
实例分割的进阶三级跳:从 Mask R-CNN 到 Hybrid Task Cascade
原文链接:https://zhuanlan.zhihu.com/p/57629509
CVPR 2019 运气还算比较好,共有 3 篇 paper 被接收,分别在物体检测的 module、framework 和 training process 上有所探索。
本文打算介绍一下 Hybrid Task Cascade,是 framework 层面的一篇工作,基于之前 COCO 比赛团队合作的成果。

背景
实例分割(Instance Segmentation)是一个和物体检测非常相关但是更难的问题,在物体检测的基础上,还要求分割出物体的像素,如下图所示。
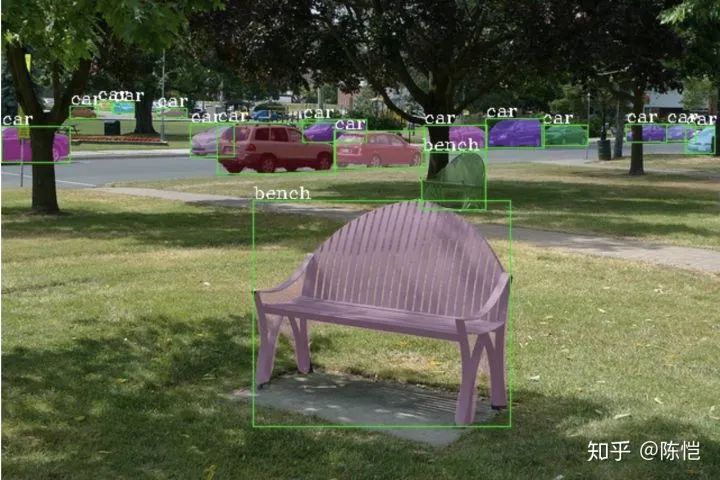
实例分割这个问题近几年的发展在很大程度上是由 COCO 数据集和比赛推动的。从 MNC,FCIS 到 PANet,都是在 COCO instance segmentation track 上拿第一名的方法。
Mask R-CNN 是个例外,因为 paper 公开得比较早,所以是 2017 年前几名队伍的基本方法。同理可知,Hybrid Task Cascade(HTC)在 COCO 2018 的比赛中也取得了第一名。
概述
级联是一种比较经典的结构,在很多任务中都有用到,比如物体检测中的 CC-Net,Cascade R-CNN,语义分割中的 Deep Layer Cascade 等等。
然而将这种结构或者思想引入到实例分割中并不是一件直接而容易的事情,如果直接将 Mask R-CNN 和 Cascade R-CNN 结合起来,获得的提升是有限的,因此我们需要更多地探索检测和分割任务的关联。
在本篇论文中,我们提出了一种新的实例分割框架,设计了多任务多阶段的混合级联结构,并且融合了一个语义分割的分支来增强 spatial context。这种框架取得了明显优于 Mask R-CNN 和 Cascade Mask R-CNN 的结果。
方法
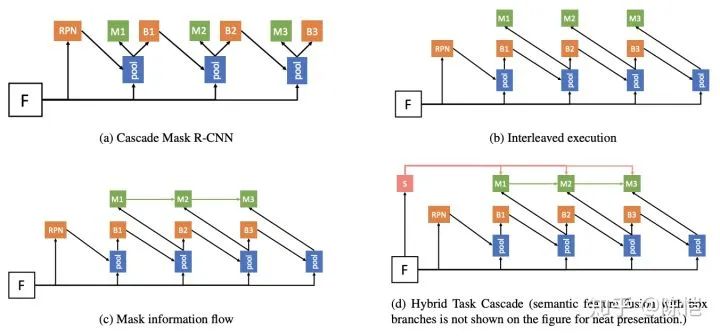
整个框架的演进可以用四张图来表示,其中 M 表示 mask 分支,B 表示 box 分支,数字表示 stage,M1 即为第一个 stage 的 mask 分支。
进阶准备:Cascade Mask R-CNN
由于 Cascade R-CNN 在物体检测上的结果非常好,我们首先尝试将 Cascade R-CNN 和 Mask R-CNN 直接进行杂交,得到子代 Cascade Mask R-CNN,如上图(a)所示。
在这种实现里,每一个 stage 和 Mask R-CNN 相似,都有一个 mask 分支 和 box 分支。当前 stage 会接受 RPN 或者 上一个 stage 回归过的框作为输入,然后预测新的框和 mask。
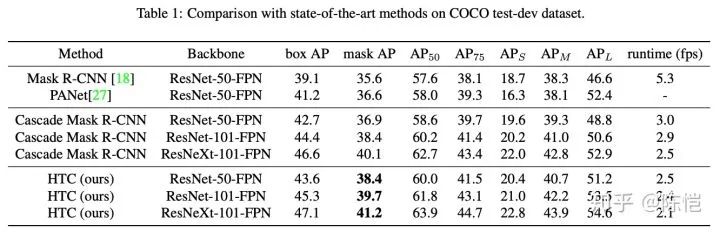
这也是实验中我们所比较的 baseline,从实验表格可以看到其实这个 baseline 已经很强了,但是仍然存在明显的问题,主要在于 Cascade Mask R-CNN 相比 Mask R-CNN 在 box AP 上提高了 3.5 个点,但是在 mask AP 上只提高了 1.2 个点。
进阶第一步:Interleaved Execution
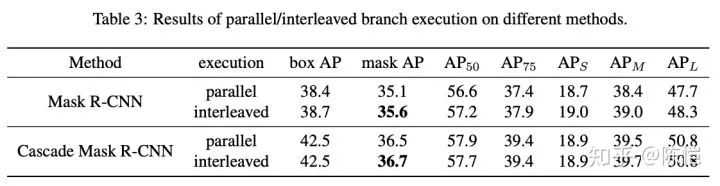
Cascade R-CNN 虽然强行在每一个 stage 里面塞下了两个分支,但是这两个分支之间在训练过程中没有任何交互,它们是并行执行的。
所以我们提出 Interleaved Execution,也即在每个 stage 里,先执行 box 分支,将回归过的框再交由 mask 分支来预测 mask,如上图(b)所示。
这样既增加了每个 stage 内不同分支之间的交互,也消除了训练和测试流程的 gap。
我们发现这种设计对 Mask R-CNN 和 Cascade Mask R-CNN 的 mask 分支都有一定提升。
进阶第二步:Mask Information Flow
这一步起到了很重要的作用,对一般 cascade 结构的设计和改进也具有借鉴意义。我们首先回顾原始 Cascade R-CNN 的结构,每个 stage 只有 box 分支。
当前 stage 对下一 stage 产生影响的途径有两条:(1) 的输入特征是
的输入特征是  预测出回归后的框通 RoI Align 获得的;(2) 的回归目标是依赖 的框的预测的。
预测出回归后的框通 RoI Align 获得的;(2) 的回归目标是依赖 的框的预测的。
这就是 box 分支的信息流,让下一个 stage 的特征和学习目标和当前 stage 有关。
在 cascade 的结构中这种信息流是很重要的,让不同 stage 之间在逐渐调整而不是类似于一种 ensemble。
然而在 Cascade Mask R-CNN 中,不同 stage 之间的 mask 分支是没有任何直接的信息流的,  只和当前 通过 RoI Align 有关联而与
只和当前 通过 RoI Align 有关联而与  没有任何联系。
没有任何联系。
多个 stage 的 mask 分支更像用不同分布的数据进行训练然后在测试的时候进行 ensemble,而没有起到 stage 间逐渐调整和增强的作用。
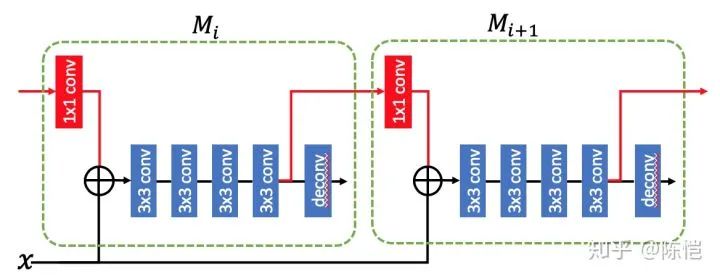
为了解决这一问题,我们在相邻的 stage 的 mask 分支之间增加一条连接,提供 mask 分支的信息流,让 能知道 的特征。
具体实现上如下图中红色部分所示,我们将 的特征经过一个 1x1 的卷积做 feature embedding,然后输入到 ,这样 既能得到 backbone 的特征,也能得到上一个 stage 的特征。
进阶第三步:Semantic Feature Fusion
这一步是我们尝试将语义分割引入到实例分割框架中,以获得更好的 spatial context。
因为语义分割需要对全图进行精细的像素级的分类,所以它的特征是具有很强的空间位置信息,同时对前景和背景有很强的辨别能力。
通过将这个分支的语义信息再融合到 box 和 mask 分支中,这两个分支的性能可以得到较大提升。
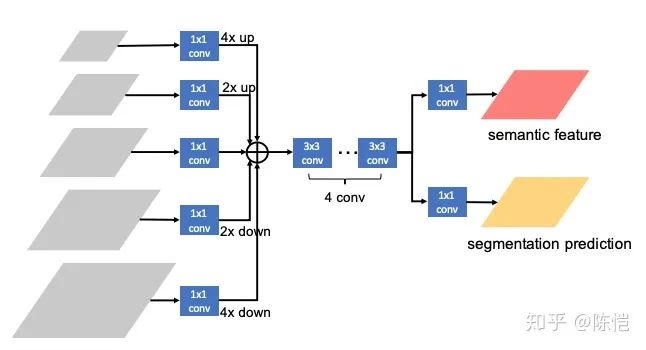
在具体设计上,为了最大限度和实例分割模型复用 backbone,减少额外参数,我们在原始的 FPN 的基础上增加了一个简单的全卷积网络用来做语义分割。
首先将 FPN 的 5 个 level 的特征图 resize 到相同大小并相加,然后经过一系列卷积,再分别预测出语义分割结果和语义分割特征。
这里我们使用 COCO-Stuff 的标注来监督语义分割分支的训练。
红色的特征将和原来的 box 和 mask 分支进行融合(在下图中没有画出),融合的方法我们也是采用简单的相加。
进阶结果
通过上面的几步,在使用 ResNet-50 的 backbone 下,相对 Cascade Mask R-CNN 可以有 1.5 个点的 mask AP 提升,相对 Mask R-CNN 可以有 2.9 个点的提升。在 COCO 2017 val 子集上的逐步对比试验如下表所示。
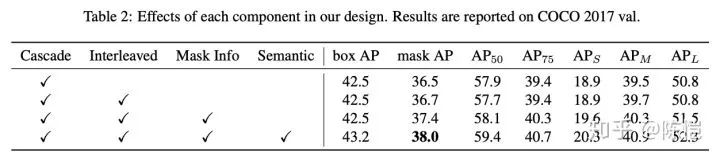
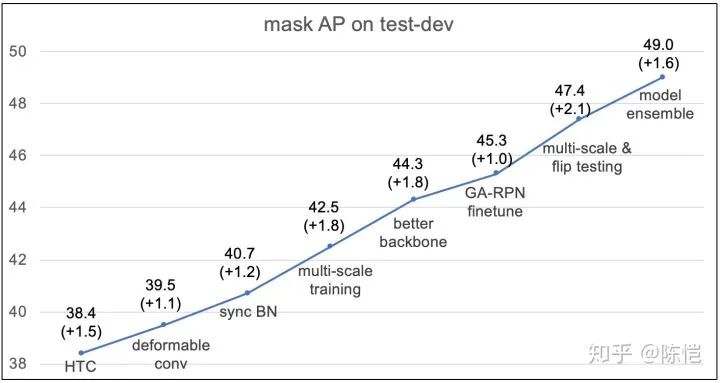
除了纯净版 HTC 之外,在 paper 里我们还给出了在 COCO Challenge 里面用到的所有步骤和技巧的涨点情况(良心买卖有木有)。
总结
多任务多阶段的混合级联结构
训练时每个 stage 内 box 和 mask 分支采用交替执行
在不同 stage 的 mask 分支之间引入直接的信息流
语义分割的特征和原始的 box/mask 分支融合,增强 spatial context
Code
已经 release 到 mmdetection:
https://github.com/open-mmlab/mmdetection
Arxiv
https://arxiv.org/abs/1901.07518
如果你打算转行CV,或者你已经有一定基础想要挑战高薪,可以看下七月在线【CV就业小班 第六期】课程,可以保证就业!
此课程在教学模式、实战项目、讲师团队、就业服务,在国内都是非常领先的,还专门为学员提供一年的GPU云平台使用。

六大实战项目


专家级讲师阵容
往期学员就业薪资
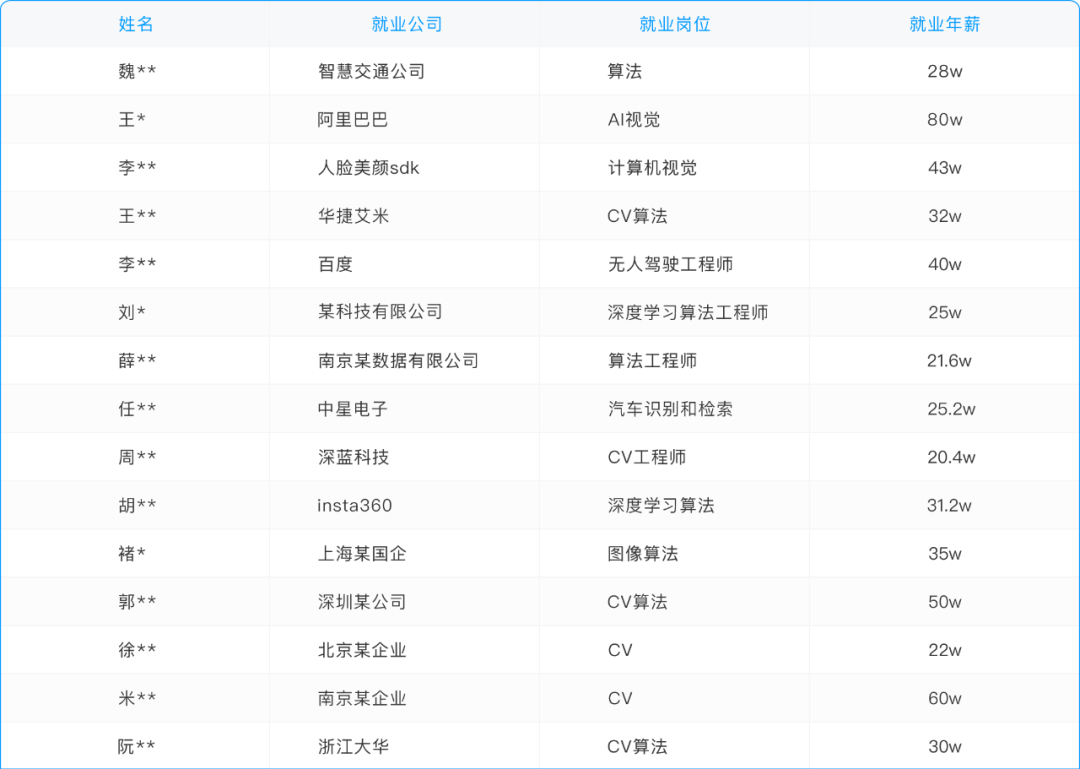
(篇幅有限,只节选部分)
扫码查看课程详情,同时大家也可以去看看之前学员的面试经验分享。
戳↓↓“阅读原文”和老师申请优惠!