
量化入门系列:行业指数、主题指数、风格指数的估值温度计
本系列通过一些实例介绍量化的入门知识,适合零基础的初学者。本文的量化环境基于Python和AKShare数据接口,安装教程见文末附录。
上几篇量化入门的文章发表后,有人说对编程不熟悉,学起来觉得有难度。其实量化刚开始入门时不求甚解就行,有现成的代码先用起来,用多了自然就熟悉了。本系列文章会从简到难,从一些简单的应用开始,到具体量化策略的构建。
本篇介绍行业指数、主题指数、风格指数的估值百分位的实现。
程序运行前先要导入需要的库:
import akshare as ak # 导入AKShare数据源import pandas as pd # 导入pandas库import datetime # 导入datetime库
我们先来计算申万一级行业的估值百分位。申万一级行业有28个行业,我们可以像前几篇文章一样,每个行业的估值百分位都单独写一段代码,但还有更高效的方法,用循环语句,写一遍代码就行,不用重复写28遍。
首先,我们用 for 循环来获取28个行业的PE估值数据。
# 申万一级行业的代码和名称sw_code_list = ['801010', '801020', '801030', '801040', '801050', '801080', '801110','801120', '801130', '801140', '801150', '801160', '801170', '801180','801200', '801210', '801710', '801720', '801730', '801740', '801750','801760', '801770', '801780', '801790', '801880', '801890', '801230']sw_name_list = ['农林牧渔I', '采掘I', '化工I', '钢铁I', '有色金属I', '电子I', '家用电器I','食品饮料I', '纺织服装I', '轻工制造I', '医药生物I', '公用事业I', '交通运输I', '房地产I','商业贸易I', '休闲服务I', '建筑材料I', '建筑装饰I', '电气设备I', '国防军工I', '计算机I','传媒I', '通信I', '银行I', '非银金融I', '汽车I', '机械设备I','综合I']start_date = "2014-03-01" # 开始日期end_date = datetime.date.today() # 结束日期:今天sw_pe_df = pd.DataFrame() # 用来存放估值数据的表格for i in range(len(sw_code_list)): # 逐个获取申万一级行业的PE估值数据sw_pe_df[sw_name_list[i]] = ak.sw_index_daily_indicator(index_code=sw_code_list[i], start_date=start_date, end_date=end_date, data_type="Day").set_index('date')['pe']
sw_code_list 和 sw_name_list 是两个列表,分别存放28个申万一级行业的代码和名称。
start_date 为获取PE数据的开始日期,end_date为获取PE数据的结束日期,不同的取数接口有不同的参数要求,有的接口可以一次性取出所有数据,有的接口要输入时间段。
sw_pe_df 是一个DataFrame表格类型的变量,用来存放28个行业指数的PE值。我们用 for 循环,把28个行业遍历一遍,每个行业都通过akshare的数据接口函数 ak.sw_index_daily_indicato() 来获取历史行情数据,这个函数需要的参数有:index_code(行业代码)、start_date(开始日期)、end_date(结束日期)、data_type(日报还是周报)。取出历史行情数据后,用 .set_index('date') 把日期设为索引,然后用 ['pe'] 把PE值这一列放入 sw_pe_df 中。然后用:
print (sw_pe_df)查看 sw_pe_df 的内容:
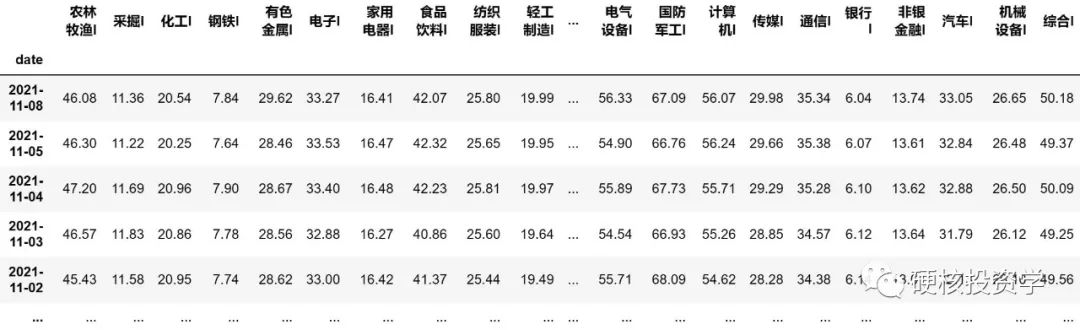
这个表格的索引(index)为日期,有28列,分别为28个一级行业。这里要注意日期是倒叙的,而我们前面的文章里取宽基指数的PE值时日期是顺序的。所以我们要经常用 print 把数据显示出来,以免计算时出错。
然后计算历史百分位并作图,将结果可视化。
sw_pe_pct = sw_pe_df.rank(axis=0, ascending=True, pct=True)*100 # 计算PE的百分位sw_pe_pct.iloc[0].sort_values(ascending=False).plot.barh(figsize=(10,10),title='申万一级行业的估值百分位') # 画图:最近一日的PE百分位
用 .rank() 函数计算历史百分位,存储到变量sw_pe_pct中,sw_pe_pct也是个DataFrame表格,用:
print (sw_pe_pct)查看其内容:
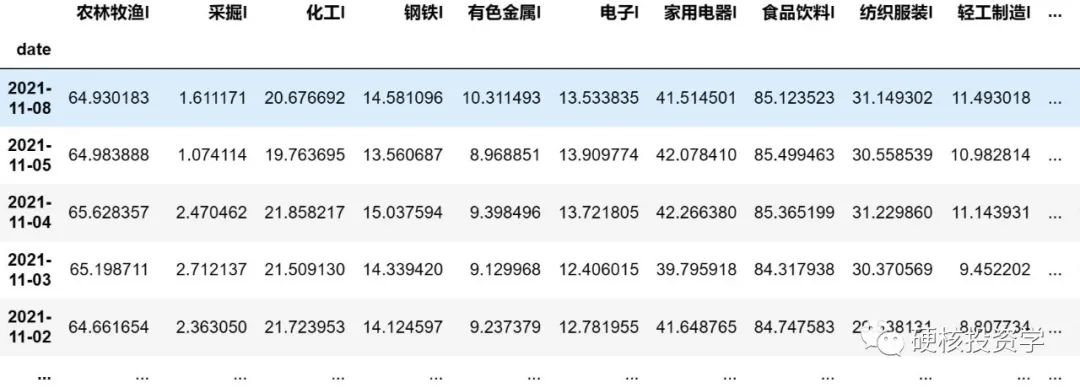
表格的索引(index)为日期,每一列为一个行业的PE估值百分位。由于日期是倒叙排列的,所以要取第一行的数据才是今天的历史百分位数。sw_pe_pct.iloc[0] 的意思就算取表格 sw_pe_pct 的第一行。注意程序计数是从 0 开始的,不是从 1 开始的,所以sw_pe_pct.iloc[0] 才是第一行,如果要取最后一行,用 sw_pe_pct.iloc[-1] 。.sort_values () 函数根据估值百分位数来对28个行业进行排序,.plot.barh () 函数是用来画横向的柱状图,如下:
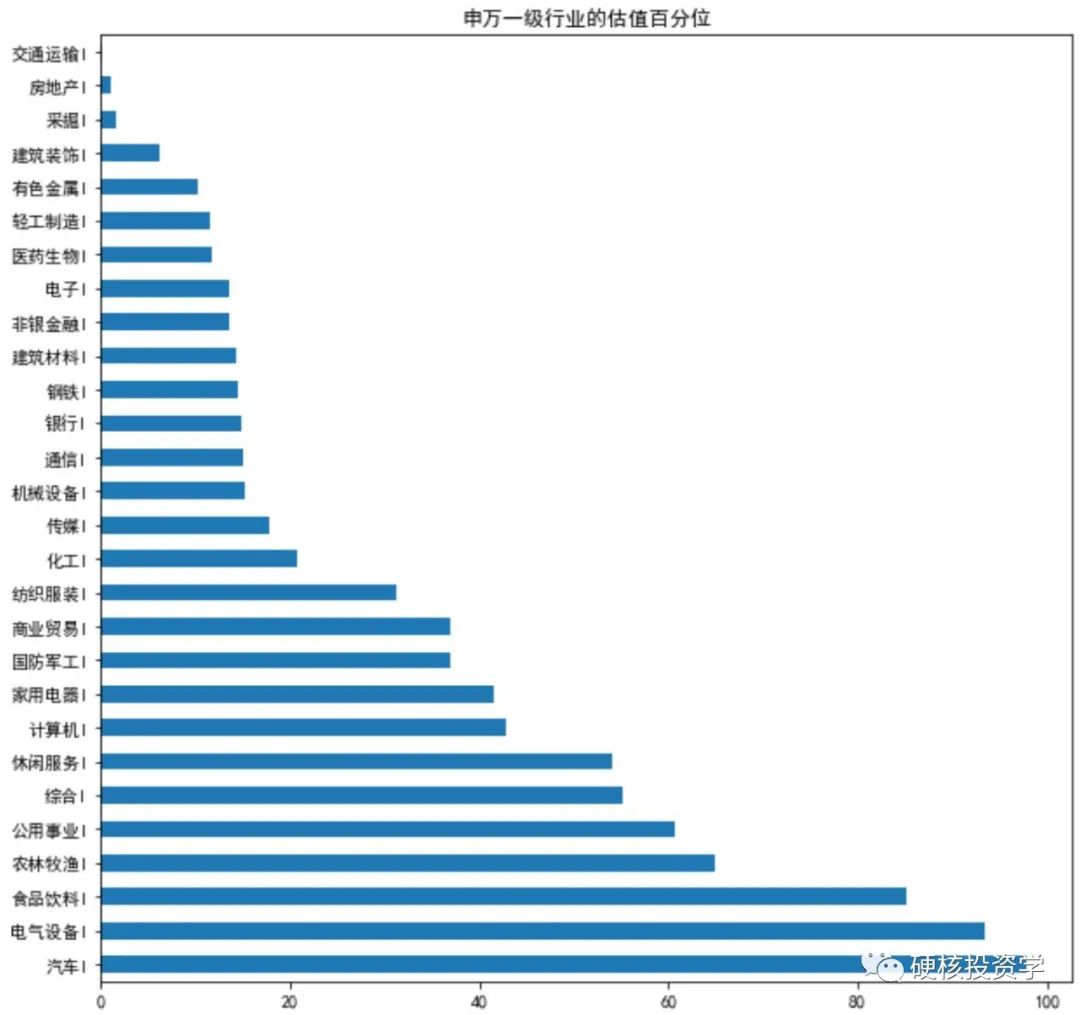
简单看一下,估值百分位最低的三个行业:
交通运输业流通市值最高的前三只股票为顺丰控股、中远海控、京沪高铁,其中顺丰控股和京沪高铁都处于跌势,中远海控在利润大增的情况下股价回调,PE都不高。
房地惨不用说了,很多老铁还套在里面。
采掘业流通市值最高的前三只股票为中国石油、中国神华、陕西煤业。采掘业是典型的周期行业,近一年多来股价涨了不少,同时利润也大幅增长,所以估值不高,但周期行业的利润实现之时也许就是周期见顶之时,风险并不小。
估值百分位最高的三个行业:
汽车行业流通市值最高的前三只股票为长城汽车、比亚迪、上汽集团,股价都在历史高位区间。
电器设备行业流通市值最高的前三只股票为宁德时代、隆基股份、亿纬锂能,都是当前新能源的当红炸子鸡。
食品饮料行业流通市值最高的前三只股票为贵州茅台、五粮液、海天味业,虽然今年股价回调,但估值仍处于比较高的位置。
再来看下主题指数、风格指数的估值。很多人在投资指数基金时会参考指数的估值,用量化的方法把程序代码编好,日后只要按下运行键结果就出来了,非常方便。主要代码跟上面是一样的,就是要换一下数据接口:
index_name_list = ['中证全指房地产','中证红利','中证银行','证券公司','中证医药','证券公司','中证国防','白酒(申万)','新能源车','中证新能源','沪深300']index_pe_df = pd.DataFrame() # 用来存放估值数据的表格for name in index_name_list: # 逐个获取指数的PE估值数据index_pe_df[name] = ak.index_value_hist_funddb(symbol=name, indicator="市盈率").set_index('日期')["市盈率"].iloc[-1250:] # 取最近1250个交易日(大概为5年)的数据index_pe_pct = index_pe_df.rank(axis=0, ascending=True, pct=True)*100 # 计算PE的百分位index_pe_pct.iloc[-1].sort_values(ascending=False).plot.barh(figsize=(10,10),grid=True,title='指数的估值百分位') # 画图:最近一日的PE百分位
指数数据接口用的是ak.index_value_hist_funddb ()函数,这个函数要求两个参数:symbol为指数名称,indicator可选'市盈率'、 '市净率'、 '股息率'。获取的各指数的PE数据存放在DataFrame表格index_pe_df中,这里用 .iloc[-1250:] 取最近1250个交易日(大概为5年)的数据来计算PE历史百分位并存放在DataFrame表格index_pe_pct中。由于取出的数据是按日期顺序排列的,所以用 index_pe_pct.iloc[-1] 取最后一行的数据即为最近日期。可视化图形如下:
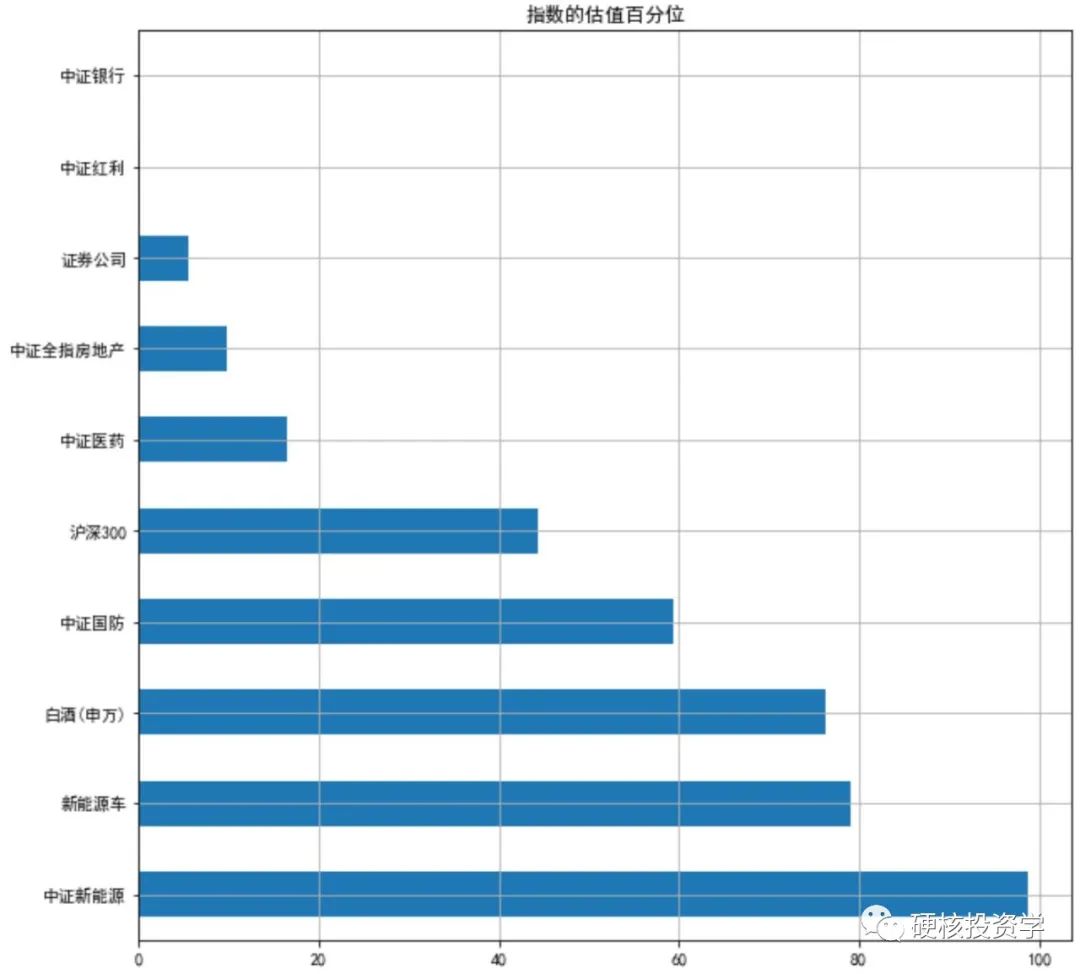
可以看到,以沪深300为比较的参考基准,最近五年中证银行、中证红利、证券公司、中证全指房地产、中证医药指数的PE估值百分位低于沪深300,而中证国防、白酒、新能源车、中证新能源指数的PE估值百分位高于沪深300。
用量化方法来计算估值百分位到此告一段落,估值百分位可以怎么用呢?接下来的文章会介绍如何做一个基金定投的量化回测框架,并用估值百分位来改进基金定投策略。
本文涉及的数据接口的参数、输出、示例的说明文档参见:
申万一级行业历史行情指标:
https://www.akshare.xyz/data/index/index.html#section-26
指数估值:
https://www.akshare.xyz/data/index/index.html#section-40
量化投资系列的文章:
1. 量化入门系列:用Anaconda和AKShare搭建免费的Python量化环境
3. 量化入门系列:沪深300、中证500、中证1000的估值百分位