
当我们谈论生信的时候我们在谈什么
生物信息学习的正确姿势
NGS系列文章包括NGS基础、高颜值在线绘图和分析、转录组分析 (Nature重磅综述|关于RNA-seq你想知道的全在这)、ChIP-seq分析 (ChIP-seq基本分析流程)、单细胞测序分析 (重磅综述:三万字长文读懂单细胞RNA测序分析的最佳实践教程)、DNA甲基化分析、重测序分析、GEO数据挖掘(典型医学设计实验GEO数据分析 (step-by-step))、批次效应处理等内容。
作为进化研究的重要手段,生物信息学担当了越来越重要的作用。作为一个极难进行实验重复和验证的学科,只能尝试根据现有的东西推断上百万及千万年前的历史。同时,生物信息学依然受到很多的质疑,且不为很多生物研究者所理解。这也是由于其是新兴的交叉学科(统计学,计算机科学与生物学)的特性所决定的。
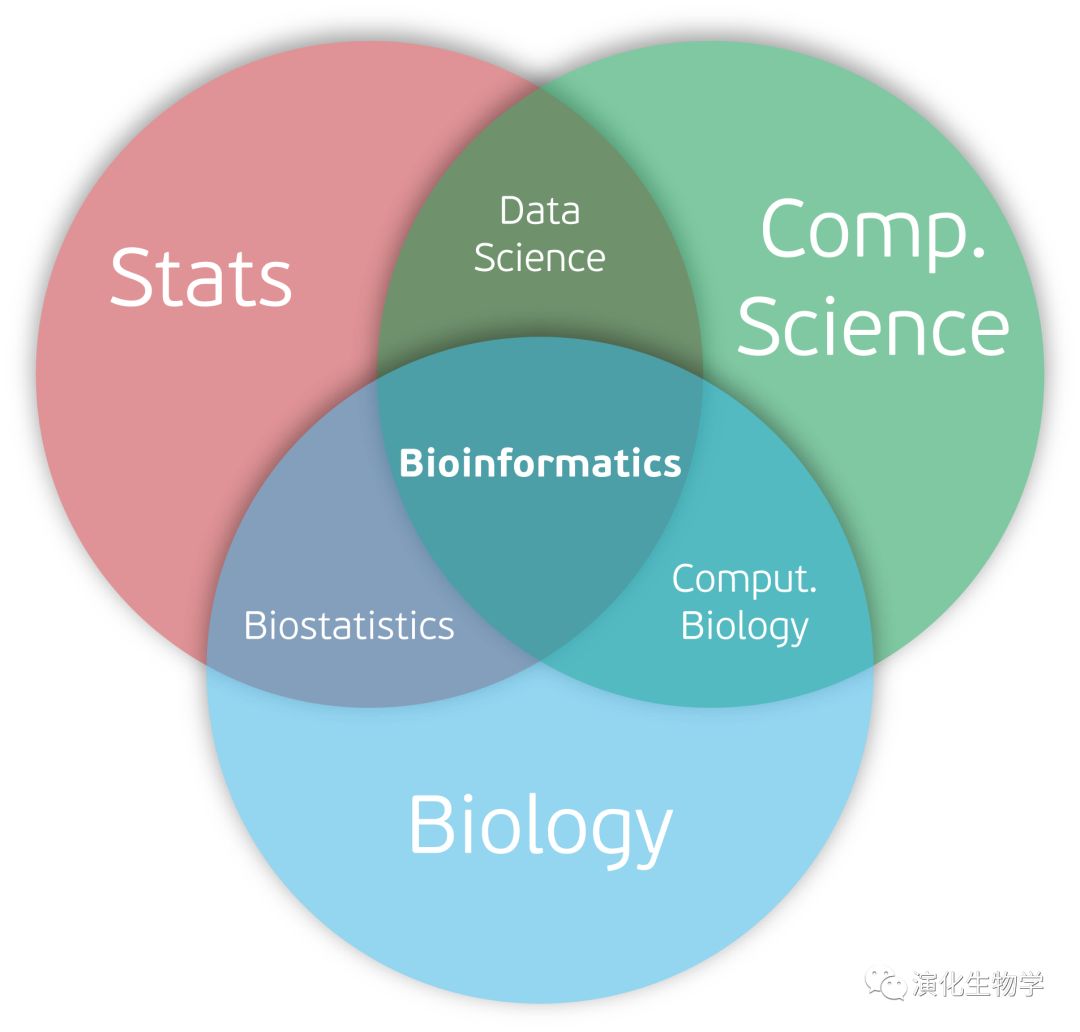
本片短文总结以下:我们应该如何认识生信,如何了解自己的定位,以及最关键,如何在茫茫生信海中找到出路。
@一些对生物信息学常见的误解:
“你们搞分类的,搞分子的,搞生信的…”
虽然生物信息学听起来确实有那么点点酷。可事实上,并不是进行生物信息分析工作的人,都喜欢被别人尊称为“搞生信的”。例如,分类学工作也会借助一代、二代甚至三代测序提供的分子标记来进行系统发育树的构建。

达尔文绘制的系统树 现在该工作基本由计算机完成
纯粹的湿实验研究,亦可使用生物信息学手段辅助进行引物的构建,序列的预测,或者通过多组学的手段来缩小的基因筛选目标,以降低对应项目的时间成本。实际上,不论是“搞”什么,对应的都应该是一种方向的知识,而知识是用来达成目标,也就是解决生物学问题的。“搞分类”指对特定类群的系统以及形态特性的掌握、“搞分子”指关注更微观层面、以及使用湿实验手段的人群、而“搞生信”指的是工作在个人电脑或服务器上完成的生物分析。
对于生物学问题的解决,不同的能力可以共同使用,只是侧重点稍有不同。所以我们平时理解的生物信息学,和其本身的含义不同,在解决具体的生物问题上,应该是作为一种工具。
“开局一篇测序报告,输出全靠扯”
有的小伙伴认为,进行生物信息学相关生物学课题的研究,是很简单的,博士几年,什么实验没做,入学三个月就有数据,直接分析就行了,太轻松了吧?事实并非如此,拿到数据之后,工作才刚刚开始:抛开都需要的文献和解读工作不谈,拿到数据的第一步需要对数据进行质量的评估,这个过程就需要上机器了。一篇文章或者一个项目,会有很多个研究和分析的点,首先需要层层击破。例如拿到一个物种的基因组数据,在解答具体生物学问题前,一般需要检测是否存在全基因组复制(WGD, Whole Genome Duplication)事件,计算自身同义替换率之前,需要找出同一次复制事件产生的基因对。但聚类后得到的家族成员少则几个多则几十,如何界定谁和谁是一对则需要设计分析方法。当然,这部分可以砸钱让公司跑流程,但实际上不同物种差别很大,流程经常会出现各种各样看不出来的Bug,这方面也已经有太多的实例。例如本身生活在特殊生境下,进化速率很快的物种,其Ks峰可能会受到稀释,只能通过共线性区段的分析寻找踪迹,这些工作公司可是无法帮你完成的。
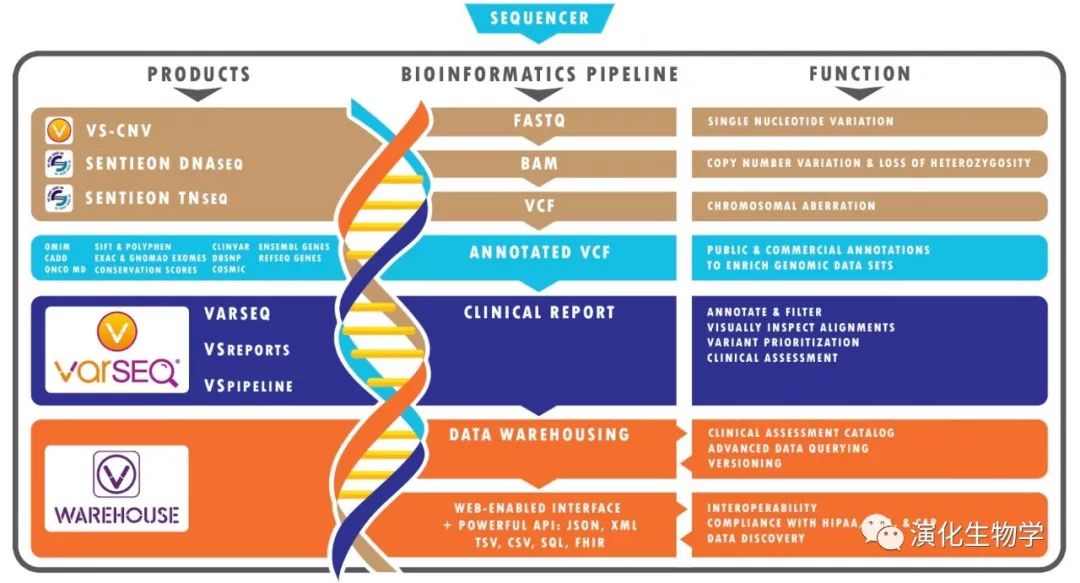
拿到数据后 复杂的分析流程才刚刚开始
“除了测序费,基本无开销”
绝对不是!首先测序费本身就是很大的一笔经费。虽然说测序费用越来越便宜,但这也代表着解决同一个生物学问题,使用同样的经费,能产出的数据越来越多,对结果的要求就越来越准确,杂志的同行审议也会越来越严格。其次是服务器集群,一个合格的具备生物信息分析能力的课题组,机器是不可少的。少则大几万十几万,多则上百万不封顶,每年的电费也是以万十万计算的。即使租借,每个月也是一笔不小的开销。另外,大部分自己有服务器集群的组,都需要有专人进行维护和管理,管理的人工费也不低。

以数据公开和接受为主的杂志越来越多 生物学问题也变得更为重要
最后还有,咖啡咖啡咖啡!!这部分的经费很多课题组都会忽略,据我观察,之前留过较顶级的生信课题组,咖啡的饮用和购买量是远远高于其他课题组的,一个是生信人,除了会把更多的时间花在电脑前靠喝咖啡缓解因出bug以后无处安放的双手外,不要忘记,每个生信人都有着程序员的魂,因为工作地点不受限制,加班熬夜是家常便饭。

一天四杯胶囊咖啡是家常便饭
@生信人的分类:
根据一些年的经验,身边做生信的人大致可以分为三类:
法师型选手
生物学出身,需要使用生信解决问题的人。常见于高校或研究机构的老师和学生。了解生物学基础问题,但对生信分析手段的了解程度参差不齐:
初级生信学者,指自己的研究课题需要使用到生物信息学的手段,这类小伙伴的生物信息工作主要由其他熟悉生信的人或者生物公司完成,并需要将结果转换为熟悉的生物学语言,方能完成论文及项目;
中级生信学者:自己能够进行基本的分析,例如序列比对,系统发育树的构建等等,并能使用一下在线工具和平台完成基础的分析,完善自己的论文工作,更为复杂的分析则由其他小伙伴或生物公司完成;
高级生信学者:在熟悉生物学基础的情况下,了解大部分生信软件的使用,并能够构建基础的流程,根据挖掘出来的生物学问题,进行生信分析策略的调整,这类小伙伴能够和公司互补,以促进项目的完成。

战士型选手
计算机、统计、数学等专业背景,后转入生物信息。随后进行生物知识的补充,根据自己的发展目标可以分为两类:
1)着重流程的构建和分析项目的完成,有基础的生物学知识,不过多关注生物学问题。这类生信人常见于生物公司的技术人员。他们的目标是能够高效的完成工作,他们和了解生物学问题的老师或同事一起可以释放出强大的能量。
2)随着对生信的接触,开始熟悉生物学知识并开始产生浓厚兴趣,对他们来说,这些生物学问题是他们应用所学知识的特定场景,力求根据场景的需要构建合适的流程。
大贤者
无所谓何种背景,左可入硅实验,右可入湿实验,看起来什么都懂,并能融汇贯通。对于这类人而言,生物学和计算机科学和其他学科一样,对于他们都是一种知识,可以说是前两种类型的综合体。他们的目标是为了解决对应的项目或生物学问题,生物信息学只是和PCR,电泳一样的普通实验手法,为达到目标用一用就好了。大贤者成为了实验室的PI,则绝对是冲锋型的老板。
大魔导师
对算法问题近乎饥渴和疯狂,着迷于方法学不可自拔,是生物信息学发展基础的推动力之一。他们不关注大的生物学问题,仅在意特定软件所解决的生物学场景,不断的优化算法,力求达到百密无一疏,以及高速运行的目标。大量魔导师混迹于一个叫做GitHub的网站,并经常互相斗法以交流法术研发心得。

???
无欲无求,进行生信研究纯粹是为了满足自身的爱好和好奇心,和自己的课题目标不一定相关,经常不小心做一些“支线任务”。但他们对生物学问题和计算机问题的衔接有自己独到的见解,经常做出一些骚操作。甚至会使用生物信息学手段来解决一些社会学问题。

@如何关爱身边的生信小伙伴:
1. 看他整日坐在电脑前,不参加课题组其他的工作,千万不要觉得他在偷懒。他可能正在非常煎熬的应对某个问题,甚至可以给他一点鼓励,因为他真的会很担心别人觉得他偷懒。
2 让他帮忙之前先问清楚他可能需要的时间,是否会耽误他手头的工作。因为看似简单的一项工作,他有时就要为此熬几个晚上:例如“随便跑个树就行”或“随便算个分子钟就行”。正是因为他很在意你,所以会去阅读很多文献并改善流程才能完成这些“简单的任务”,单纯的下载数据也都会花费很多时间。
3 看到他在咖啡厅玩电脑,或者在办公室看不到他人的时候,也不要觉得他是在偷懒。只要有一台电脑和wifi,所有地方都是他的办公室!

@生信汪末日自救指南:
面临井喷一样的数据,应该如何生存?
1. 明确定位:了解自己打C位还是辅助,决定了装备的选择。而确定自己想达到的水平,是很重要的。时间有限,初学者往往在没有任何基础的情况下翻出一本厚厚的某版生物信息学一读几小时,离开后还是“abandon”。如果还有很多繁重的湿实验需要进行,不如直接和生物公司的技术多多交流,必要的时候在一些在线平台做一些分析,可能比从某些教材一开始的贝叶斯或者似然法的公式看起来要简单许多,也更有成效。

2. 学会利用文献资料:虽然说生物信息学发展很快,每天都有新的软件和解决问题的流程出现,但还有有很多套路的。了解自己的课题,找到同样解决类似问题的文献,以模仿其材料与方法部分进行生物信息分析的重复,这不仅仅知道别人解决这个问题都使用的软件,也会了解不同软件能够完成什么工作,帮助作者论证什么问题。
《CELL》上的文章会把文章用到的软件列举出来
3. 程序语言学习要解决具体问题:生信选手到了进阶的过程,都需要学习一些简单的编程语言,例如perl、python和R。如果需要长时间进行生信工作,学习语言是很有必要的且节约时间的,简单的掌握部分语句能够帮助你修改文件格式,搭建简单的流程,以及找到别人脚本中的错误。但时间有限的情况下,请直接以生信场景为基础进行脚本的撰写练习 (生信宝典的教程都是这样面向生信的应用的)。这比完成教材后面一些计算时间,放100个小球取几个的概率等问题要好的多,也容易记下来。例如使用perl编写一个根据位置提取fasta中序列的脚本,简单容易,还能够很有成就感,学完后甚至可以直接使用。

4. 不要不舍得花钱:如果有想上手生信的决心,还是应该花点钱参加培训或购买网络课程,毕竟一个课题组购买到的资料都是可以共享学习的。虽然一些转发或者付10块钱拿到成吨的文件夹的资料,看似也非常有价值,但一般都已经是一些上古资料,以及常见软件的说明书(也可能是我运气不好)。生信分析手法的更新是很快的,一定要日新月异,毕竟参加培训班或网络课程一步一步操作,比纯粹看资料摸索更容易激活大脑。另外,导师或者课题组的PI也应该让比较有潜力的学生或者课题组的人员参加生信的培训,毕竟几千块的培训,今后仅仅在测序报告上找到一个不妥的地方,可能就能够省下几千甚至上万元。
今天就总结到这,希望对正在学习生物信息学,以及看到身边有同学同事学习生物信息学的朋友有帮助。更新得再快的学科也会有自身的套路,快准狠的解决问题才是使用生信的不二之选。
教程合集
生信宝典-Linux教程.pdf (微信公众号后台回复 生信宝典福利第一波)
生信宝典Py3_course.pdf
生信宝典-R学习教程.pdf
系列教程
高颜值免费在线绘图
往期精品
后台回复“生信宝典福利第一波”获取教程合集