它仍将被订阅到该流。对于MutableSharedFlow来说,这意味着MutableSharedFlow.subscriptionCount对于暂停的coroutine不会改变。为了利用SharingStarted.WhileSubscribed()的力量,我们需要在onStop()上实际取消订阅,并在onStart()上再次订阅。这意味着取消收集的循环程序并重新创建它。
(更多细节见本期和本期)。
让我们为这个通用目的创建一个类。
@PublishedApi
internal class ObserverImpl<T> (
lifecycleOwner: LifecycleOwner,
private val flow: Flow<T>,
private val collector: suspend (T) -> Unit
) : DefaultLifecycleObserver {
private var job: Job? = null
override fun onStart(owner: LifecycleOwner) {
job = owner.lifecycleScope.launch {
flow.collect {
collector(it)
}
}
}
override fun onStop(owner: LifecycleOwner) {
job?.cancel()
job = null
}
init {
lifecycleOwner.lifecycle.addObserver(this)
}
}
inline fun <reified T> Flow<T>.observe(
lifecycleOwner: LifecycleOwner,
noinline collector: suspend (T) -> Unit
) {
ObserverImpl(lifecycleOwner, this, collector)
}
inline fun <reified T> Flow<T>.observeIn(
lifecycleOwner: LifecycleOwner
) {
ObserverImpl(lifecycleOwner, this, {})
}
注意:如果你想在你的项目中使用这个自定义观察器,你可以使用这个库:https://github.com/psteiger/flow-lifecycle-observer 现在,我们可以调整我们的Activity来使用我们刚刚创建的.observeIn(LifecycleOwner)扩展函数。
@AndroidEntryPoint
class NearbyUsersActivity : AppCompatActivity() {
private val viewModel: NearbyUsersViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
viewModel
.locations
.onEach { /* new locations received */ }
.observeIn(this)
}
}
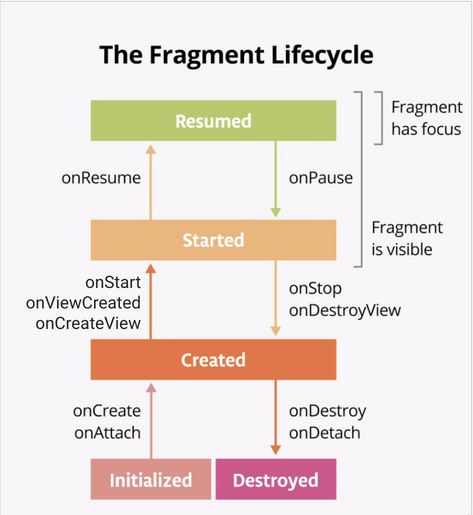
当LifecycleOwner的Lifecycle达到CREATED状态(就在onStop()调用之前)时,用observeIn(LifecycleOwner)创建的collector coroutine将被销毁,一旦达到STARTED状态(onStart()调用之后),将被重新创建。
注意:为什么是CREATED状态?不应该是STOPPED状态吗?一开始听起来很反常,但这很有意义。Lifecycle.State只有以下几种状态。
创建、销毁、初始化、恢复、开始。不存在STOPPED和PAUSED状态。当生命周期到达onPause()时,它没有进入一个新的状态,而是回到了STARTED状态。当它到达onStop()时,它又回到了CREATED状态。
 img
img我们现在有一个数据源,它只实现一次,但将其数据分享给所有的订阅者。一旦没有订阅者,它的上游收集就会停止,一旦第一个订阅者重新出现,就会重新启动。它对Android平台没有依赖性,也不与主线程绑定(通过简单地应用.flowOn()操作符:flowOn(Dispatchers.IO)或.flowOn(Dispatchers.Default),流量转换可以发生在其他线程中)。
But what if I need to eventually access the current state of the flow without collecting it?
如果我们真的需要像使用LiveData那样用.value访问Flow的状态,我们可以使用StateFlow,它是一个专门的、受限的SharedFlow。我们可以应用stateIn(),而不是应用shareIn()操作符来具体化流。
fun <T> Flow<T>.stateIn(
scope: CoroutineScope,
started: SharingStarted,
initialValue: T
): StateFlow<T> (source)
从方法参数中我们可以看到,sharedIn()和stateIn()之间有两个基本区别。
- stateIn()不支持重放的定制。StateFlow是一个具有固定重放=1的SharedFlow。这意味着新的订阅者在订阅时将立即得到当前的状态。
- stateIn()需要一个初始值。这意味着如果你当时没有初始值,你将需要使StateFlow类型T为空,或者使用一个密封的类来表示一个空的初始值。
❝
状态流是一个共享流
状态流是SharedFlow的一个特殊用途、高性能和高效的实现,用于共享状态这种狭窄但广泛使用的情况。关于适用于所有共享流的基本规则、约束和操作符,请参见SharedFlow文档。
状态流总是有一个初始值,向新的订阅者复制一个最新的值,不缓冲任何更多的值,但保留最后发出的一个值,并且不支持 resetReplayCache。当一个状态流用以下参数创建并对其应用distinctUntilChanged操作符时,它的行为与共享流完全一样。
❞
// MutableStateFlow(initialValue) is a shared flow with the following parameters:
val shared = MutableSharedFlow(
replay = 1,
onBufferOverflow = BufferOverflow.DROP_OLDEST
)
shared.tryEmit(initialValue) // emit the initial value
val state = shared.distinctUntilChanged() // get StateFlow-like behavior
当你需要一个在行为上有调整的StateFlow时,使用SharedFlow,比如额外的缓冲,重放更多的值,或者省略初始值。
然而,注意选择SharedFlow的明显妥协:你将失去StateFlow.value。
Which to choose, StateFlow or SharedFlow?
回答这个问题的简单方法是试图回答其他几个问题。
"我真的需要在任何时候用myFlow.value访问流的当前状态吗?"
❝
如果这个问题的答案是否定的,你可以考虑SharedFlow。
❞
"我是否需要支持发射和收集重复值?"
❝
如果这个问题的答案是肯定的,你将需要SharedFlow。
❞
"我是否需要为新的订阅者重放超过最新的值?"
❝
如果这个问题的答案是肯定的,你将需要SharedFlow。
❞
正如我们所看到的,StateFlow用于所有的事情并不自动是正确的答案。
- 它忽略(混淆)了重复的值,这是不可以配置的。有时你需要不忽略重复的值,例如:一个连接尝试,将尝试结果存储在一个流中,每次失败后需要重试。
- 另外,它需要一个初始值。因为SharedFlow没有.value,所以它不需要用初始值来实例化--收集器将直接暂停,直到第一个值出现,在任何值到来之前,没有人会尝试访问.value。如果你没有StateFlow的初始值,你必须使StateFlow类型为nullable T?,并使用null作为初始值(或者为默认的无值声明一个密封类)。
- 另外,你可能想调整一下重放值。SharedFlow可以为新的订阅者重放最后的n个值。StateFlow有一个固定的重放值为1--它只共享当前的状态值。
两者都支持SharingStarted ( Eagerly, Lazily or WhileSubscribed())配置。我通常使用SharingStarted.WhileSubscribed(),并在Activity onStart()/onStop()上销毁/创建我所有的收集器,所以当用户不积极使用应用程序时,数据源上游收集将停止(这类似于在LiveData onActive()/onInactive()上删除/重新添加监听器)。
StateFlow对SharedFlow的约束可能不是最适合你的,你可能想用行为来调整并选择使用SharedFlow。就我个人而言,我很少需要访问myFlow.value,而且我喜欢SharedFlow的灵活性,所以我通常选择SharedFlow。
在官方文档中阅读更多关于StateFlow和SharedFlow的内容。
A practical case where SharedFlow instead of StateFlow is needed
考虑以下围绕谷歌计费客户端库的包装器。我们有一个MutableSharedFlow billingClientStatus,用于存储当前与计费服务的连接状态。
我们将其初始值设置为SERVICE_DISCONNECTED。我们收集billingClientStatus,当它不确定时,我们尝试启动与计费服务的连接()。如果连接尝试失败,我们将发出SERVICE_DISCONNECTED。
在这个例子中,如果billingClientStatus是一个MutableStateFlow而不是MutableSharedFlow,当它的值已经是SERVICE_DISCONNECTED,而我们试图将它设置为相同的值(连接重试失败),它将忽略更新,因此,它不会再尝试重新连接。
@Singleton
class Biller @Inject constructor(
@ApplicationContext private val context: Context,
) : PurchasesUpdatedListener, BillingClientStateListener {
private var billingClient: BillingClient =
BillingClient.newBuilder(context)
.setListener(this)
.enablePendingPurchases()
.build()
private val billingClientStatus = MutableSharedFlow<Int>(
replay = 1,
onBufferOverflow = BufferOverflow.DROP_OLDEST
)
override fun onBillingSetupFinished(result: BillingResult) {
billingClientStatus.tryEmit(result.responseCode)
}
override fun onBillingServiceDisconnected() {
billingClientStatus.tryEmit(BillingClient.BillingResponseCode.SERVICE_DISCONNECTED)
}
// ...
// Suspend until billingClientStatus == BillingClient.BillingResponseCode.OK
private suspend fun requireBillingClientSetup(): Boolean =
withTimeoutOrNull(TIMEOUT_MILLIS) {
billingClientStatus.first { it == BillingClient.BillingResponseCode.OK }
true
} ?: false
init {
billingClientStatus.tryEmit(BillingClient.BillingResponseCode.SERVICE_DISCONNECTED)
billingClientStatus.observe(ProcessLifecycleOwner.get()) {
when (it) {
BillingClient.BillingResponseCode.OK -> with (billingClient) {
updateSkuPrices()
handlePurchases()
}
else -> {
delay(RETRY_MILLIS)
billingClient.startConnection(this@Biller)
}
}
}
}
private companion object {
private const val TIMEOUT_MILLIS = 2000L
private const val RETRY_MILLIS = 3000L
}
}
在这种情况下,我们需要使用SharedFlow,它支持发射连续的重复值。
On the GeoFire use-case
如果你有使用GeoFire的实际需要,我已经开发了一个库,geofire-ktx,允许随时将GeoQuery对象转换为Flow。它还支持获取位于其他DatabaseReference根中的DataSnapshot,其子键与GeoFire根相同,因为这是GeoQuery的一个常见用例。它还支持将这些数据作为一个类的实例而不是DataSnapshot来获取。这是通过Flow转换完成的。该库的源代码完成了本文中给出的例子。
对于其他Android库,请查看https://github.com/psteiger。
https://github.com/psteiger/geofire-ktx/blob/master/geofire/src/main/java/com/freelapp/geofire/flow/GeoQuery.kt
原文链接:https://proandroiddev.com/should-we-choose-kotlins-stateflow-or-sharedflow-to-substitute-for-android-s-livedata-2d69f2bd6fa5
向大家推荐下我的网站 https://xuyisheng.top/ 点击原文一键直达
专注 Android-Kotlin-Flutter 欢迎大家访问
往期推荐
本文原创公众号:群英传,授权转载请联系微信(Tomcat_xu),授权后,请在原创发表24小时后转载。< END >作者:徐宜生
更文不易,点个“三连”支持一下👇