
Hive进阶—抽样的各种玩法
抽样
抽样在Hive 中也是比较常用的一种手段,主要用在下面的几个场景中
一些机器学习的场景中,数仓作为数据的提供方提供样本数据
数据的计算结果异常或者是指标异常,这个时候如果我们往往需要确认数据源的数据是否本身就有异常
SQL的性能有问题的时候我们也会使用抽样的方法区查看数据,然后进行SQL调优
在大规模数据量的数据分析及建模任务中,往往针对全量数据进行挖掘分析时会十分耗时和占用集群资源,因此一般情况下只需要抽取一小部分数据进行分析及建模操作。
随机抽样(rand()函数)
我们一般情况下是使用排序函数和rand() 函数来完成随机抽样,limit关键字限制抽样返回的数据,不同之处再有我们使用哪个排序函数呢
利用 rand() 函数进行抽取,这是因为rand() 返回一个0到1之间double 类型的随机值。
下面我们用到了前面我们使用过的一张表大概4603089 条记录,这里我就不给大家准备数据了,大家可以看Hive进阶之数据存储格式来获取测试数据
create table ods_user_bucket_log(
id int,
name string,
city string,
phone string,
acctime string)
CLUSTERED BY (`id` ) INTO 5 BUCKETS
row format delimited fields terminated by '\t'
stored as textfile;
insert overwrite table ods_user_bucket_log select * from ods_user_log;
order by rand()
order by只会启用一个reduce所以比较耗时,至于为什么我们在前面的文章中解释过了Hive语法之常见排序方式
因为order by 是全局的,所以可以做到随机抽样的目的
select * from ods_user_bucket_log order by rand() limit 10;
sort by rand()
sort by 提供了单个 reducer 内的排序功能,但不保证整体有序,这个时候其实不能做到真正的随机的,因为此时的随机是针对分区去的,所以如果我们可以通过控制进入每个分区的数据也是随机的话,那我们就可以做到随机了
select * from ods_user_bucket_log sort by rand() limit 10;
distribute by rand() sort by rand()
rand函数前的distribute和sort关键字可以保证数据在mapper和reducer阶段是随机分布的,这个时候我们也能做到真正的随机,前面我们也介绍过cluster by 其实基本上是和distribute by sort by 等价的
select * from ods_user_bucket_log distribute by rand() sort by rand() limit 10;
cluster by rand()
cluster by 的功能是 distribute by 和 sort by 的功能相结合,distribute by rand() sort by rand() 进行了两次随机,cluster by rand() 仅一次随机,所以速度上会比上一种方法快
select * from ods_user_bucket_log cluster by rand() limit 10;
tablesample()抽样函数
分桶抽样(桶表抽样)
hive中分桶其实就是根据某一个字段Hash取模,放入指定数据的桶中,比如将表table按照ID分成100个桶,其算法是hash(id) % 100,这样,hash(id) % 100 = 0的数据被放到第一个桶中,hash(id) % 100 = 1的记录被放到第二个桶中。
分桶抽样语法:
TABLESAMPLE (BUCKET x OUT OF y [ON colname])
其中x是要抽样的桶编号,桶编号从1开始,colname表示抽样的列(也就是按照那个字段分桶),y表示桶的数量。所以表达的意思是按照colname字段分成y桶,抽取其中的第x桶
SELECT
*
FROM
ods_user_bucket_log
TABLESAMPLE (BUCKET 1 OUT OF 100000 ON rand()) ;

数据块抽样
从 Hive 0.8 开始提供块抽样,使用 tablesample 抽取指定的 行数/比例/大小
SELECT * FROM ods_user_data TABLESAMPLE(1000 ROWS);
SELECT * FROM ods_user_data TABLESAMPLE (20 PERCENT);
SELECT * FROM ods_user_data TABLESAMPLE(1M);
按比例抽样 ABLESAMPLE (20 PERCENT)
这将允许 Hive 至少获取 n%的数据
SELECT
*
FROM
ods_user_bucket_log
TABLESAMPLE(0.0001 PERCENT);

抽取特定大小的数据TABLESAMPLE(100M)
SELECT
*
FROM
ods_user_bucket_log
TABLESAMPLE(1M);

需要注意的是这里必须是整数M ,以为我尝试零点几的时候报错了

抽取特定的行数 TABLESAMPLE(10 ROWS)
SELECT
*
FROM
ods_user_bucket_log
TABLESAMPLE(10 rows);

扩展
随机抽样如何实现按比例抽样
前面我们介绍了TABLESAMPLE 可以实现按比例抽样,随机抽样可以借助limit 可以实现抽取特定记录数,其实我们如果对随机抽样进行改进也可以实现按照比例抽样,因为rand() 的函数值是随机的,所以我们可以对其返回值做条件过滤从而实现按照比例的抽样
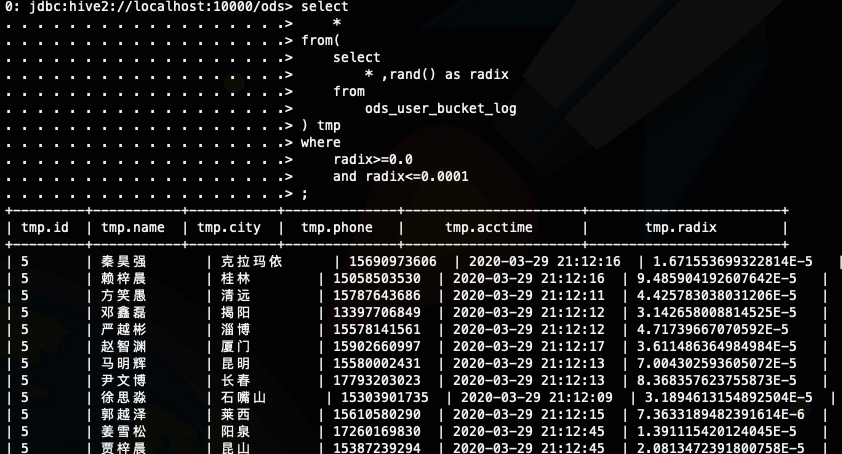
select
*
from(
select
* ,rand() as radix
from
ods_user_bucket_log
) tmp
where
radix>=0.0
and radix<=0.0001
;
分层抽样(分组抽样)
分层抽样,这里可以分为两种,一种是分层抽个数另外一种是分层抽比例
分层抽个数
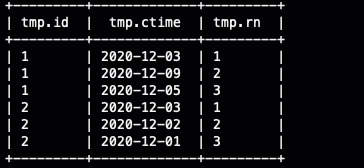
select
*
from (
select
id,ctime,
row_number() over(partition by id order by rand() ) as rn
from
ods_user_log
) tmp
where rn<=3
;
分层按比例的抽样,也可以按照上面的方式实现
总结
TABLESAMPLE 抽样函数本身是不走MR 的所以执行速度很快(注意抽取多少M的时候,只能是整数M)
随机抽样函数需要走MR的,所以执行性能上没有TABLESAMPLE那么快,而且表达能力有限,只能获取特定的条数(limit n)
借助row_number实现分层抽样