
在线调查的抽样方法及注意事项
文章来源:东石笔记
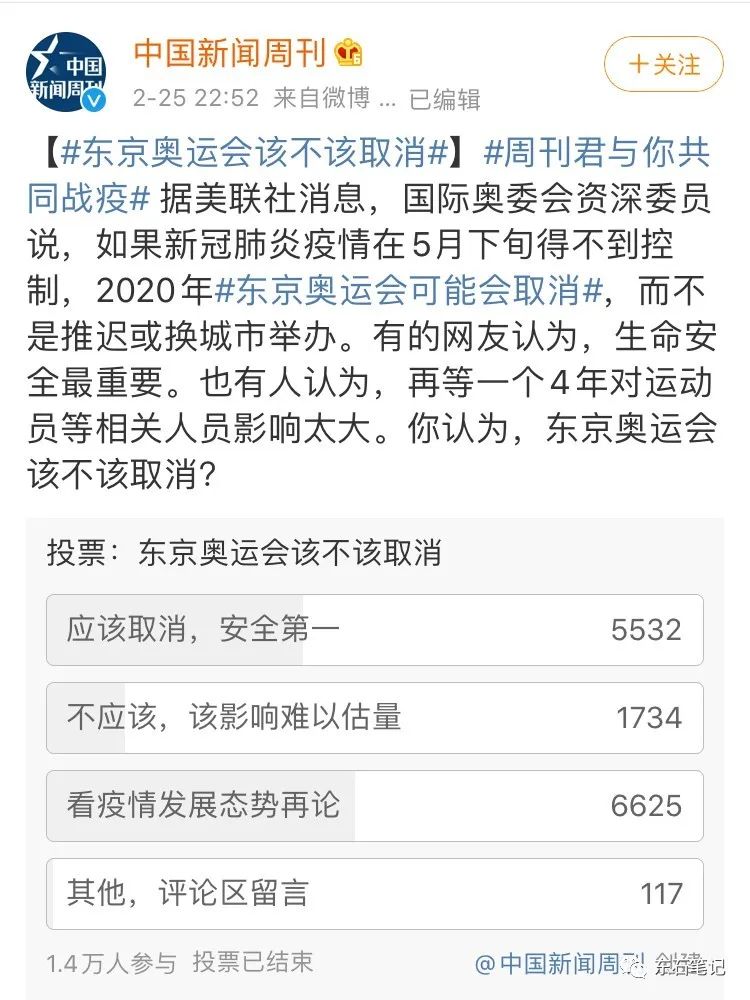
“不做调查没有发言权。不做正确的调查同样没有发言权。” 在万物互联的时代,如何运用互联网和其他信息技术进行调查才能更好的支撑决策,避免对决策的误导?
生活中会遇到各种在线调查问卷和结果。比如,看到上面这样一则再常见不过的微博投票,该如何去认识和解读它?
对于一些学科的同学和研究者来说,在应对新冠疫情的特殊时期,做在线调查可能成为一个更方便可行的数据收集渠道。
在线调查可以降低成本,方便数据的获取;同时,为了更准确的实现调查的目标、增强样本对总体的代表性,也需要更细致的了解在线调查的不同抽样方法和注意事项。
这里陆续摘录、推出弗吉尼亚理工大学统计学系教授Ronald D. Fricker, Jr.《在线调查的抽样方法》一文,今天先翻译和推出一些预备内容。
1936年,《文学文摘》(The Literary Digest)杂志进行美国总统大选的民调。杂志根据电话号码本和机动车登记表组成了一个抽样框。虽然在今天使用电话号码可能会产生相当有代表性的人口样本,但在1936年,只有四分之一的家庭拥有电话,而它们一般都是更富裕的家庭。使用汽车登记表使抽样框更加偏向高收入个体。
《文学文摘》寄出1000万张民调选票,其中230万张被退回,退回比例很高,而答复率不到25%。根据民调数据,《文学文摘》预测,艾尔弗·兰登将击败富兰克林·罗斯福(预测得票率55% vs. 41%)。实际上,罗斯福以61%的得票率击败兰登(37%)。这是有史以来主要民调的最大失误,可能也是1938年《文学文摘》倒闭的原因之一。
抽样是指从一个较大的总体(研究对象的全部)中选择要调查的子集(样本)。本文重点介绍网页和电子邮件调查的抽样方法,这些方法统称为“在线”调查。在使用互联网之前,大型调查的管理成本通常很高,因此专业调查人员会仔细考虑如何最好地进行调查,以在最大程度地降低成本的同时最大化信息的准确性。但是,互联网现在可以轻松访问大量的无忧调查软件和数以百万计的潜在调查对象,并且降低了其他成本和调查障碍。尽管这对调查研究人员来说是个好消息,但这些相同的因素也促进了不良调查研究方法的泛滥。
图 关于抽样。如果不可能或无法直接观测总体的统计数据,则可以使用从总体中适当抽取的样本数据推断出有关总体的信息。(来源:Fricker Jr., 2016)
例如,在线调查数据收集的边际成本实际上可以为零。乍一看,这十分具有吸引力,似乎可以尝试进行普查,或者只需对大量个体进行调查而不考虑个体是如何被选到样本中的。实际上,这些方法的确在在线调查中被频繁使用,而没有充分考虑可替代的抽样策略或此类选择对调查结果准确性的潜在影响。结果是,进行不当的“普查”和基于大规模方便样本(convenience samples)的调查的泛滥,这些样本可能比进行较小样本、组织良好的调查所产生的准确度更低。
与所有形式的数据收集一样,进行调查需要妥协。具体地,在可收集的数据量和所收集数据的准确性之间几乎总是要进行折衷。因此,对于研究人员来说,在选择一种用于收集数据的抽样方法时,要把握好它们或隐含或明显的优劣权衡。
从总体中抽取样本的方法有很多,抽样也有许多出错的可能。我们直观地认为一个好的样本能够代表总体。所谓“代表性”,并不一定意味着样本在可观测特征方面与总体匹配,而是从样本数据获取的结果与假如使用总体数据获取的结果一致。
调查的主要目的是收集有关总体的信息。但是,即使在进行普查的情况下,结果也可能会受到多种误差(error)来源的影响。一个好的调查设计可以减少所有类型的误差。下表列出了Groves(1989)提出和定义的调查误差的四个类别。
调查抽样可分为两大类:基于概率的抽样(也称为“随机抽样”)和非概率抽样。基于概率的样本是使用某种概率机制选择受访者的样本,并且样框总体的每个成员被抽中的概率已知。对于抽样框的每个成员,被抽中的概率不一定必须相等。
概率样本的类型包括:简单随机抽样(SRS)、分层随机抽样、整群抽样、系统抽样。
当每个个体被抽中的概率无法确定,或者个体能够选择是否参与调查时,就会出现非概率样本(有时称为方便样本,convenience samples)。对于概率样本,调查员使用某种概率机制选择样本,并且总体中的个体无法控制此过程。相反,网络调查可以简单地发布在网站上,由浏览该网站的人决定是否参加调查。顾名思义,这种非概率样本因为获取方便,因此经常被使用。
在基于概率的调查中,参与者可以选择不参加调查,而严格的调查则试图将决定不参加(即不答复)的人数降至最低。在这两种情况下,都有可能产生偏差(bias),但是在非概率调查中,偏差的可能性更大,因为选择加入的个体可能无法代表总体。此外,在非概率调查中,通常没有办法评估偏差的大小,因为通常没有关于选择不参加的个体的信息。
一般来说,获取非概率样本耗费的时间和精力更少,因此生成成本更低,但它们通常不能支撑正式的统计推断。但是,非概率样本可能对研究有其他方面的帮助。例如,在研究的早期阶段,采集方便样本(convenience samples)对提出假设、识别问题、定义替代方案的范围或收集其他种类的非推断数据可能有用。有关将各种基于非概率的抽样方法应用于定性研究的详细讨论,请参见Patton(2002)。
非概率样本的类型如下:
配额抽样要求调查研究人员依据受访者的特定特征分配采样数额。对受访者的实际选择权交给了调查访问员(interviewers),由他们来完成配额。细微的偏差可能会由此渗入样本的选择中。
滚雪球抽样(受访者驱动的抽样,也译作裙带抽样、推荐抽样)。当具有所需特征的样本个体非常稀少,以至于通过其他方式(如简单随机抽样)定位到足够多的受访者非常困难或昂贵时,常采用滚雪球抽样。它依赖于最初受访者的推荐,以产生更多的受访者。尽管此技术可以大大降低搜索成本,但以引入偏差作为代价,该技术本身会大大增加样本无法代表总体的可能性。
判断抽样(也译作立意抽样)是一种方便抽样,研究人员根据自己的判断选择样本。例如,即使所推断的总体包括所有互联网用户,研究人员可能会决定只从一个“代表性”的互联网用户社群抽取整个随机样本。判断抽样还可以以结构更简单的方式进行应用,而无需应用任何随机抽样。
如果样本在某种程度上不能从系统上代表所推断的总体,那么所得到的分析可能会产生偏差。例如,对互联网用户进行的有关电脑使用情况的调查结果不可能准确量化一般人群的电脑使用情况,因为样本仅由使用电脑的人组成。此外,应当认识到,采集更大的样本并不能自然而然的纠正偏差,大样本也不能证明偏差就小。例如,不管调查了多少互联网用户,根据互联网用户样本所估计的电脑平均使用率都很可能会高估总体人口的平均使用率。
随机化是指从感兴趣的总体中随机选择受访者,该方法可最大程度地减少偏差的几率。其想法是,通过从整个总体中随机选择潜在的调查对象,抽样得到的样本将很可能“看起来像”总体,即使对于那些无法观测或未知的特征。后一点值得强调,概率样本对于可观测和不可观测特征(observable and unobservable characteristics)均可降低抽样偏差的机会。
另一方面,方差只是观测数据变化的度量,可用于计算标准误差。通过概率抽样机制得出统计估计值的精度可通过增大样本量来提高,因为(在所有其他条件保持不变的情况下)更大的样本量可带来更小的标准误差。
Groves, R. M. (1989) Survey Errors and Survey Costs. New York: John Wiley.
Patton, M. Q. (2002) Qualitative Evaluation and Research Methods, London: Sage.