
Hive小知识之分桶抽样
点击上方蓝色字体,选择“设为星标”




先把大家都知道的分桶抽样查询 的语法以及用法po出
select * from 分桶表 tablesample(bucket x out of y on 分桶字段);假设当前分桶表,一共分了z桶!
x: 代表从当前的第几桶开始抽样
0 y: z/y 代表一共抽多少桶! y必须是z的因子或倍数! 怎么抽:从第x桶开始抽,当y<=z每间隔y桶抽一桶,直到抽满 z/y桶 举例1: 从第1桶开始抽,每间隔2桶抽一桶,一共抽2桶! 桶号:x+y*(n-1) 抽0号桶和2号桶 举例2: 从第1桶开始抽,每间隔1桶抽一桶,一共抽4桶! 抽0,1,2,3号桶 举例3: 从第2桶开始抽,一共抽0.5桶! 抽1号桶的一半 然而,当我自己实验时,发现实际情况跟预期有偏差 建表语句: 数据:分好的桶如下 然而查询时却发现 本来打算取第2个桶里的4/8 数据,但返回的数据跟预期差得很多 其实 select * from 分桶表 tablesample(bucket x out of y on 分桶字段); 文章不错?点个【在看】吧! ?select * from stu_buck2 tablesample(bucket 1 out of 2 on id);select * from stu_buck2 tablesample(bucket 1 out of 1 on id);select * from stu_buck2 tablesample(bucket 2 out of 8 on id);--创建分桶表create table people (id int,name string)clustered by (id)sorted by (name desc) into 4 bucketsrow format delimited fields terminated by '\t';--创建临时表create table tmp (id int,name string)row format delimited fields terminated by '\t';--加载数据load data local inpath '/home/guigu/data.txt' into table tmp;--加载数据到分桶表insert overwrite table people select * from tmp;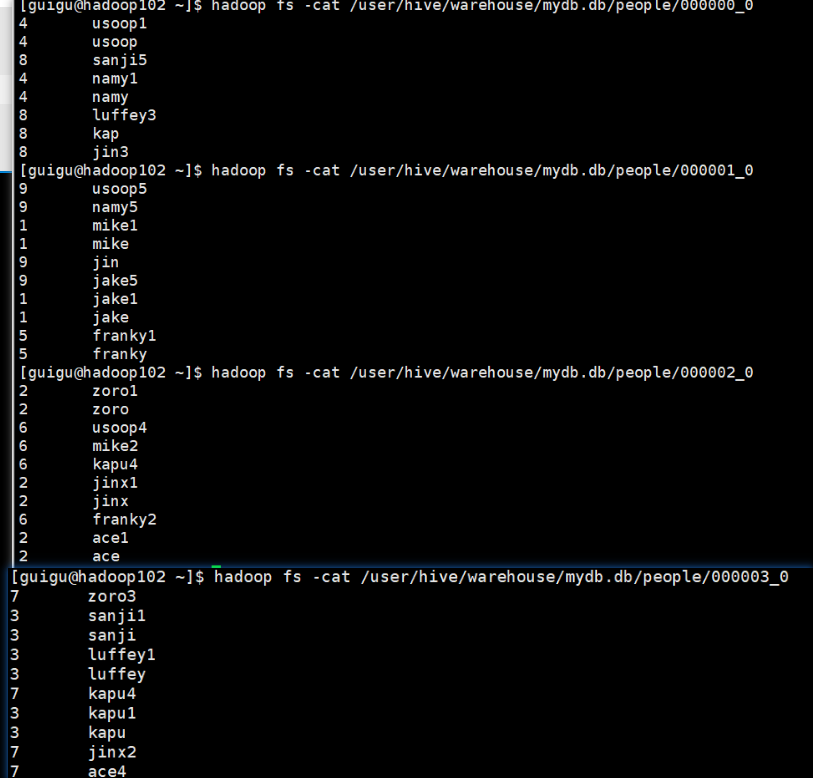
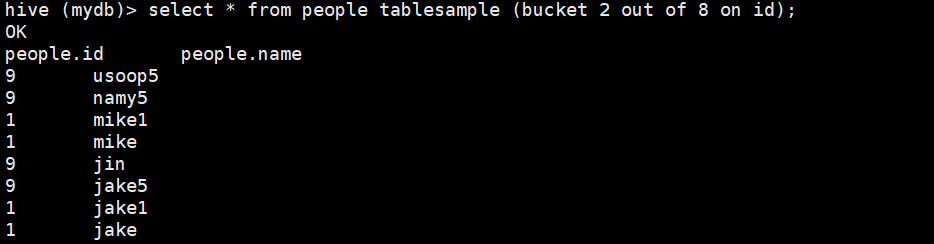
这个抽样查询的底层是把所有数据按照 字段的hash值 % y 分成y 个 区(相当于Hadoop里的分区),然后取第 x 区 中的数据。
之所以没有达到预期的效果,是因为用来测试的数据太少!